Python 一键抓取海量美图,这个方法太高效了!
链接:https://zhuanlan.zhihu.com/p/1968981601372316787
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
🌈Hi,小伙伴们~
🛠️前面文章分享了如何爬取小红书的评论信息,主要聚焦在文本信息采集方面
🚀今天,我们来整点更好看的【如何爬取采集图片】将完整的从网页抓包分析→数据抓取→数据存储的全流程,小白也能轻松上车!
📋项目概述
🎯核心操作流程
🔹 ① 数据分析:分析目标网站,明确抓包对象
🔹 ② 数据采集:爬取小红书指定图片信息
🔹 ③ 数据存储:将图片保存到本地文件夹
🎯目标网站对象
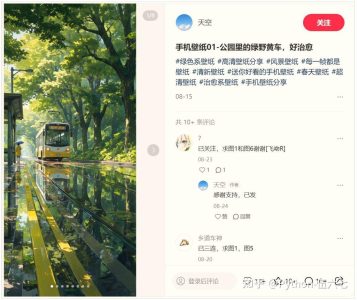
📸随意选取一个作为目标,如下所示【图片来源:小红书手机壁纸截图👇】
📸好的图片,👇求图的需求还是挺多的,学会今天分享的内容,你想要的图片随便拿
🛠️项目准备工作
📦涉及到的工具与库
🎯 爬取数据:requests/DrissionPage
📈 处理数据:re/os
🔧依赖包:在 Python 环境下,安装如下依赖:
pip install DrissionPage pandas pyecharts wordcloud jieba🕵️♂️一、抓包分析
📦 分析目标网页
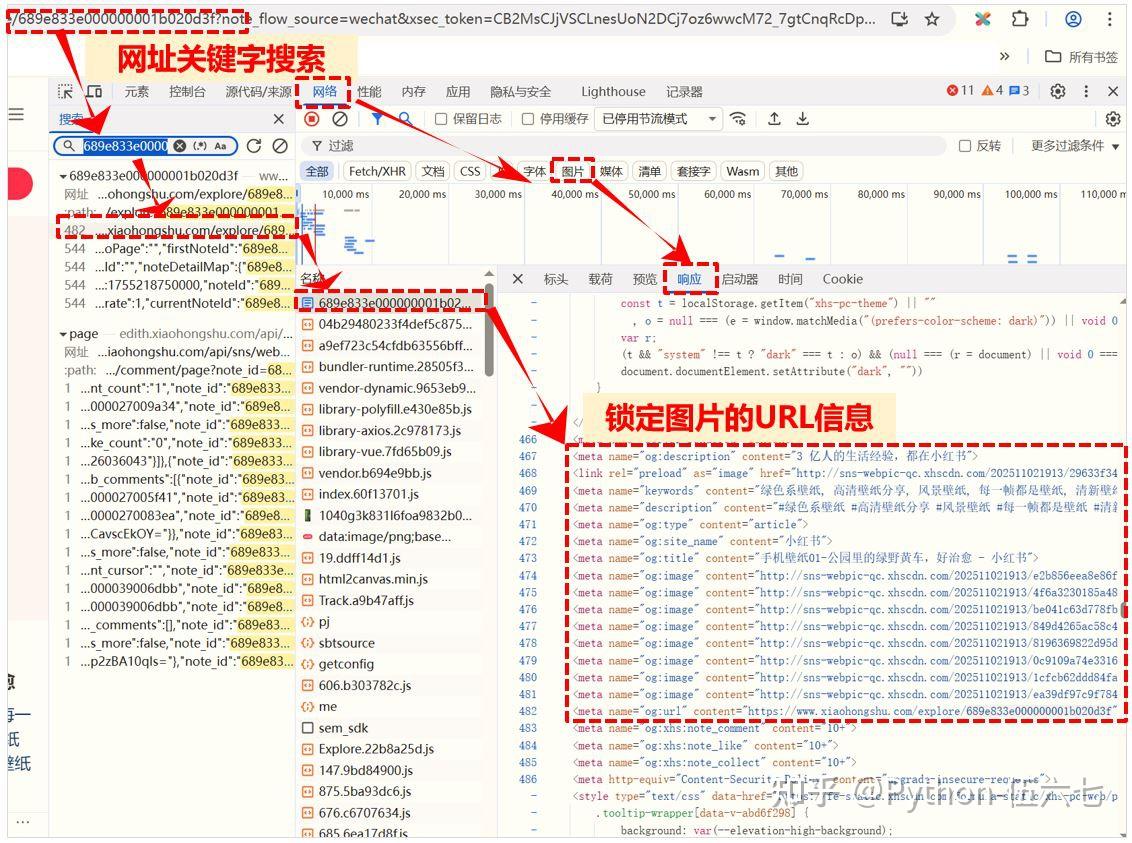
1️⃣ 在谷歌浏览器打开目标页面, 按 F12 打开开发者工具【下图:浏览器开发者工具界面⚙️】
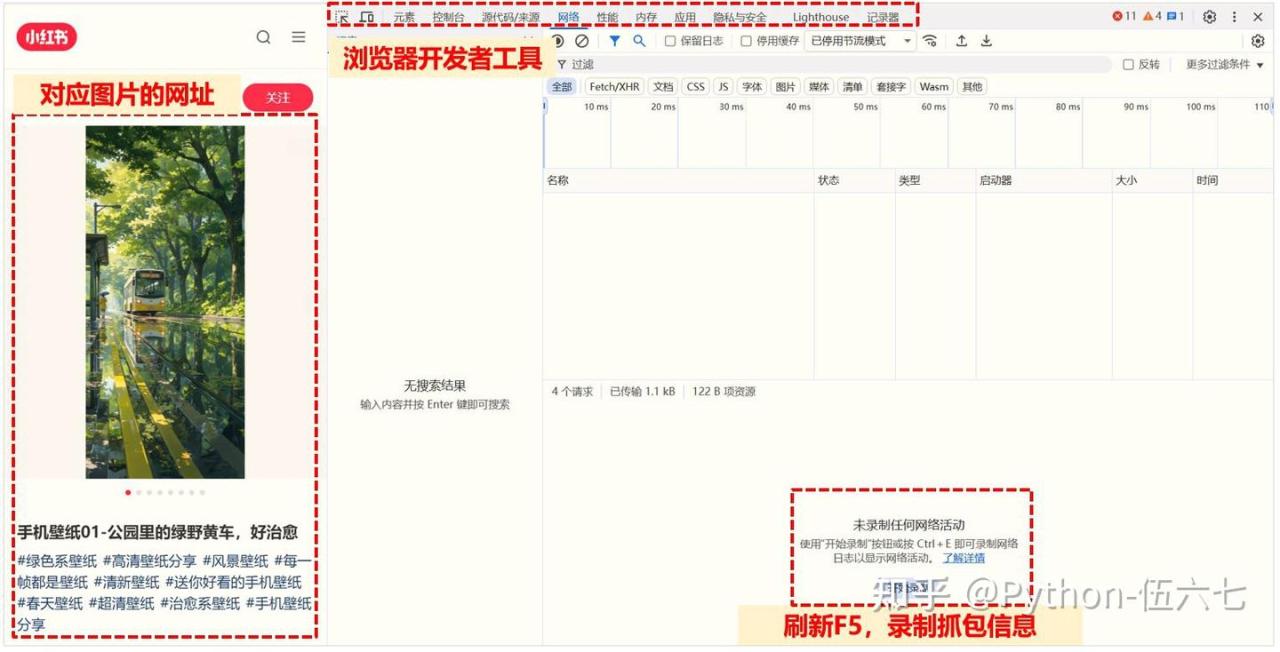
2️⃣ 刷新页面,用图片网址关键字段搜索,锁定存储图片的URL地址信息【下图:锁定数据包🔎】
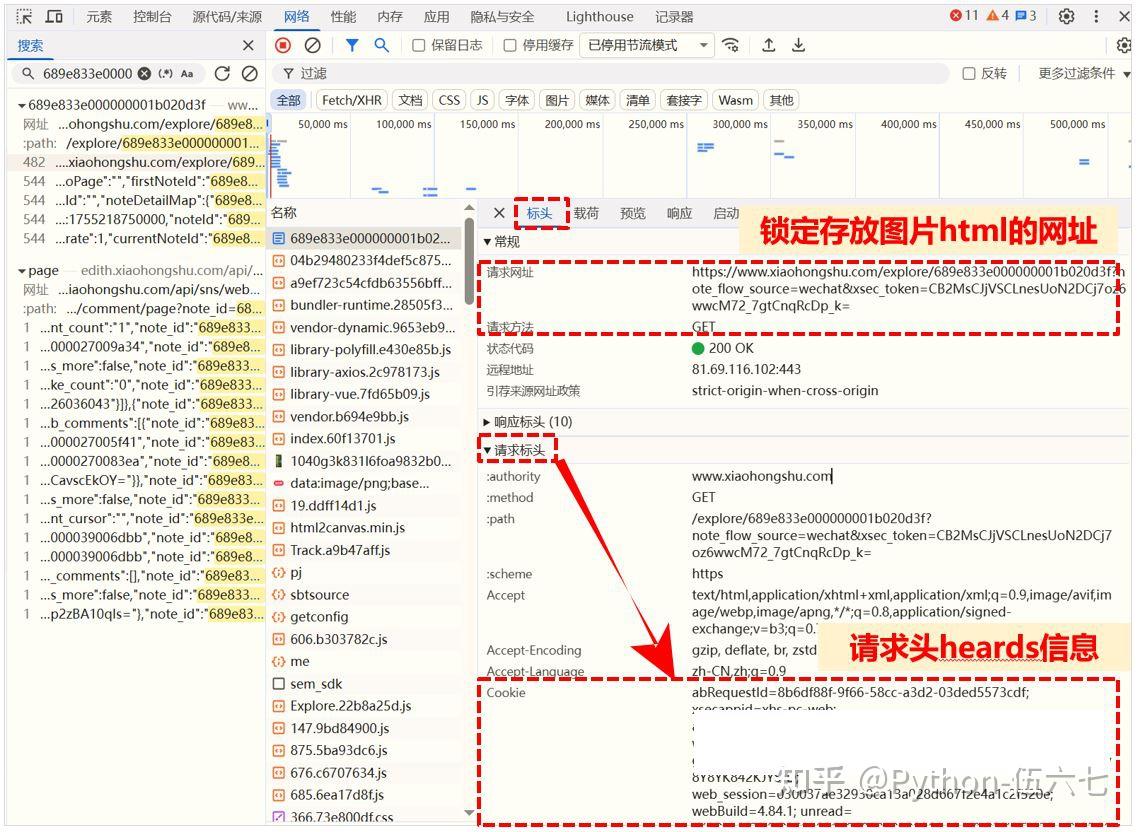
3️⃣ 分析目标对象,打开对应网址的标头,获取到对应的Cookie及User Agent信息【下图:请求标头📊】
👨💻二、实现代码详解
📝 1. 环境准备:导入必备工具库
from DrissionPage import ChromiumPage
import requests
import re
import os
# 此文件夹用于存放抓取的图片
if not os.path.exists("img2"):
os.makedirs("img2")🕷️ 2. 发起请求:模拟浏览器
# 替换为您需要抓取对象网页的URL
url = "https://www.xiaohongshu.com/explore/xxxxxx"
# 网页登录后,替换为您的cookie/UA信息
header = {
"cookie": "xxxxx",
"user-agent": "xxxxx",
}
# 发起请求,拿到返回网页的html
html = requests.get(url, headers=header).text✅备注:通过requests模拟浏览器发起访问,其中headers信息可在浏览器开发者工具中直接复制获取
🔍 3. 解析响应:拿到图片的URL地址
# 解析图片的标题
title = re.findall(r'<meta name="og:title" content="(.*?)">', html)[0]
# 清理标题中的非法文件名字符
clean_title = re.sub(r'[<>:"/\\|?*]', "", title)
# 解析图片的URL地址
image_list = re.findall(r'<meta name="og:image" content="(.*?)">',html)
num = 1
for image_path in image_list:
# 从URL中提取文件扩展名
file_extension = os.path.splitext(image_path)[1]
if not file_extension:
file_extension = ".jpg"
#再次对存放每周图片的网页发起请求
image_comtent = requests.get(image_path).content
✅备注:利用正则表达式提取HTML页面中的标题和图片网址,并对图片网址发起访问获取到图片二进制信息(此点是图片与文本的重要区别)
🗂️ 4.数据存储:存入本地文件夹
# 构建文件路径
filename = f"img/{clean_title}_{num}{file_extension}"
with open(filename, mode="wb") as f:
f.write(image_comtent)
num += 1✅备注:将图片二进制信息写入文件,注意文件名的灵活性,避免写入时被覆盖
🌍 5. 批量采集:获取每个发表用户的id/token
# 实例化一个浏览器对象
dp = ChromiumPage()
# 监听数据包液面是否加载完成
dp.listen.start("web/v1/search/notes")
# 此网页为图片汇总页/预览页
dp.get(url_2)
# 等待数据加载完成
r = dp.listen.wait()
# 获取响应json数据嵌套字典
json_data = r.response.body
items_list = json_data["data"]["items"]
for item in items_list:
id = item["id"]
xsec_token = item["xsec_token"]
url = f"https://www.xiaohongshu.com/explore/{id}?note_flow_source=wechat&xsec_token={xsec_token}"
#再嵌套上述步骤2/步骤3✅备注:批量采集的核心是利用DrissionPage获取汇总页返回数据,解析获得每个页面的详细信息,其中存放不同用户上传图片的id/token信息url_2,通过抓包分析找到的(所以抓包分析对爬取数据至关重要!)
📊三、运行效果:轻松拿到图片
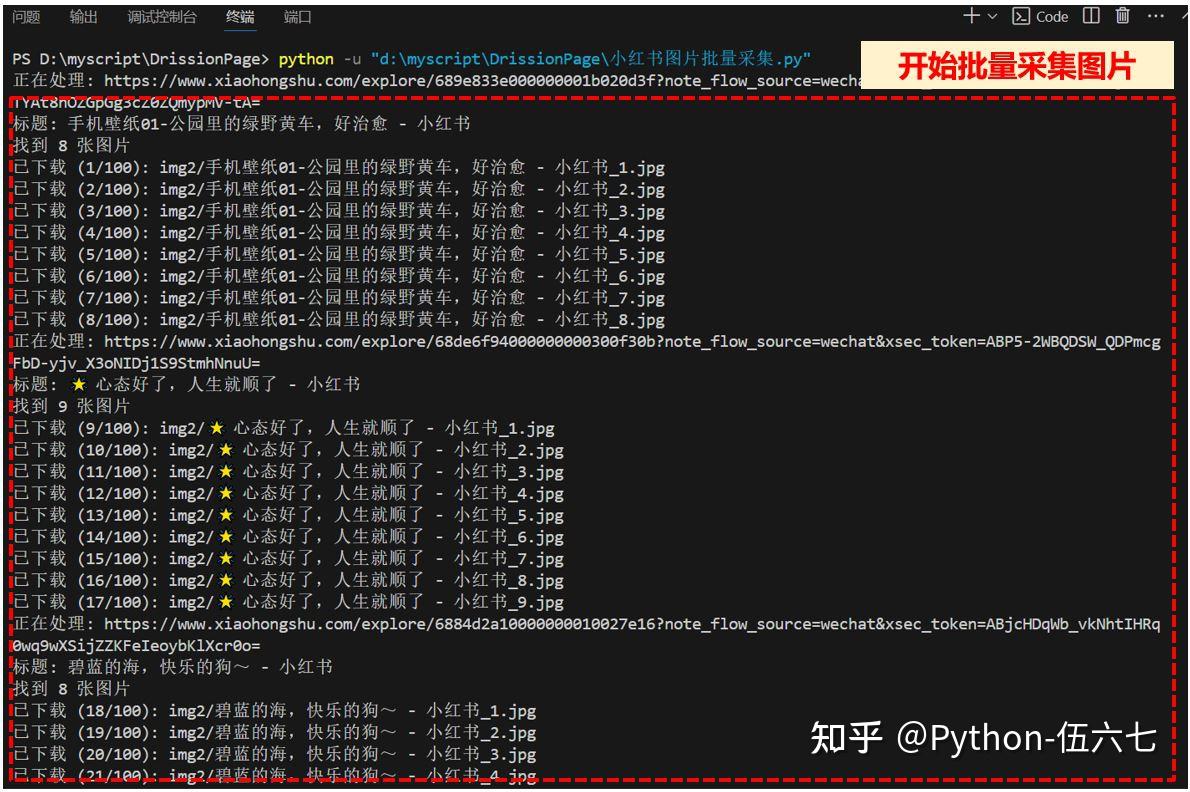
🎉 执行程序,效果如下:
🖥️ Vscode控制台运行输出截图:
📋 下载好的图片文件截图:


🚀四、重要提示
⚠️ 注意事项
🧹抓包分析:准确分析出要爬取的信息关键点
⏰请求频率:别太频繁,易触发反爬机制
💾访问限制:进行身份验证登录或切换账号
🔒注意版权:有明确版权标注的内容不乱存乱发及商用
💎总 结
🎉 通过此案例的分享,相信你能掌握如何从小红书获取美美的图片!
⭐关注我,持续分享实用的Python技巧
💬 如需完整源码:请点颗爱心❤️ + 评论区回复"小红书图片“,私信发你(记得先关注才能收私信哦~)