ElevenLabs 开源平替爆火,狂揽 2.2 万 Star!
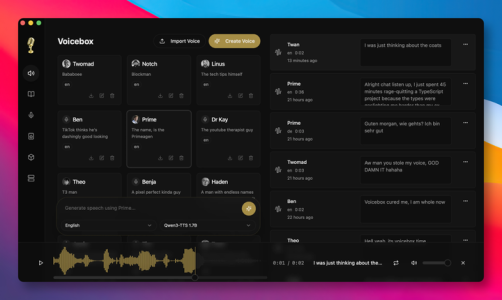
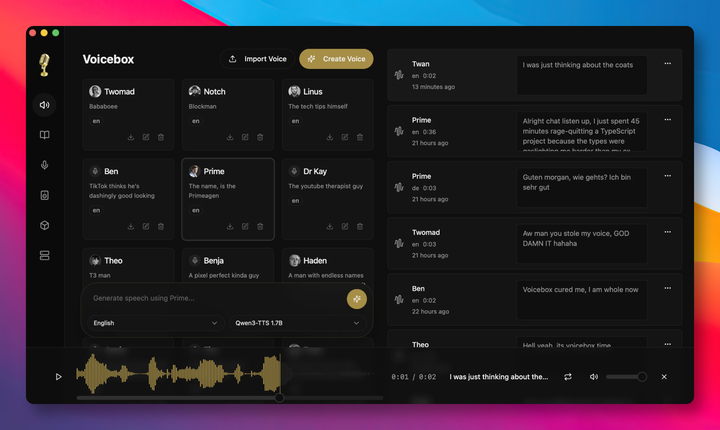
前段时间帮朋友做一档独立播客,需要给两位虚拟嘉宾配音,试了一圈方案,心态有点崩。
用 ElevenLabs 只有几分钟免费额度,对商业项目来说,更重要的是隐私问题。
于是在 GitHub 上找到了 Voicebox ,已斩获了 22000+ Star 的开源免费工具。
作者给它的定位很直接,一个本地优先的声音克隆工作站,定义为 ElevenLabs 的开源替代。

但真正打动我们的,声音数据、模型权重,全留在本地电脑,不经过任何云端。
而且把开源社区里最能打的 7 款 TTS 引擎,全部集成到同一个桌面端里,可按场景灵活切换。
多语种主力是 Qwen3-TTS,支持中英日韩等 10 种语言,还能给指令让模型「说慢一点」。
Chatterbox Multilingual 则覆盖 23 种语言,连阿拉伯语、斯瓦希里语都有。
英文专精则有轻量的 LuxTTS,1GB 显存就能跑。
预设音色路线里,Kokoro 内置了 50 个精选人声,模型只有 82M,CPU 直接起飞。
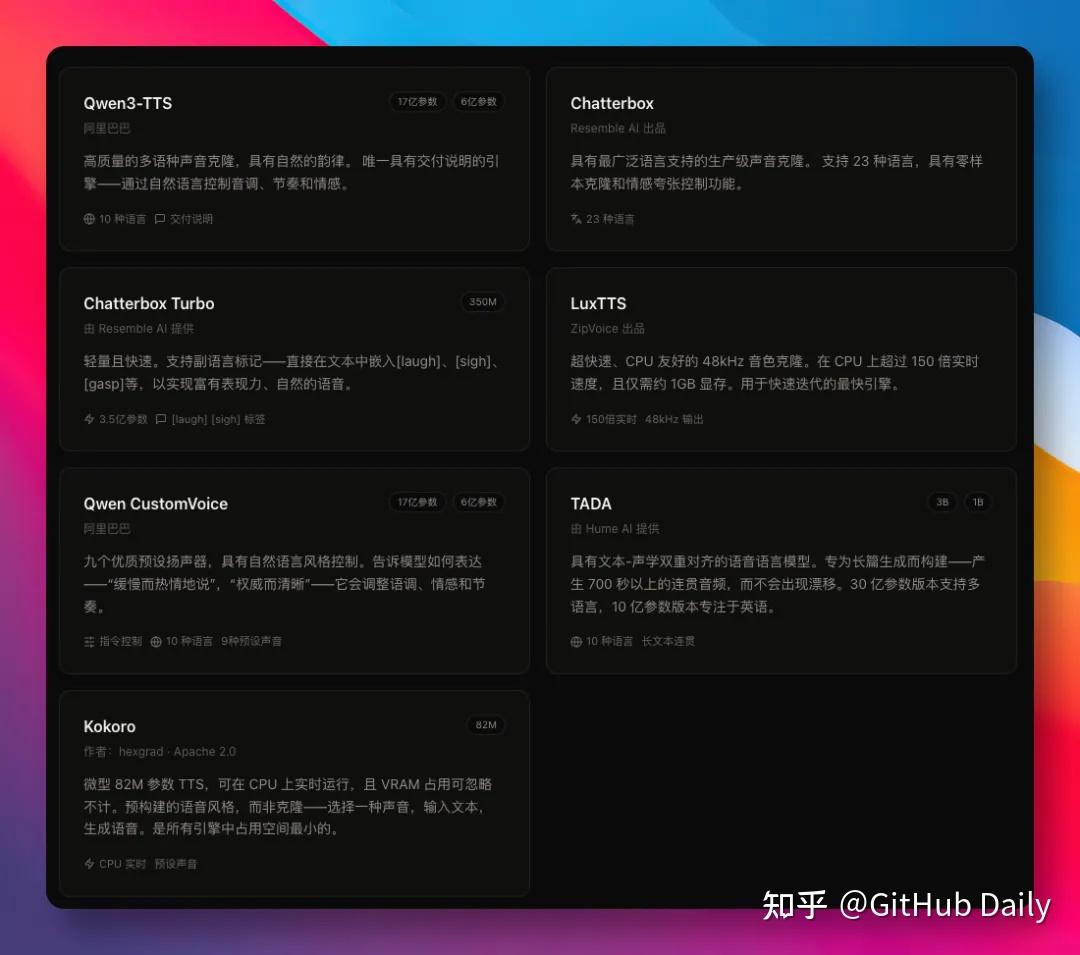
功能层面最惊喜的,是 Chatterbox Turbo 那套副语言标签。
在输入框里打个 /,就能插入 [laugh]、[sigh]、[gasp] 这些标记。
生成出来的语音,真的会在对应位置出现笑声、叹气。
以前做播客要靠剪辑师后期贴音效,现在一行提示词就搞定。
光克隆还不够,后期处理也得专业。
Voicebox 把 Spotify 的 pedalboard 音频库集成了进来,提供变调、混响、延迟、压缩等 8 种效果器。
自带 4 个预设(机器人音、收音机音、回声室、深沉男声),每个语音资料还能绑定默认效果链,生成即带效果。
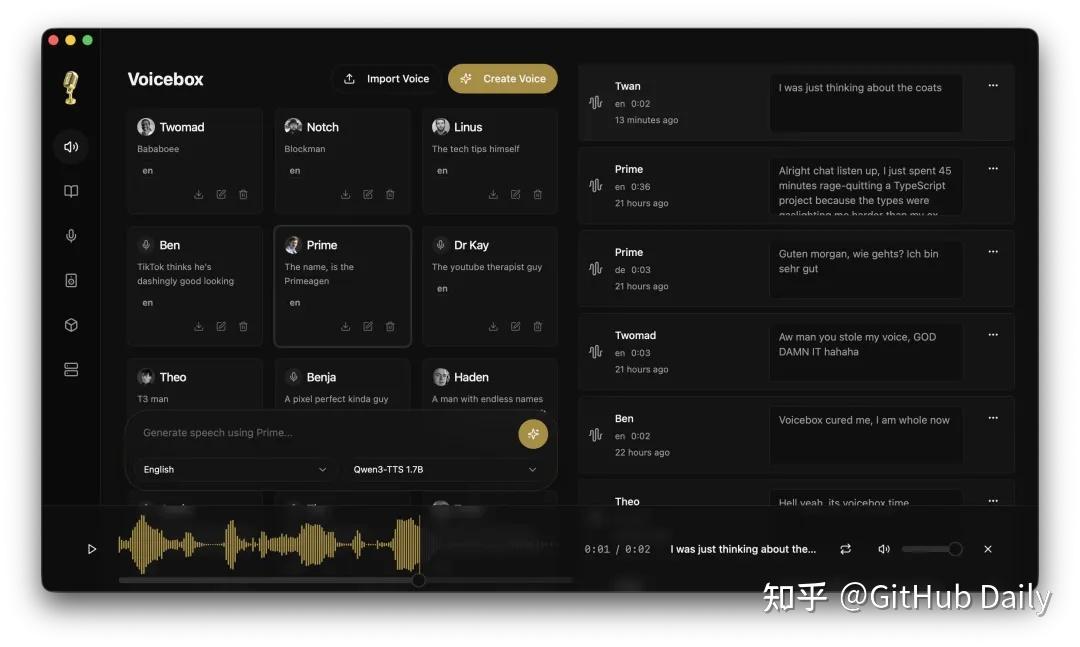
长文本这块,最长能生成 50000 字符,自动按句子边界切分。
再用 0 到 200 毫秒的淡入淡出拼接,做有声书、整集播客脚本,丢进去就能跑。
多人对话场景则有 Stories 编辑器,多轨时间线加拖拽剪辑,操作逻辑跟 DAW 一样顺手。
性能方面,Apple Silicon 吃 MLX 后端调用 Metal 加速,比 CPU 快 4 到 5 倍。
NVIDIA 走 CUDA,AMD 走 ROCm,Intel Arc 走 IPEX/XPU,显卡选择很宽松。
底层是 Tauri + Rust,没走 Electron,安装包和内存占用都很克制。
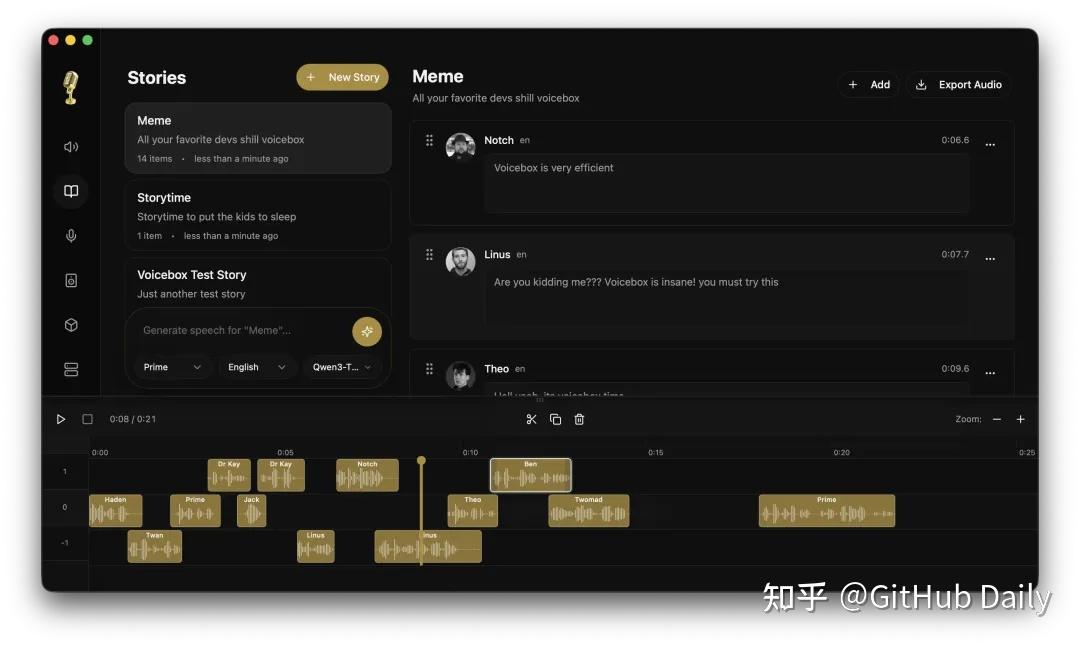
对开发者来说,还有个隐藏好东西:完整的 REST API。
装好后本地会起一个 17493 端口的服务,curl 命令就能生成语音。
游戏动态对白、无障碍朗读、播客自动化流水线,都能直接接上。
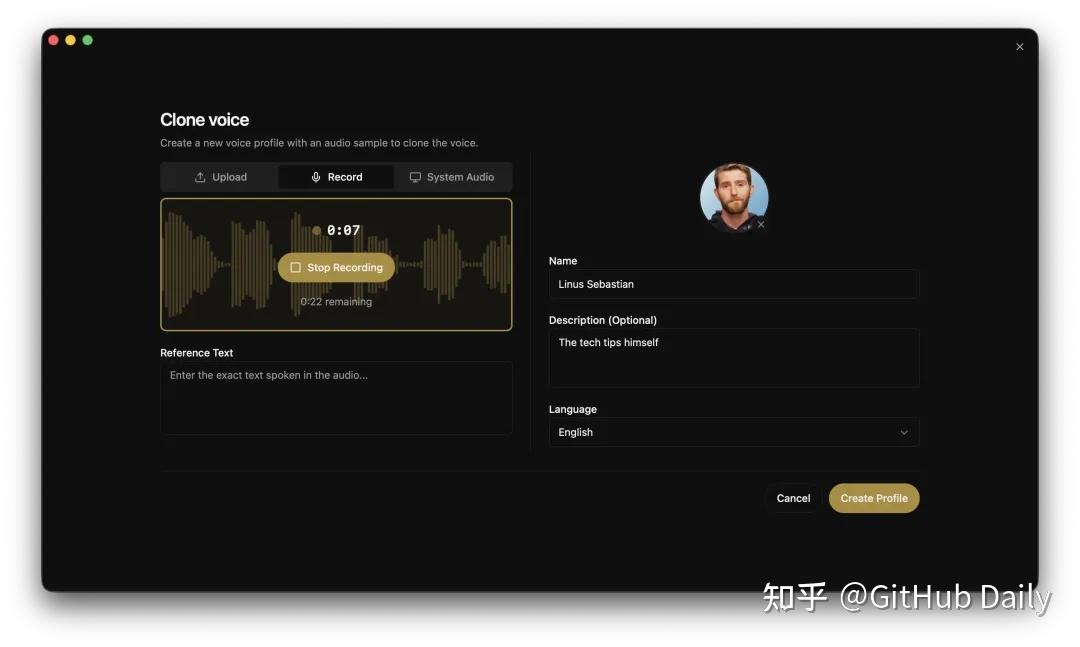
安装过程比较省心,macOS 和 Windows 都有打包好的安装包,到 Releases 页面下载 dmg 或 msi 即可。
Linux 目前还没预编译二进制,需要参考官方文档从源码构建,Docker 方案也支持。
第一次启动会下载模型权重,Kokoro 只有 82M,Qwen3-TTS 要几个 G,建议按需下载。

写在最后
过去一年多,TTS 领域迎来了几次关键突破,Qwen3-TTS、Chatterbox、Kokoro、HumeAI TADA 相继开源。
端侧推理框架 MLX 让 Apple Silicon 跑大模型成为常态,能力侧的零件其实早就齐了。
但开源 TTS 生态一直有个断层:模型在 Hugging Face,权重分散在各个仓库。
能跑起来的是会配 Python 的工程师,真正需要声音的创作者反而用不上。
Voicebox 的价值,就是把这层断层补上了。
它让声音合成从命令行工具,变成了一个像 Logic Pro、像 Figma 那样的生产力工具。
这也是为什么它能在短时间内攒到 22000+ Star,社区一直在等这样一个整合者。
本地化加免订阅加一站式这条路,大概率会成为 2026 年开源 AI 工具的主流形态。
云端订阅服务的护城河,正在被一个个这样的项目慢慢填平。
GitHub 项目地址:https://github.com/jamiepine/voicebox
今天的分享到此结束,感谢大家抽空阅读,我们下期再见,Respect!