Markdown 为什么会流行?
链接:https://www.zhihu.com/question/30311240/answer/2024268787470405884
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
你把一份起诉状、合同或庭审笔录丢给Claude,结果它能大致看懂意思,但是token消耗量巨大,很快上下文就满了,然后你还要接受压缩后的信息,会造成很多信息失去细节。
对法律工作来说,这是致命的。
但问题不在模型,在格式。
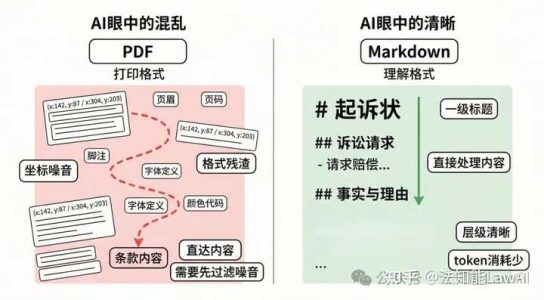
PDF是打印格式。它擅长保留页面外观,但标题、条款、表格、脚注、页眉页脚,在PDF内部只是一个个摆在不同坐标上的文本块。人类阅读没问题,模型拿到这堆东西,只能挣扎着猜哪些是正文、哪些是版式噪音。
所以更实用的工作流不是”把PDF发给Claude”,而是”先转成Markdown,再让Claude分析”。
实际上我现在,从来不用word写内容了,都是使用Markdown。
为什么AI特别喜欢读Markdown
Markdown有一个根本优势:打开来全是纯文字,没有隐藏数据。
Word文档和PDF在文件内部存着大量人眼看不见的东西——字体定义、颜色代码、页面坐标、修订历史。模型拿到这类文件,要先把这些东西过滤掉才能接触真正的内容,而不同文档的格式结构差异很大,过滤效果时好时坏。
Markdown不存在这个问题。标题是#号加文字,加粗是两个星号,就这些。模型从第一个字符开始就在处理内容,不需要先猜格式。
还有token的问题。同样一份合同,直接丢给Claude,解析时出来的文本往往夹带大量空格、换行符和乱码,耗费token数可能是Markdown版本的几十倍。Markdown更紧凑,同样大小的上下文窗口能装进更多实质内容,Claude读得更准,费用也更低。
法律人的文书革命,就是把所有材料底层转为Markdown
在动手之前,先看一眼Markdown长什么样,以及转换完的法律文书会有什么结构。
Markdown只有几个符号,法律人用到的大概是这几种:
#号代表标题层级,一个#号是文书名称,两个是主要章节,三个是子项。Claude读到# 号就明白这是新的层级,不会把”第一部分”当成正文段落。
空一行是分段,效果和Word里敲回车一样,但文件里没有任何格式符号夹进来。
横杠开头是无序列表,数字加点是有序列表。证据清单、诉讼请求事项,转完通常都变成列表,结构一目了然。
竖线和横杠拼出来的是表格。借贷合同里的还款计划、证据目录里的编号与说明,转成Markdown表格之后,Claude可以直接按列提问,比平铺成段落灵活得多。

一份起诉状转成Markdown之后,大致是:一级标题是文书名,二级标题是”诉讼请求”、”事实与理由”、”证据目录”,每节下面是段落或列表。Claude拿到这份文件,就像拿到了一份已经整理好目录的电子卷宗,想问哪节直接说,不需要它自己去翻。
转换第一层:markitdown,把文字版文书转成Markdown
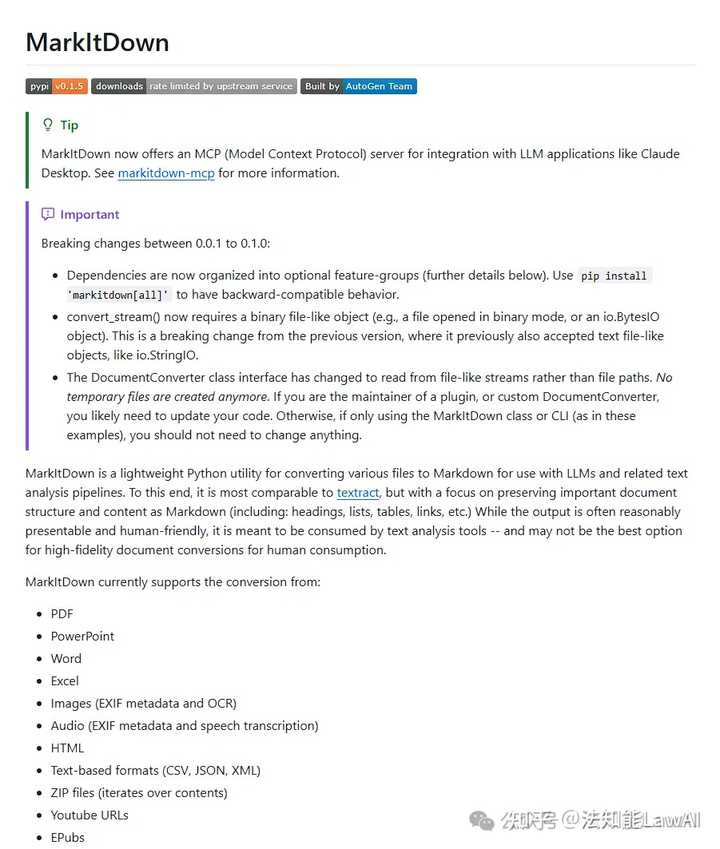
markitdown 是微软出品的开源CLI(什么是CLI,我在法律人学Claude|第七期:给Claude装上”外挂”——CLI与MCP工具使用指南中讲过)工具,支持PDF、Word、Excel、PPT转Markdown。
手里是文字版PDF(鼠标能选中文字的那种)、Word、Excel,先用它。告诉Claude”把这份文件转成Markdown”,Claude会直接调用工具帮你完成,不需要自己敲命令。
转换完之后开一眼生成的Markdown文件,确认诉讼请求、事实与理由、证据清单各部分层级是否清晰。
转换第二层:ocrmypdf,给扫描件补一层”可搜索文字”
真正麻烦的是扫描件。
很多卷宗材料、银行流水、送达回证,看着是PDF,里面其实只是图片装进了PDF壳里。对这类文件,最有效的第一步是先用传统OCR给它补一层隐藏文字层,开源方案里我认为比较成熟的是 ocrmypdf。
效果类似Acrobat的”识别文字”:页面外观不变,PDF内部多出一层可搜索、可复制的文字。处理完可以直接全文检索,也可以继续交给 markitdown 转Markdown。
扫描清晰的法律文书识别效果通常不错。处理完重点核对金额和日期,这两个地方识别出问题影响最大。
转换第三层:两个工具串起来用
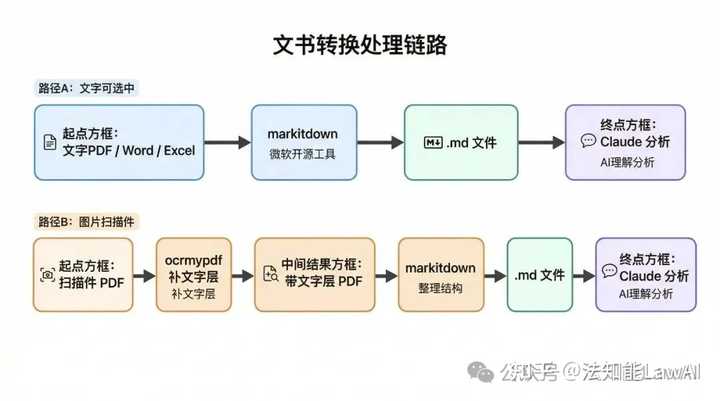
实际用下来,这两个工具是前后接力的关系。
扫描件先过 ocrmypdf 补文字层,得到带文字的新PDF,再用 markitdown 转Markdown。
分工很清楚:ocrmypdf 认字,markitdown 整结构,Claude最后只管分析内容。
比把所有任务都甩给模型,让他自己找工具,链路更可控,出了问题也知道在哪一层出的。
让你的Claude学会这些工具链路
文中涉及的工具链,我整理了一份专门写给Claude看的配置清单——安装命令、用法示例、决策规则都打包在里面。把那份文档内容复制给Claude,它会帮你装好所有工具,并记住什么情况下用哪个,下次遇到文书转换不需要再重新解释。
需要的话,后台发送“转换Markdown”,我把文件发给你。
markitdown-ocr:另一条更直接但有风险的路
markitdown 也有OCR插件,叫 markitdown-ocr。不先补文字层,直接让视觉模型看页面图像,一步转出Markdown。
省事是省事,但这个路线有个明显的毛病:视觉模型容易”改写”,把表单里的内容变成它觉得更通顺的自然语言,而不是老老实实照着原文打出来。合同条款、票据金额这类不容有误的内容,这个问题很要命。
另外,这个插件调用的是OpenAI的视觉API,图像会发到OpenAI服务器(有风险),需要提前配好 OPENAI_API_KEY。
结构清晰的文档需要忠实转录,走 ocrmypdf。只是想快速试一把,markitdown-ocr 也行,但要核对结果。
Gemini 图像识别:处理复杂版面的备选
低清扫描件、印章叠压、表格密集的材料,Gemini视觉OCR可以作为补救手段,它真的很强大,手写体文字也能忠实还原。
但Gemini识别图片,token消耗、时间浪费都是一项不小的开支,不建议直接让Gemini从头识别全文,只做关键部分的识别就可以。
这里就不放例子了,我自己试了试,效果惊人,但不敢乱用。
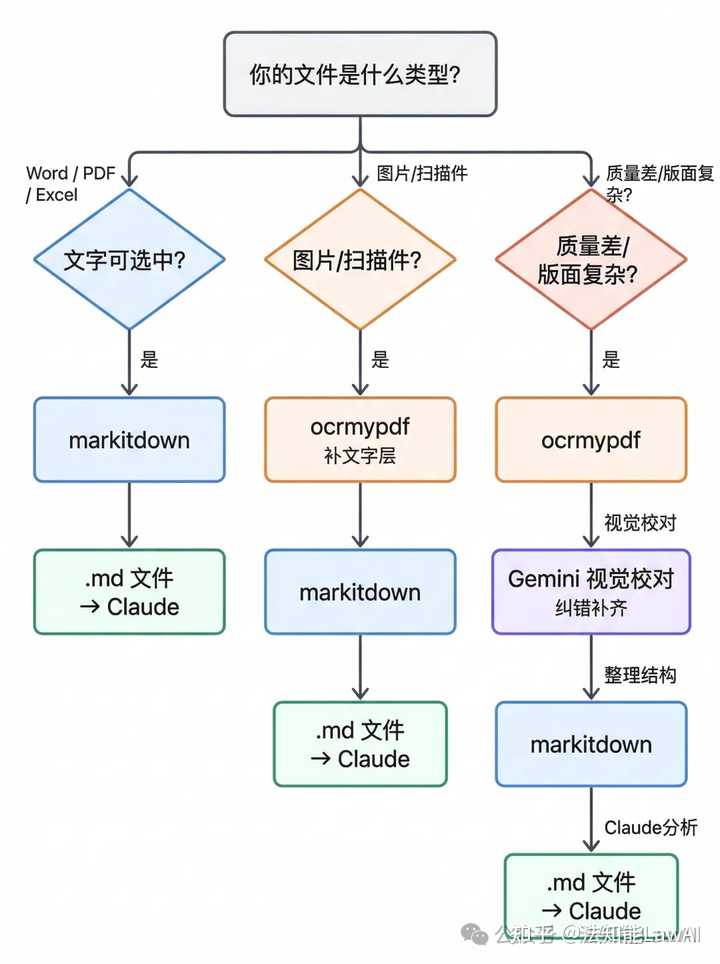
一条适合法律人的完整链路
文字版文件先 markitdown,扫描件先 ocrmypdf 再 markitdown,材料杂乱、OCR质量不够时让视觉模型做校对。核心不是某个工具有多厉害,而是每一步各做各的事,不要什么都往模型那里推。
工具本身不复杂,麻烦的是第一次装好、跑通。跑通之后,拿到Markdown格式的案件材料,再让Claude做检索、摘要、争点归纳,你会发现质量和之前直接丢PDF完全不一样。
常见问题
Q:文字版PDF还需要先OCR吗?
A:一般不用,按照我提供的转换Markdown工具来看,会直接 markitdown 试一次,如果导出的Markdown明显为空,或者字段顺序乱得没法看,会考虑先走 ocrmypdf。
Q:为什么有了OCR文字层,转出来还是有错字?
A:OCR认的是图像,识别是一回事,理解是另一回事。扫描倾斜、阴影、印章叠压、表格线干扰,都会影响准确率。原件扫得清,问题就少很多。
Q:CLI命令一定要自己学会吗?
A:命令本身不需要背,但知道每一步在做什么很重要。全部交给Claude执行,你理解了流程才能判断结果对不对。出问题的时候,不理解流程就完全没有排查的方向。
Q:有好用的Markdown转换word或PDF工具吗?
A:我在法律人学Claude|第五期:让Claude用上次抛App——Skills初解中提过,minimax-docx这个工具,可以定制自己的格式,后面可以再深入的分享一下。