LLM应用剖析: 热点新闻助手TrendRadar
欢迎关注公众号: 爱学习的妮妮 qiang
1. 背景
- 花了近三天时间,深入研究了 GithubGitHubGithub 近几天一直霸榜的热门项目 TrendRadar,星标已达 30K+,与先前的开源项目GitHub11 月份 github 的趋势榜国产双雄。
- 项目的部署小白直接入手,基于 GitHub Action 实现一键配置与部署,项目介绍教程还是很详细的。
2. 整体流程
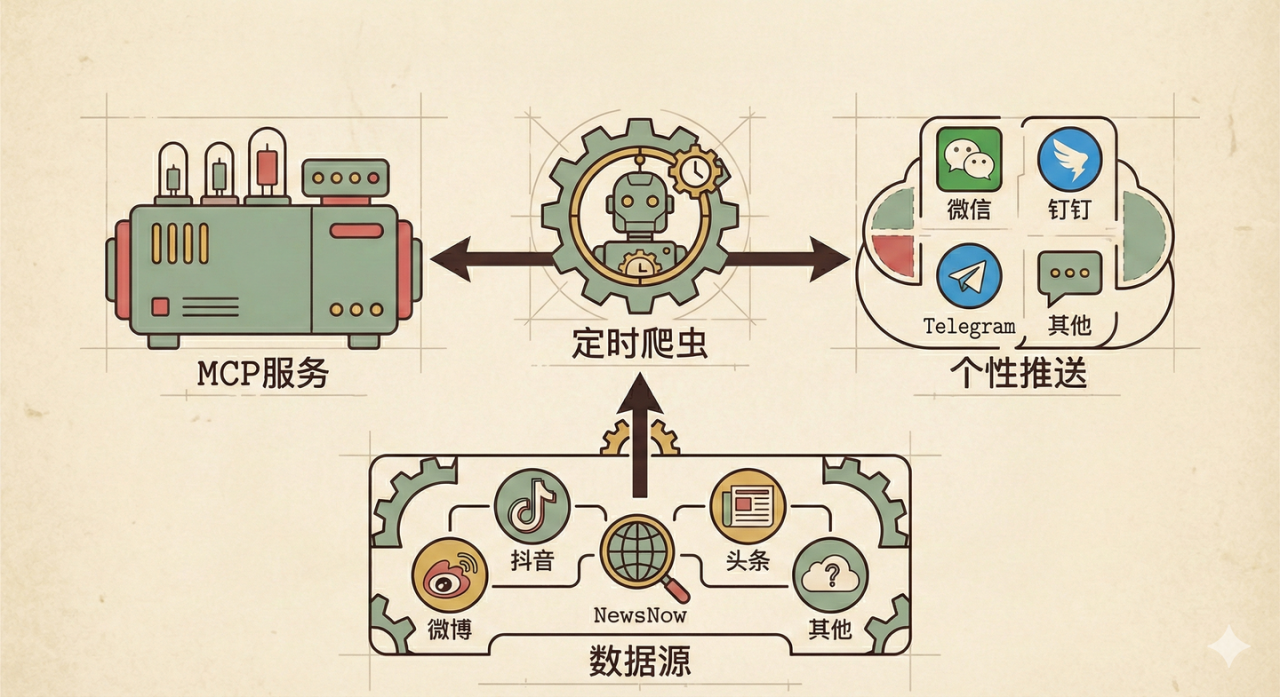
- (1) 数据源: 和微舆一样,是基于开源项目 newsnow 的 35+个新闻及资讯网站的榜单获取,包括抖音、头条、微博、贴吧、知乎等
- (2) 定时爬虫: 基于 GitHub Actions 部署,默认每小时执行一次爬虫,具体可以参考.GitHub/workflows/crawler.yml 中的配置,爬取的数据保存在本地 output。
- (3) 个性化推送: 通过设置个人关注的关键词、热度趋势、时间频次等策略,可推送至微信、钉钉、飞书、Telegram、邮件、ntfy 等
- (4) MCP 服务: 通过 FastMCP 构建 MCP 服务,且项目中提供 Cherry Studio 接入教程,该 MCP 服务提供如下工具:
- a. get_latest_news: 获取最新下载批次的新闻
- b. get_trending_topics: 获取个人关注词的新闻出现频率统计
- C. get_news_by_date: 获取指定日期的新闻数据,用于历史数据分析和对比
- d. analyze_topic_trend: 统一话题趋势分析工具,整合多种趋势分析模式
- e. analyze_data_insights: 统一数据洞察分析工具, 整合多种数据分析模式
- f. analyze_sentiment: 分析新闻的情感倾向和热度趋势
- g. find_similar_news: 查找与指定新闻标题相似的其他新闻
- h. generate_summary_report: 每日/每周摘要生成器, 自动生成热点摘要报告
- i. search_news: 统一搜索接口,支持多种搜索模式
- j. search_related_news_history: 基于种子新闻,在历史数据中搜索相关新闻
- k. get_current_config: 获取当前系统配置
- l. get_system_status: 获取系统运行状态和健康检查信息
- m. trigger_crawl: 手动触发一次爬取任务
3. 核心源码
- (1) 整体代码非常简单,代码风格偏冗余(近 5000 行的 main.py 包含了所有),建议客官们源码可以浏览浏览。
- (2) 仔细研读了 FastMCP 的操作手册,发现现在构建 MCP 服务,也是手拿把掐分分钟。以下是该项目 MCP 服务的部分内容
from fastmcp import FastMCP
# 创建 FastMCP 2.0 应用
mcp = FastMCP(『trendradar-news』)
@mcp.tool
async def trigger_crawl(
platforms: Optional[List[str]] = None,
save_to_local: bool = False,
include_url: bool = False
) -> str:
「」「
手动触发一次爬取任务(可选持久化)
Args:
platforms: 指定平台 ID 列表,如 [『zhihu』, 『weibo』, 『douyin』]
- 不指定时:使用 config.yaml 中配置的所有平台
- 支持的平台来自 config/config.yaml 的 platforms 配置
- 每个平台都有对应的 name 字段(如」知乎「、」微博「),方便 AI 识别
- 注意:失败的平台会在返回结果的 failed_platforms 字段中列出
save_to_local: 是否保存到本地 output 目录,默认 False
include_url: 是否包含 URL 链接,默认 False(节省 token)
Returns:
JSON 格式的任务状态信息,包含:
- platforms: 成功爬取的平台列表
- failed_platforms: 失败的平台列表(如有)
- total_news: 爬取的新闻总数
- data: 新闻数据
Examples:
- 临时爬取: trigger_crawl(platforms=[『zhihu』])
- 爬取并保存: trigger_crawl(platforms=[『weibo』], save_to_local=True)
- 使用默认平台: trigger_crawl() # 爬取 config.yaml 中配置的所有平台
」「」
tools = _get_tools()
result = tools[『system』].trigger_crawl(platforms=platforms, save_to_local=save_to_local, include_url=include_url)
return json.dumps(result, ensure_ascii=False, indent=2)
def run_server(
project_root: Optional[str] = None,
transport: str = 『stdio』,
host: str = 『0.0.0.0』,
port: int = 3333
):
「」「
启动 MCP 服务器
Args:
project_root: 项目根目录路径
transport: 传输模式,『stdio』 或 『HTTP』
host: HTTP 模式的监听地址,默认 0.0.0.0
port: HTTP 模式的监听端口,默认 3333
」「」
# 初始化工具实例
_get_tools(project_root)
# 根据传输模式运行服务器
if transport == 『stdio』:
mcp.run(transport=『stdio』)
elif transport == 『HTTP』:
# HTTP 模式(生产推荐)
mcp.run(
transport=『HTTP』,
host=host,
port=port,
path=『/mcp』 # HTTP 端点路径
)
else:
raise ValueError(f「不支持的传输模式: {transport}」)4. 总结与思考
- 项目的初衷主要是通过聚合的 35+新闻资讯,然后通过用户自定义关键词等策略实现个性化推送,想要学习资讯榜单爬取、多端推送以及构建 MCP 服务的读者,可以学之以用。
5. 参考
- (1) 项目地址: HTTPS://GitHub.com/sansan0/TrendRadar
- (2) 榜单聚合项目: HTTPS://GitHub.com/ourongxing/newsnow
- (3) FastMCP 文档: HTTPS://gofastmcp.com/getting-started/welcome