用了这个开源项目,把 OpenClaw 的 token 账单砍掉了 80%
哈喽,大家好,我是蝈蝈。
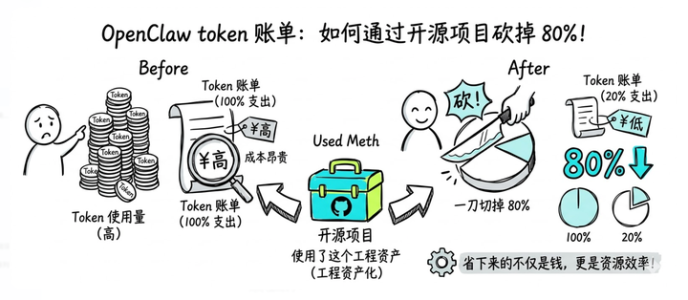
今天来聊一个 OpenClaw 用户几乎都会遇到的问题——token 烧得太快了。
用过 OpenClaw(ClawdBot)的朋友都有这个体验:刚开始用的时候特别爽,AI 记住你的偏好、习惯、工作背景,像一个真正了解你的私人助理。但用了一段时间之后,账单一来,有点傻眼。
钱到底烧在哪了?今天把这个问题说清楚,顺便给出一个社区实测有效的解法。
先搞清楚问题根源
OpenClaw 的长期记忆,本质上是一堆 Markdown 文件——你的偏好、工作信息、历史对话摘要,全存在 MEMORY.md 或者 memory/ 目录里。每次你问它一个问题,它要”翻记忆”来给你更好的回答。
最原始的做法,是把整个记忆文件完整地塞进上下文。知识库小的时候没感觉,但一旦你用了几个月,记忆文件膨胀到几万字,每次对话光”加载记忆”这一步就要烧掉大量 token。而那几万字里,和你当前问题真正相关的,可能只有几百字。
剩下的 80%?纯纯的浪费。
而且这个问题会随着时间持续恶化——知识库越大,每次烧的越多,没有上限。
解法:QMD 本地混合检索
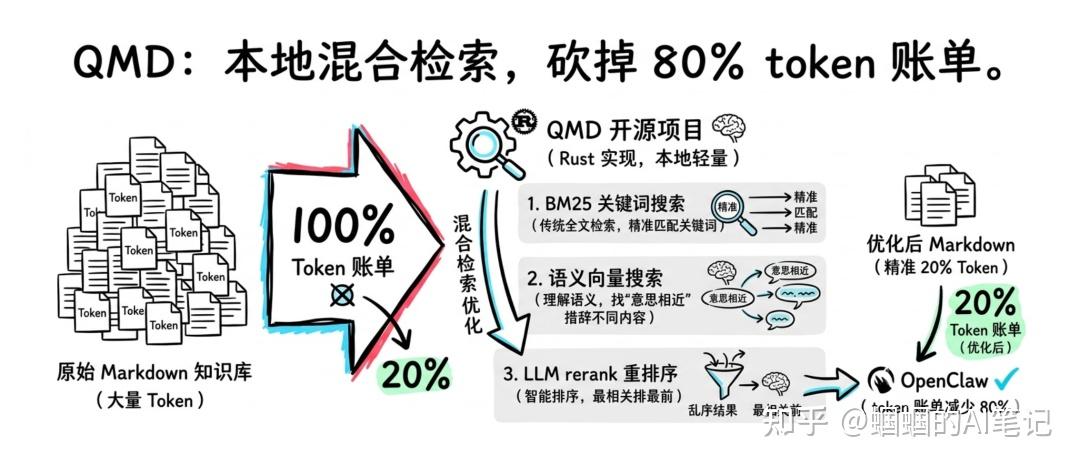
社区目前最主流的解法,是用 QMD 做本地混合检索,取代把整个 MEMORY.md 反复塞给大模型的笨办法。
实测数据很直接:能省 70%–97% 的 token 消耗。视知识库大小和使用方式而定,但大部分人长期使用下来能稳定省掉 80%+,知识库越大,效果越明显。
QMD 是 Tobi(Shopify 创始人)开源的一个本地轻量混合搜索引擎,专为 Markdown 知识库设计,用 Rust 实现,跑起来很快。它的核心是三种检索方式的组合:
- BM25 关键词搜索:传统全文检索,精准匹配关键词
- 语义向量搜索:理解语义,找”意思相近”但措辞不同的内容
- LLM rerank 重排序:对结果再做一次智能排序,最相关的排最前面
github地址: https://github.com/tobi/qmd
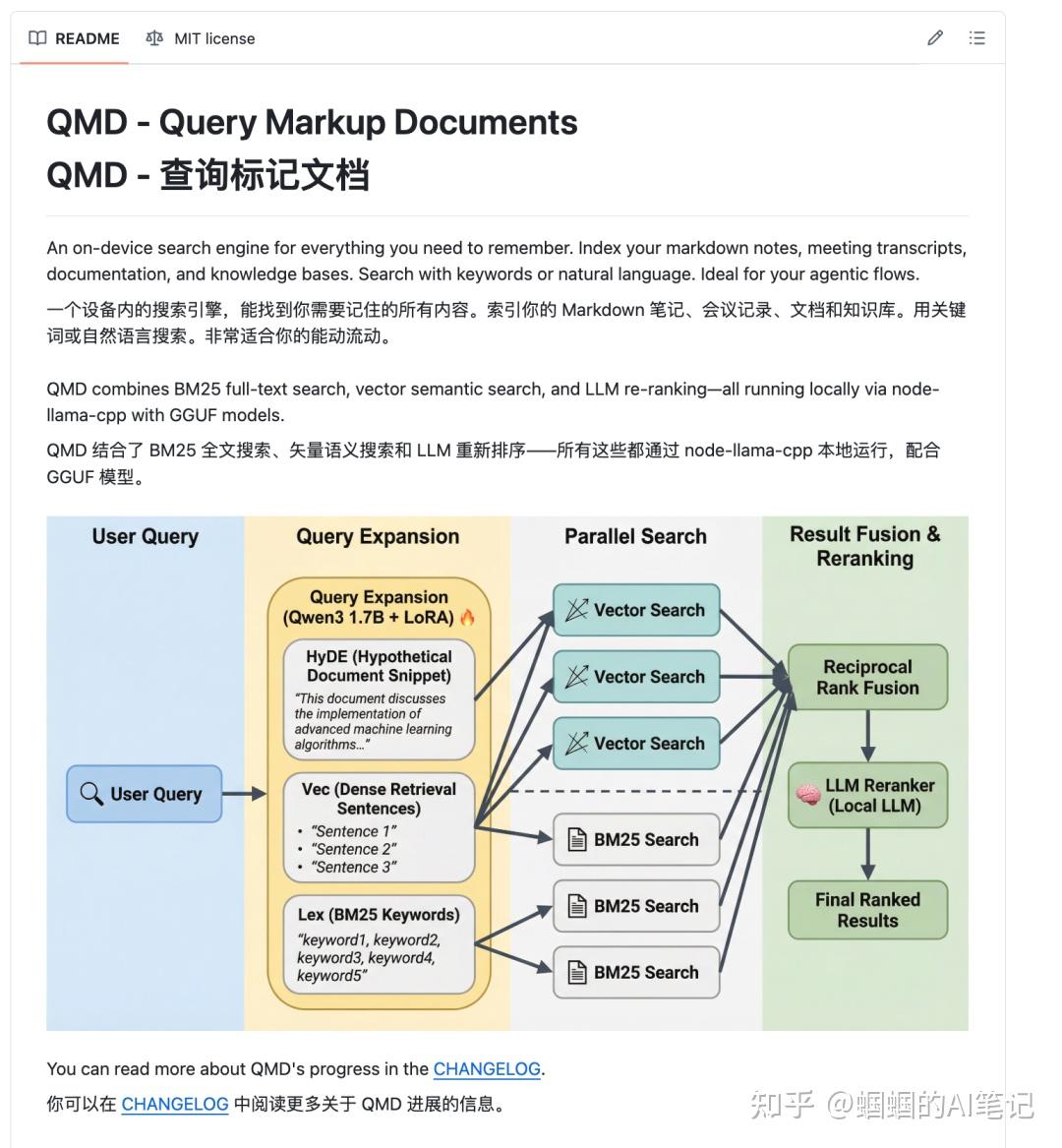
三合一的效果,远比”把整个文件塞进去”精准得多。而且最关键的——全部跑在本地,不联网,不烧任何 API token。搜索本身零成本,数据也不出本地。
OpenClaw 2026 年 2 月之后的版本,已经原生集成了 QMD 作为可选的 memory backend,官方叫它 “QMD Memory Plugin” 或 “QMD skill”。
上手前的必要准备:装 Bun
不管你选哪种接入方式,都要先装 Bun——QMD 官方推荐的运行环境,比 npm/yarn 轻量很多。
Linux / macOS:
curl -fsSL https://bun.sh/install | bash
装完重启终端,验证:
bun --version
能看到版本号(比如 1.1.x 或更高)就 OK。
Windows 用 PowerShell:
irm bun.sh/install.ps1 | iex
方式一:最简单——让 OpenClaw 自己搞定(新手推荐)
这个方式的核心思路是:全程靠”说话”完成配置,不需要手动敲太多命令。
第一步,更新 OpenClaw 到最新版(2026.2.x 之后才原生支持 QMD):
Update yourself to the latest version
第二步,让它自己安装 QMD 依赖:
请安装 QMD skill 的所有依赖,包括本地 embedding 模型
第三步,启用 QMD 作为记忆后端,直接说:
从现在开始使用 QMD 作为我的主要长期记忆检索方式
不要再每次都加载整个 MEMORY.md
只在必要时用 qmd search / qmd vsearch / qmd query 取相关片段
或者直接改配置文件 ~/.openclaw/openclaw.json:
{
"memory":{
"backend":"qmd",
"qmdCollections":["memory","life","workspace"],
"experimental":{
"useQmdForSession":true
}
}
}
第四步,也是最容易被跳过的一步——初始化索引:
请对我的 memory/ 目录、life/ 目录运行 qmd update && qmd embed
以后每天自动更新一次索引
没有索引,QMD 就没有东西可搜。这步不能省。
四步完成,OpenClaw 就会自动用 QMD 检索记忆,而不是每次把几万 token 的上下文全塞进来了。
方式二:更灵活——手动装 QMD,自己配置(进阶用户推荐)
想精细控制的朋友,可以按照自己的知识库结构来划分 collections。
先手动安装 QMD:
bun install -g @tobi/qmd
# 或者:
cargo install qmd
然后按照不同层次的记忆,创建对应的 collections:
# 日常记忆 / 每日日志
qmd collection add ~/clawd/memory --name memory --mask '**/*.md'
# 人生/长期事实
qmd collection add ~/clawd/life --name life --mask '**/*.{md,json}'
# 工作空间文档
qmd collection add ~/clawd --name workspace --mask '**/*.md'
# 可选:清洗过的历史会话
qmd collection add ~/clawd/sessions-clean --name sessions-clean --mask '**/*.md'
建完 collections,跑一次索引和 embedding:
qmd update # 全量更新索引
qmd embed # 生成向量(语义搜索需要这一步)
第一次会稍慢,之后是增量更新,很快。
0 3 * * * cd ~/clawd && qmd update --pull && qmd embed
最后,把下面这段加到 OpenClaw 的 skill 或自定义指令里,教它怎么用 QMD:
当你需要回忆/查找历史信息时,用以下命令:
- qmd search "关键词" -c memory # 关键词搜
- qmd vsearch "自然语言描述" -c life # 语义搜
- qmd query "问题" -c memory,life # 混合搜(最推荐)
只读取返回的片段,不要加载整文件
配置完怎么确认有没有生效?
直接在聊天里问它:
“现在用什么 memory backend?”
回答 QMD,配置成功。然后观察 1–2 天,看 input token 是否明显下降。
对照这张 Check-list 查漏补缺:
- ✅ OpenClaw 版本 ≥ 2026.2.x
- ✅ 已启用 QMD backend
- ✅ 至少跑过一次
qmd update && qmd embed - ✅ 已告诉 agent:”以后用 qmd 搜索记忆,不要再塞整份 MEMORY.md”
- ✅ 观察 1–2 天,确认 input token 明显下降
最后说几句
这套方案配置完,大部分人的 token 消耗腰斩起步,长期使用能稳定省掉 80%+。
但我觉得这件事更大的意义,不只是省了钱。它代表的是 AI 工具使用方式的一次深层转变——从”暴力喂数据”走向”精准检索+按需加载”。
如果这篇对你有帮助,帮忙点赞关注,帮助作者有动力继续更新!
欢迎关注公众号:蝈蝈的AI笔记,里面有更多干货内容。