OpenClaw部署记录1:基本部署
链接:https://zhuanlan.zhihu.com/p/2003153565624063235
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
OpenClaw 是一款可以在个人设备上运行的AI 助手,本文详细记录了在Windows上部署的完整过程。
操作系统:Windows 11家庭中文版(WSL2)
1、安装Node
(1)安装nvm
nvm为Node的版本控制器,安装命令为
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash安装nvm后,需要关闭当前终端,并重新开启新的终端,查询nvm是否安装成功,查询命令为
nvm --version如果安装成功,则会显示具体的版本号,如图1所示。

(2)安装Node
node目前最新的稳定版为v24,安装命令为
nvm install 24安装完毕后,可以查询node是否安装成功,查询命令为
node -v如果安装成功,则会显示具体的版本号,如图2所示。

2、安装openclaw命令行工具
openclaw命令行工具的安装命令为
npm install -g openclaw@latest等待几分钟即可完成安装,安装完成后,系统中就多了一个可执行命令openclaw,接下来就可以使用它进行后续操作。查询是否安装成功,其命令为
openclaw -v如果安装成功,则会显示具体的版本号,如图3所示。

3、openclaw基础配置
执行下述命令,会进入openclaw的交互式界面,可以逐步进行初始化设置
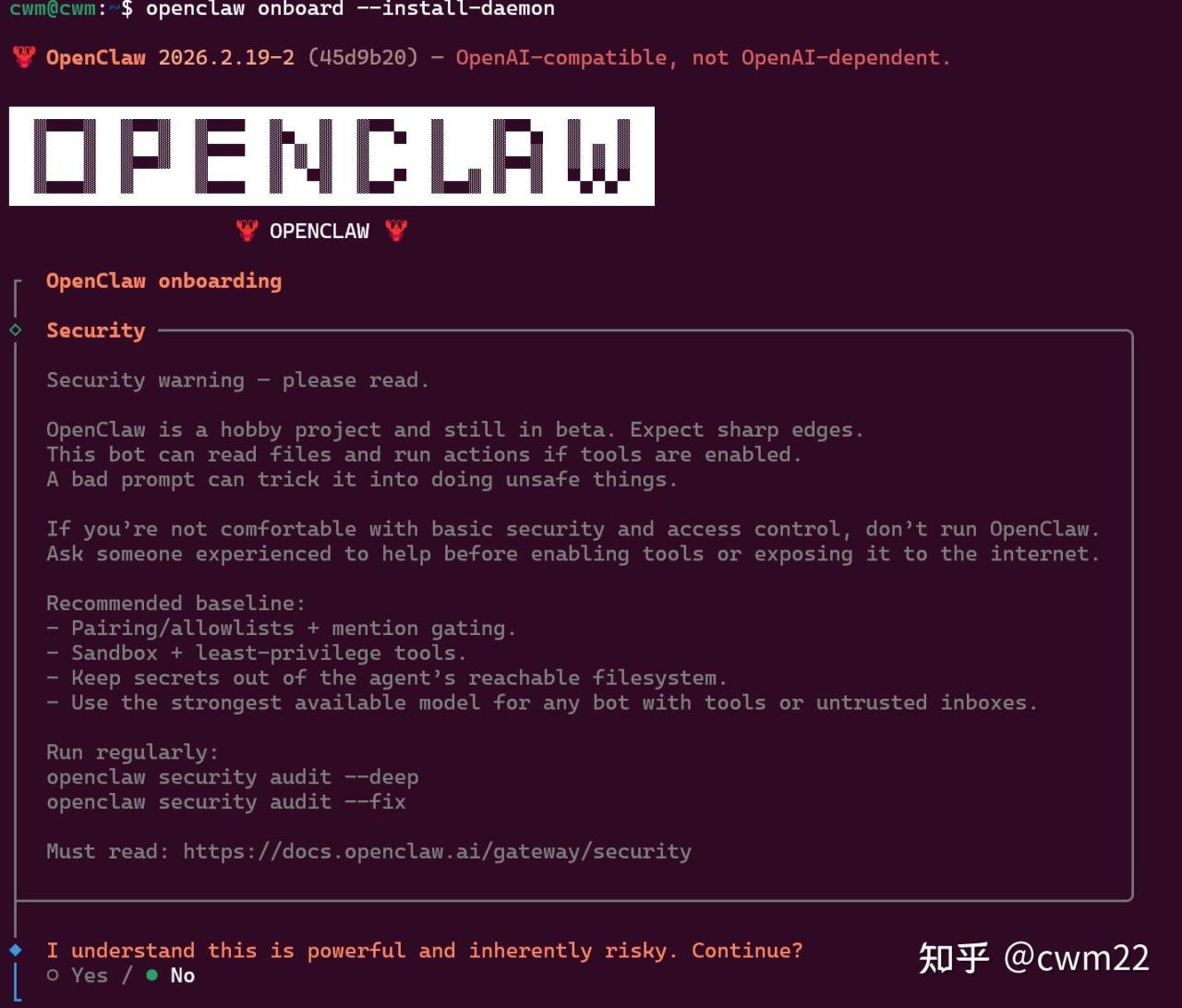
openclaw onboard --install-daemon(1)安全性警告
进入交互界面后,如图4所示。这是一个安全性警告的界面,选择Yes即可。在交互界面,通过键盘上下键移动到对应选项,回车即可进入到下个界面。
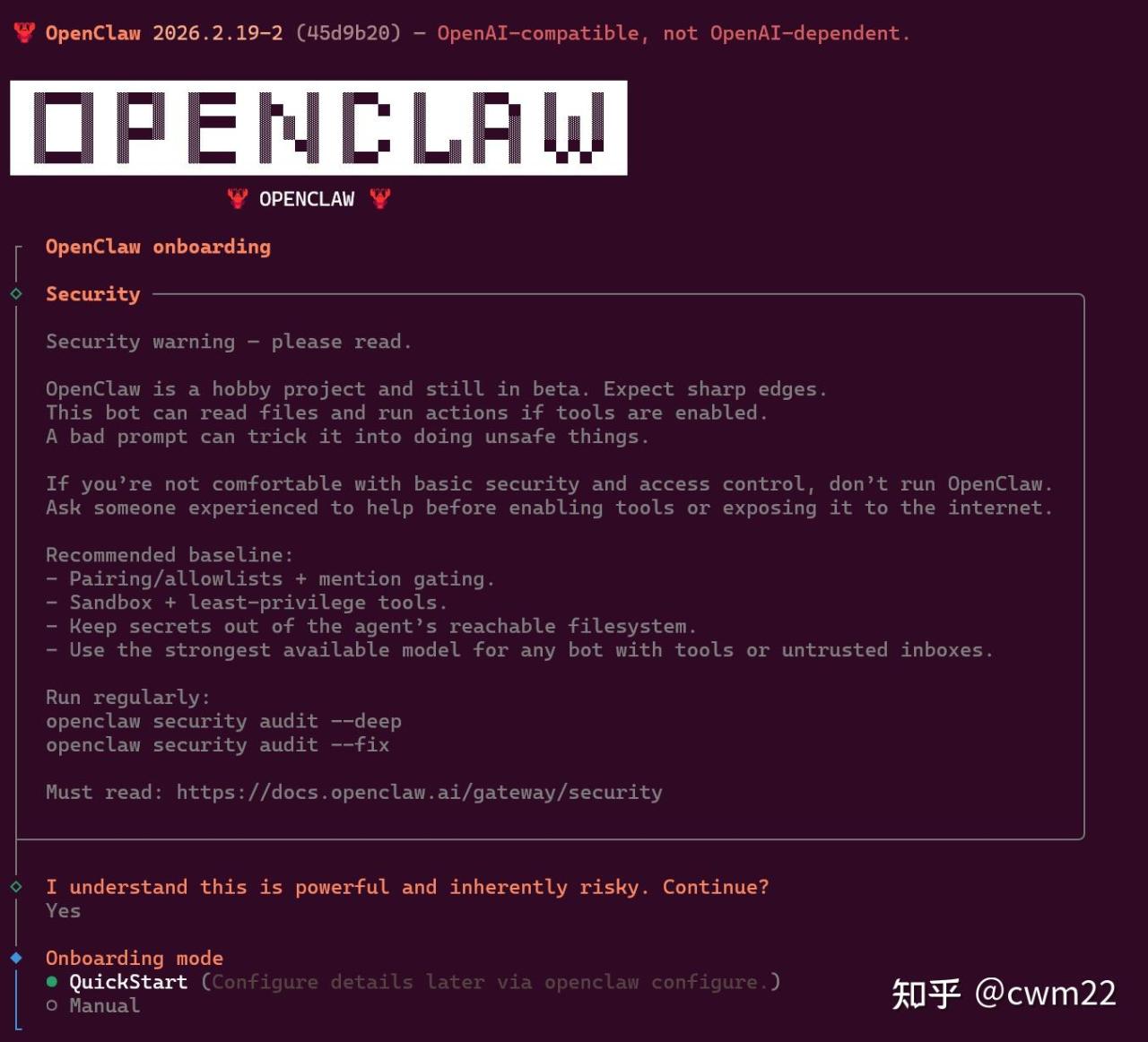
(2)模式选择
接下来出现如图5所示的界面,这里可以先选择QuickStart,后续再进行更细节的配置
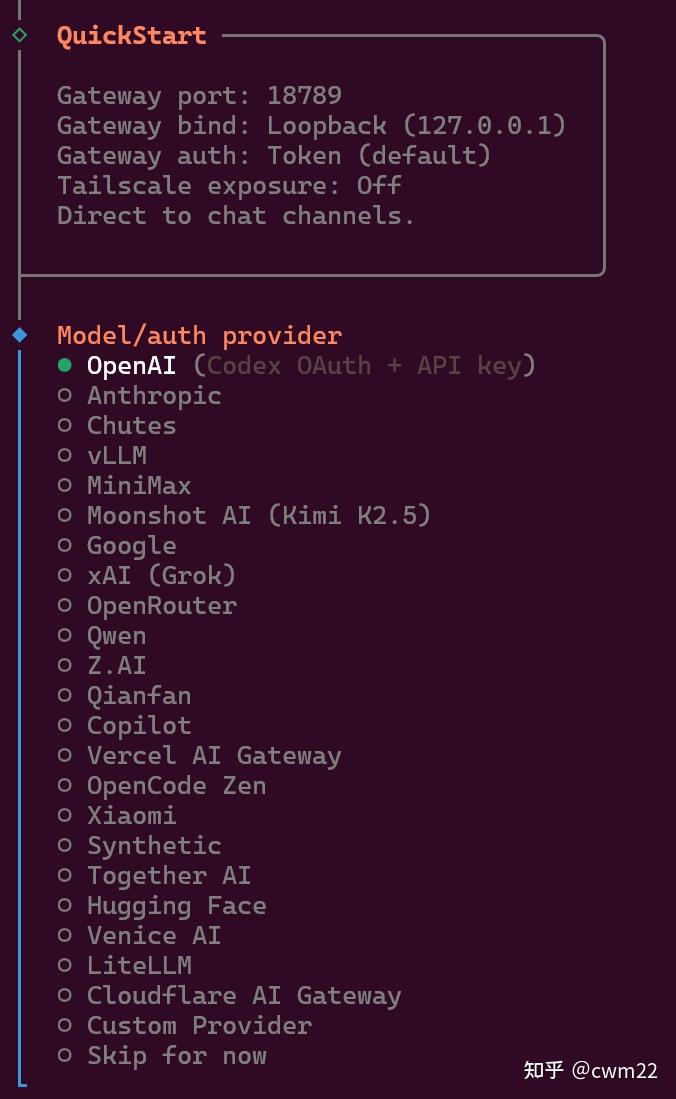
(3)模型配置
接下来出现如图6所示的界面,这里是需要选择用到的AI大模型供应商,官方推荐的是Anthropic。不过考虑到成本问题,暂时可以选择Moonshoot AI,该供应商提供了用于openclaw服务的免费模型。
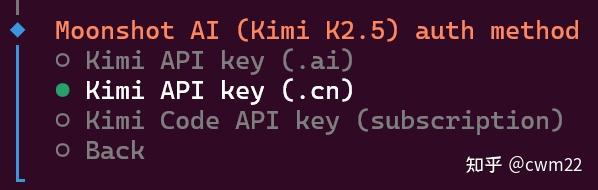
选择Moonshoot AI后,出现如图7所示的界面,这里选择第2个选项即Kimi API key (.cn)
选择Kimi API key (.cn)后,出现如图8所示的界面,输入Kimi API key即可。该API Key的申请地址为:Moonshot AI 开放平台 – Kimi 大模型 API 服务
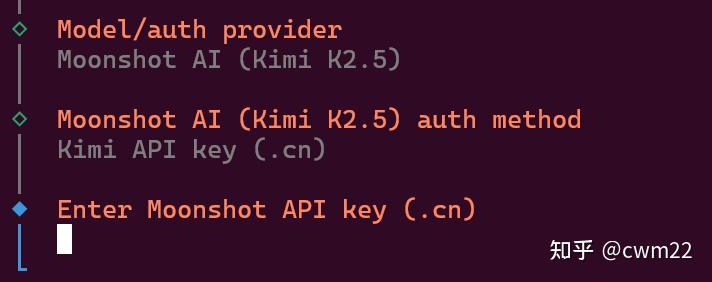
输入Kimi API key后,回车进入到如图9所示的模型选择界面,选择Keep current即可

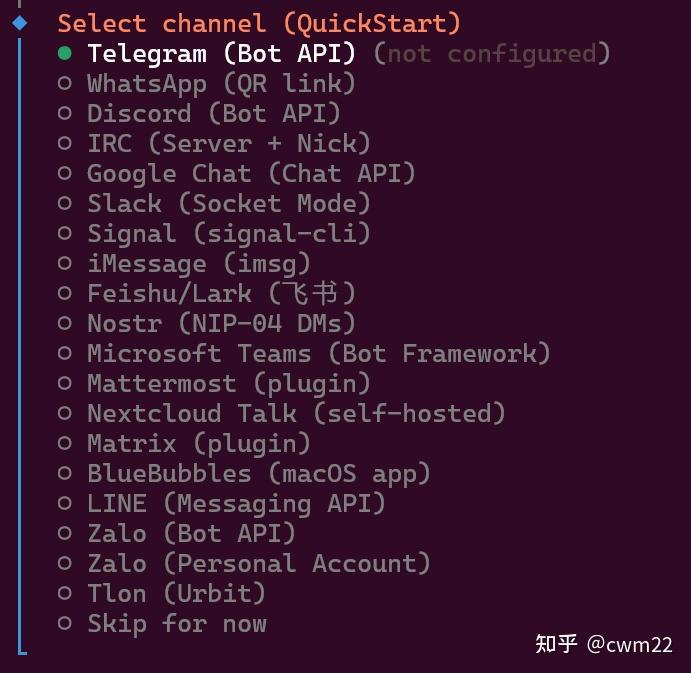
(4)通信工具选择
接下来进入到如图10所示的界面,这里是聊天工具选项,可以暂时跳过即选择Skip for now
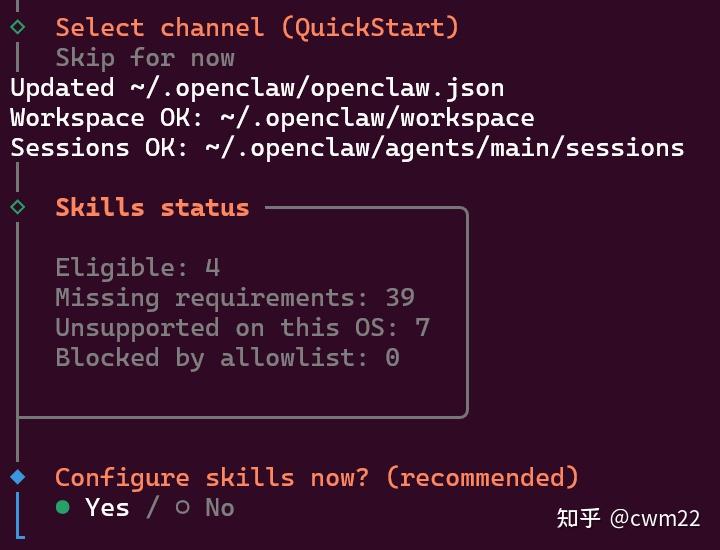
(5)skills工具配置
接下来是配置工具页面,如图11所示,选择Yes
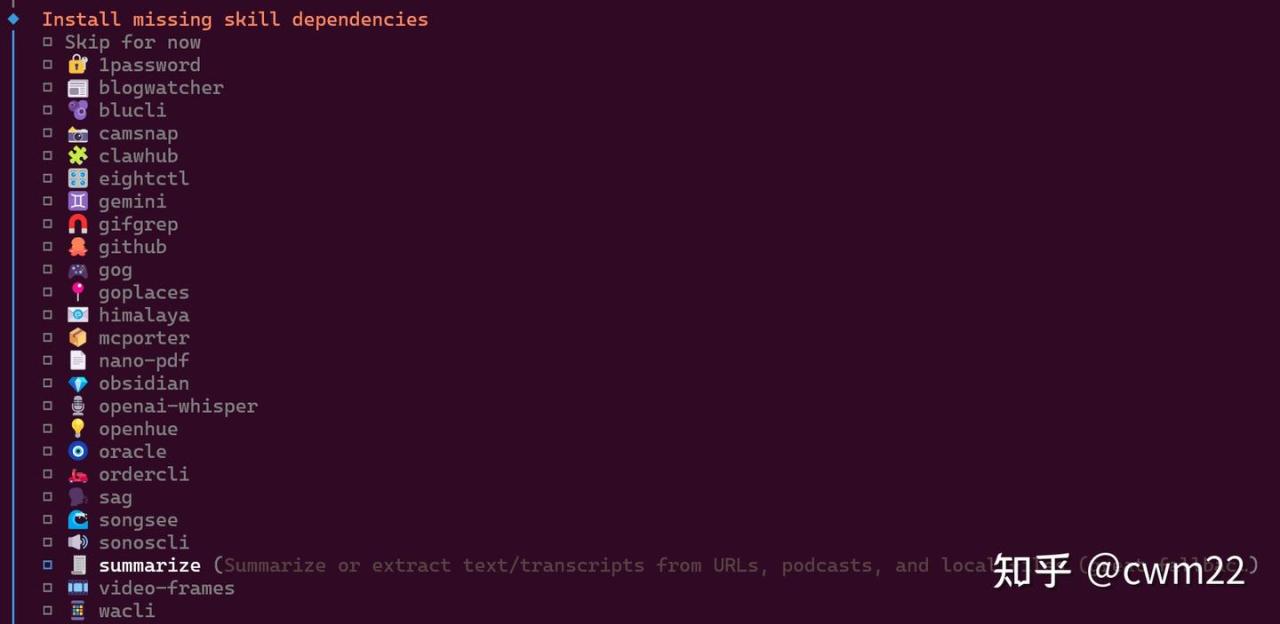
接下来是具体的工具选择如图12所示,这里可以选取Skip for now即跳过该步骤,后续可以添加相关的工具。如果需要选择某个工具,首先通过键盘上下键移动到某个工具选项,按下键盘上的空格即可选中某个工具,可以选择多个工具。
(6)地理位置查询工具
接下来进入到谷歌地理位置查询的API的设置界面如图13所示,如果没有就选择No。

(7)GEMINI模型的API
接下来进入到nano-banana-pro组件的GEMINI模型的API配置界面如图14所示,如果没有就选择No。

(8)Notion工具的API
接下来进入到Notion工具的API配置界面如图15所示,Notion 是一款非常强大的一体化协作与知识管理工具,如果没有API,就选择No。

(9)图像生成工具
接下来进入到如图16所示的图像生成工具的API配置界面,这是openai系列的模型,如果没有API,就选择No。

(10)语音识别工具
接下来进入到如图17所示的语音识别服务的API配置界面,这是openai系列的模型,如果没有API,就选择No。

(11)文本转语音工具
接下来进入到如图18所示的文本转语音工具的API配置界面,如果没有API,就选择No。

(12)扩展功能
接下来进入到如图19所示的扩展功能的界面,各组件的具体功能为
boot-md:启动时自动加载 Markdown 格式的配置/指令文档
bootstrap-extra-files:启动时自动加载自定义的额外文件
command-logger:自动记录在 OpenClaw 里执行的所有命令、操作、AI 交互记录
session-memory:让 OpenClaw 记住当前会话的上下文
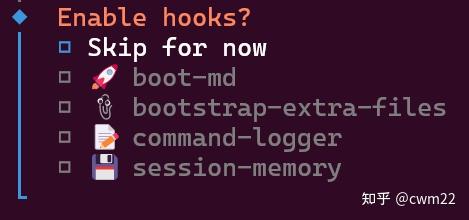
这里后两个要选定,前两个可以暂时不用。
(13)重启
接下来进入到如图20所示界面,选择重启即Restart即可。

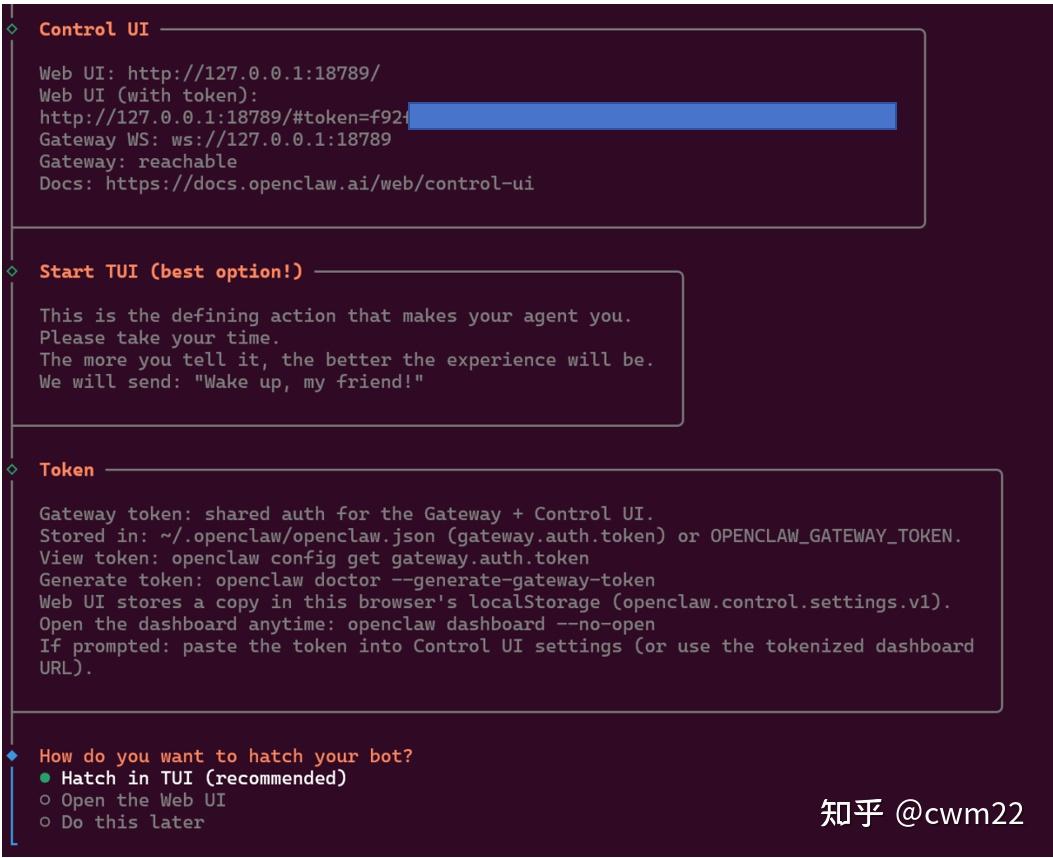
(14)身份设置
接下来进入到如图21所示的界面,也是最后一步,用于给助手设置身份、目标、规则。可以选择Do this letter即后续再设置。注意,图21所示的界面也给出了助手的网页端访问地址,即Control UI—->Web UI (with token)对应的地址,将该地址输入到浏览器中打开即可,打开后如图22所示,此时可以与AI助手进行聊天对话了。
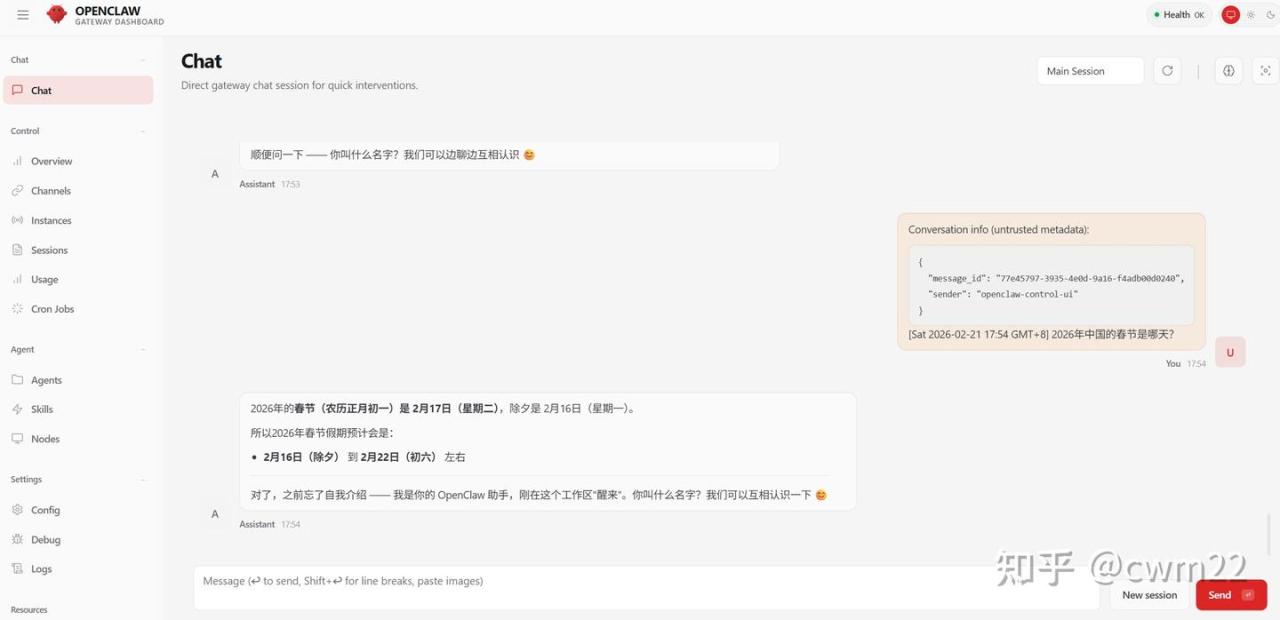
正常情况下,进入到Windows中的wsl系统后,openclaw服务即可使用。如果想查看openclaw服务的运行状态,命令为
openclaw gateway status要查看web端的访问地址,命令为
openclaw dashboard启动openclaw服务的命令为
openclaw gateway start重启openclaw服务的命令为
openclaw gateway restart关闭openclaw服务的命令为
openclaw gateway stop