开源 PDF 解析神器爆火,狂揽 11000+ GitHub Star!


做 RAG 应用,有一道坎几乎每个开发者都绕不过去,那就是 PDF 文件解析。
多栏论文读取顺序全乱,表格变成一行乱码,数学公式直接消失,扫描版 PDF 更是分文不识。
前不久,偶然在 GitHub 上发现了一个叫 OpenDataLoader PDF 的开源项目。
专门为 AI 数据管道设计的 PDF 解析器,同时也是在开源方案里少有的能全流程处理 PDF 无障碍合规的工具。
先说解析这块。
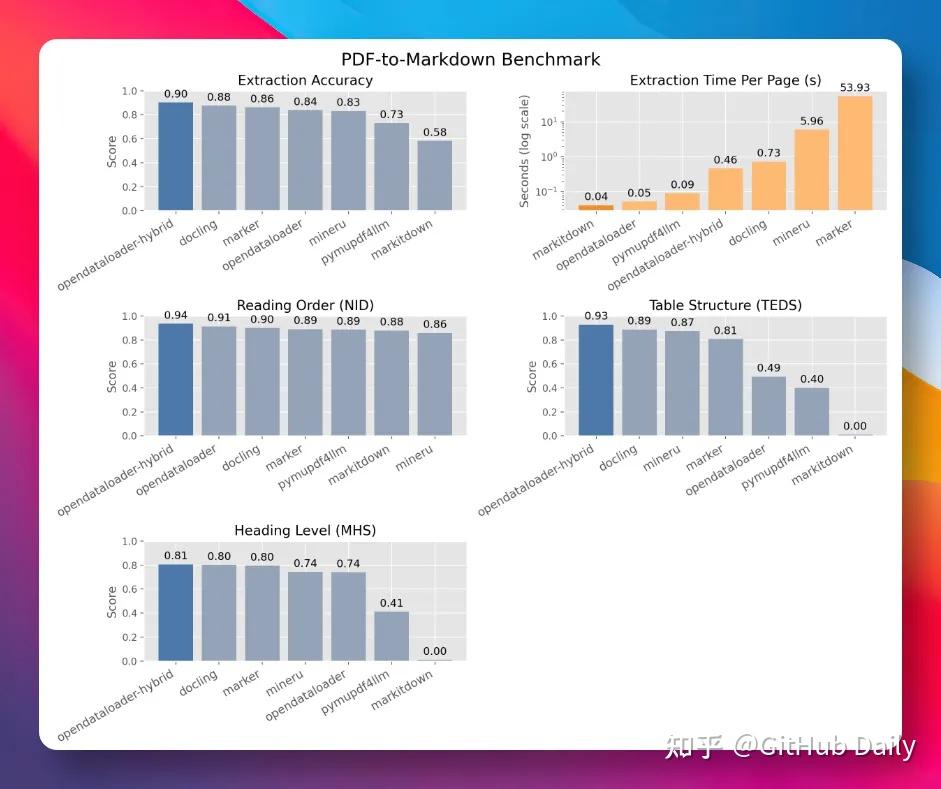
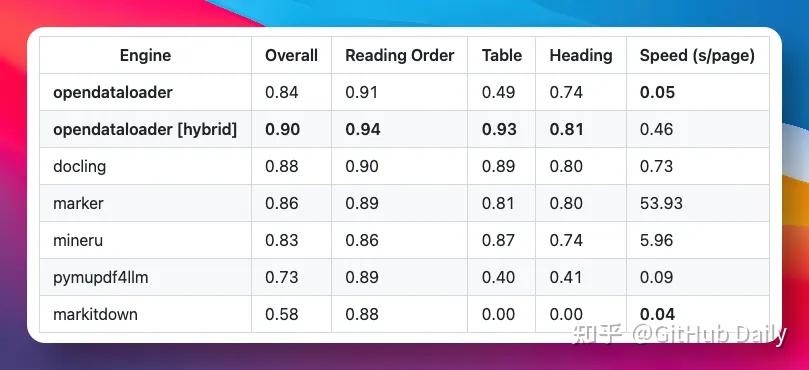
它在一个涵盖 200 份真实 PDF(含多栏文档、学术论文)的第三方 benchmark 里,综合精度拿了第一,得分 0.90,表格提取精度 0.93。
同类主流工具的对比大概是这样:docling 0.88,marker 0.86,pymupdf4llm 0.73。
差距不算悬殊,但确实是第一。
本地跑,无需 GPU,不联网,数据不出本机。
本地模式速度是 0.05 秒每页。8 核机器批量处理,吞吐量可以超过 100 页每秒。
对有法律、医疗、金融文档需求的团队来说,「数据不出境」这一条本身就值得重点关注。
Hybrid 模式是另一个亮点。
遇到复杂表格、无边框表格、扫描 PDF、数学公式、图表——这些情况在本地模式下容易翻车。
Hybrid 模式的思路是:简单页面继续本地跑(0.05 秒),检测到复杂内容就自动路由给 AI 后端处理。
后端也跑在本机,不上云。
开启方式很直接:
pip install "opendataloader-pdf[hybrid]"
# 终端 1,启动后端
opendataloader-pdf-hybrid --port5002
# 终端 2,处理文档
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf开了 Hybrid 之后,表格精度从 0.49 跳到 0.93。
扫描件加 --force-ocr,支持中文、韩文、日文、阿拉伯文等 80 多种语言。
公式提取输出标准 LaTeX,图表自动生成 AI 描述文本,顺便解决了 RAG 里图表内容无法被检索的问题。

输出格式支持 Markdown、JSON、HTML。
JSON 输出里,每个元素都带边界框坐标和页码。
做 RAG 时,不只能拿到文本,还能精确定位到原始 PDF 里的具体段落、表格、图片,实现「点击溯源」的交互体验。
另外内置了 prompt injection 防护,自动过滤 PDF 里隐藏的透明文字、离页内容、可疑图层,喂给 LLM 之前先清洗一遍。
LangChain 有官方集成:
pip install langchain-opendataloader-pdf还有一块,国内关注不多,但其实挺重要。
PDF 数据可访问性合规。
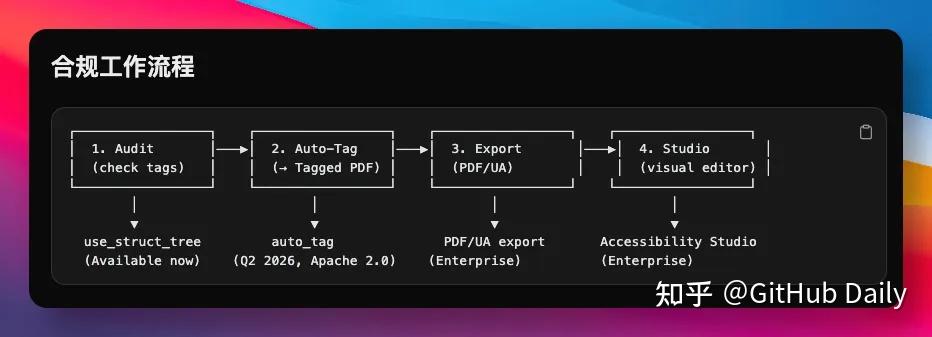
OpenDataLoader 的方案是:用同一套版面分析引擎,自动给无标签 PDF 生成结构标签,输出 Tagged PDF。
在开源方案里,这条路目前几乎没有先例,不依赖任何商业 SDK,Apache 2.0 协议。
项目与 PDF Association 和 veraPDF 开发团队 Dual Lab 合作,按照 Well-Tagged PDF 规范构建,输出结果通过 veraPDF 自动验证。
上手只需要三行:
pip install opendataloader-pdf
import opendataloader_pdf
opendataloader_pdf.convert(
input_path=["file1.pdf", "folder/"],
output_dir="output/",
format="markdown,json"
)
唯一的前置条件是 Java 11+,运行前用 java -version 确认一下。
RAG 应用的上限,很大程度上取决于数据管道的质量。
模型可以换,提示词可以调,但文档解析这一层如果是烂的,后面再怎么折腾都是白费。
OpenDataLoader 做的事情,是把这块地基打扎实。
免费,开源,本地跑,数据不出境。
这种工具,早点用上,就少踩一坑。
GitHub 项目地址:https://github.com/opendataloader-project/opendataloader-pdf
今天的分享到此结束,感谢大家抽空阅读,我们下期再见,Respect!