本地大模型+知识库大功告成!让知识库可以存知识!fastgpt部署m3e嵌入模型
① GPU部署m3e嵌入模型
② 接入one API中
③ 接入知识库,让它们相认!
④ 塞知识库进去测试!
第一部分:GPU部署m3e嵌入模型
为什么用GPU部署?
快得简直不要不要的!实测跑m3e大概需要1.5G显存,加上GLM3的5G!8G显存的卡,也能玩得飞起!
打开命令行!之后他会自动下载镜像,并且在docker上运行!
docker run -d -p 6008:6008 –gpus all registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api:latest
这里解释一下代码!因为使用了GPU部署,所以我们加了一个GPU选项!否则他默认是CPU启动,这样的话不稳定,而且速度上差很多!
docker run:这是Docker命令,用于启动一个新容器。
-d:这是一个选项,表示以分离模式(detached mode)运行容器。这意味着容器将在后台运行,并且不会阻塞当前终端。
-p 6008:6008:这是一个端口映射选项,表示将容器内的6008端口映射到宿主机的6008端口。这样,我们可以通过访问宿主机的6008端口来访问容器内的服务。
–gpus all:这是一个选项,表示启用所有可用的GPU资源。这样,容器可以将GPU资源全部用于加速计算任务。
附:Docker部署One API
- 在Windows的终端中输入如下代码:
docker run --name oneapi -d --restart always -p 13000:3000 -e TZ=Asia/Shanghai -v /home/ubu第二部分:接入one API
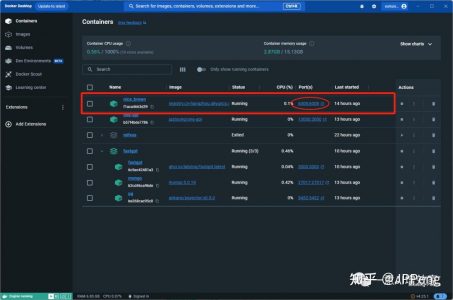
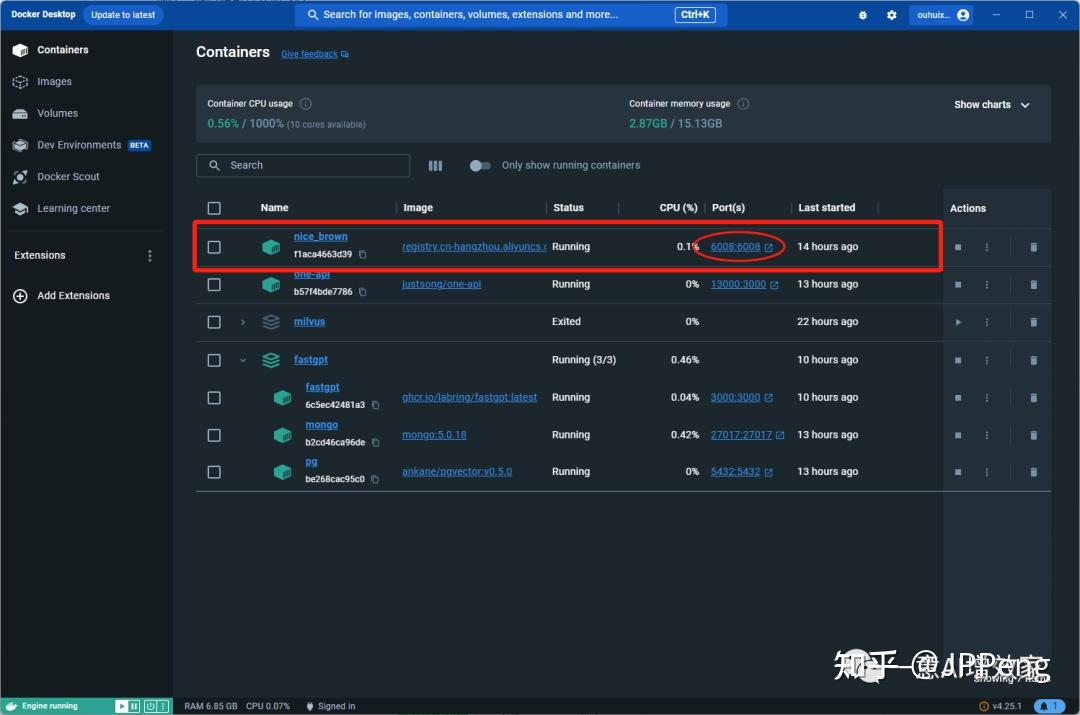
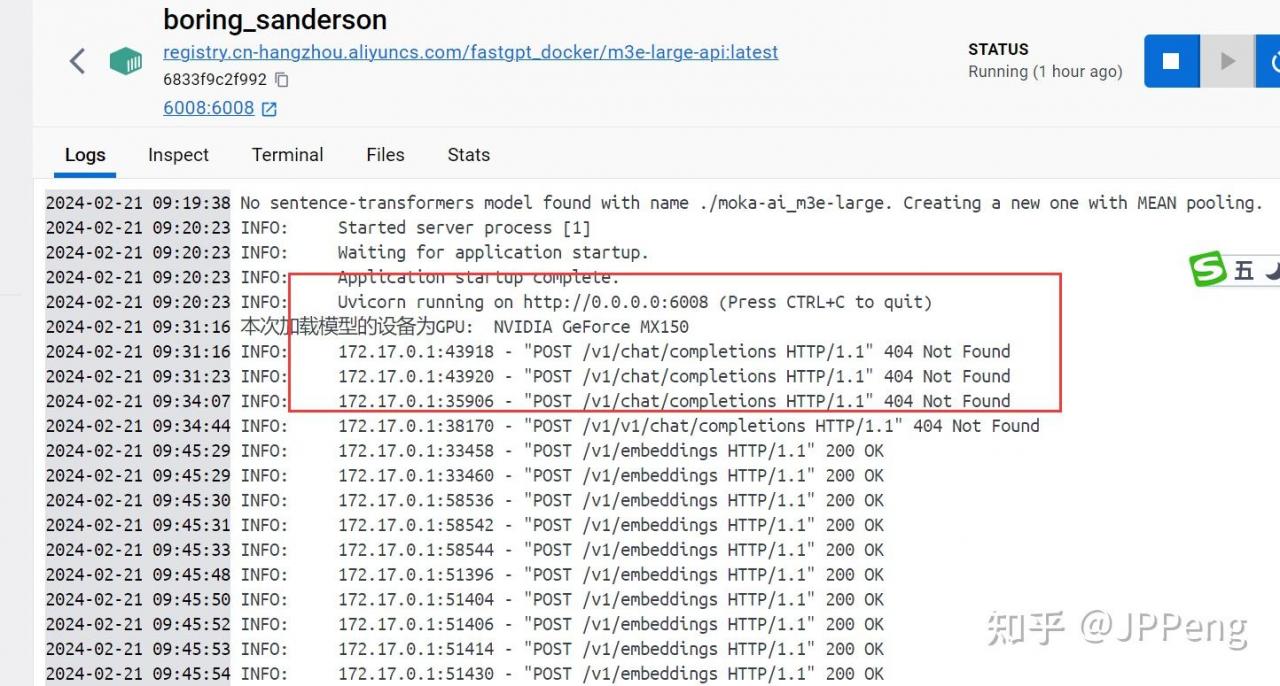
我们看上图,已经成功在6008端口部署成功了!
切记,不要跟现有的端口有冲突,如果有冲突的话,需要改一下!
现在,接入到one api中转站里!
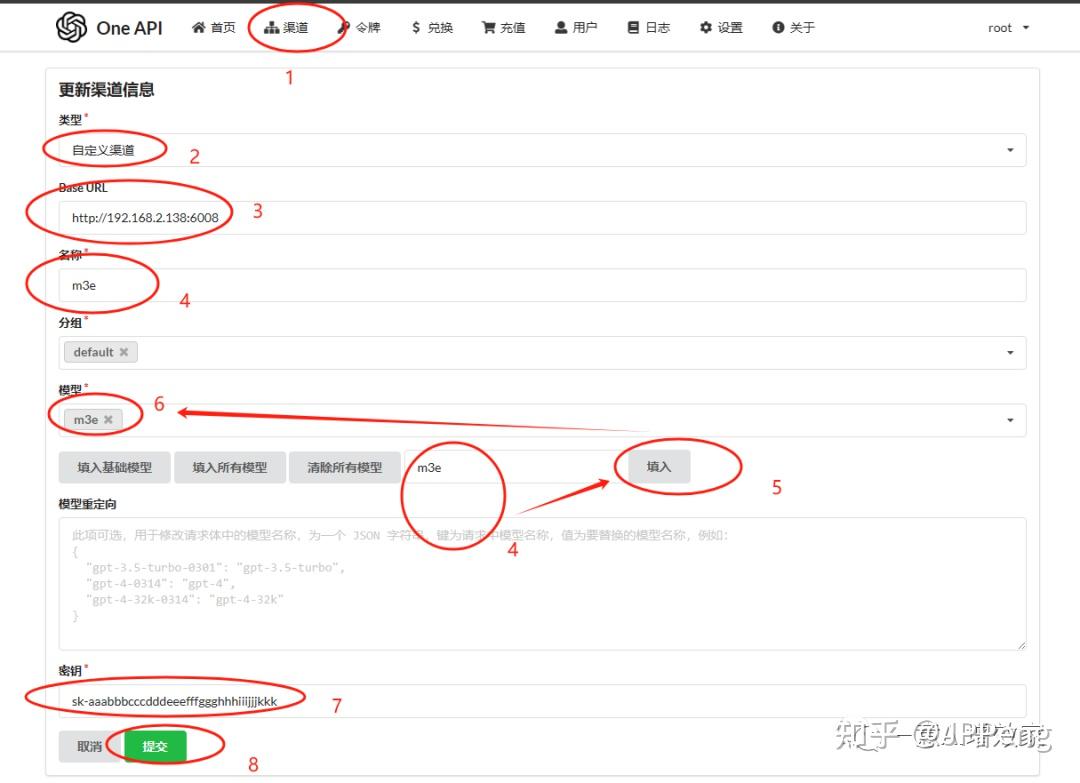
登录打开one api管理界面!按照这个配置填好!提交!
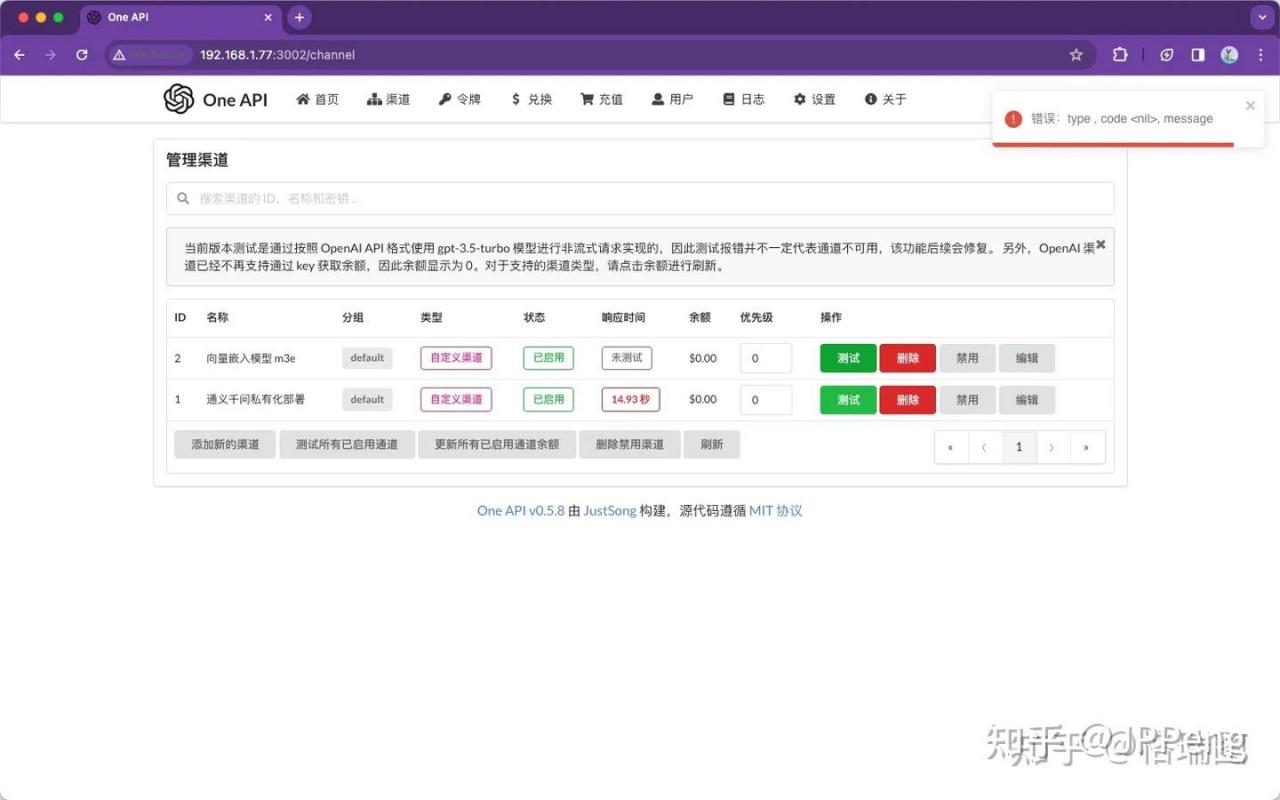
OneAPI测试服务通道会报错,但可以通过M3E运行的Docker容器去看,发现已接收到相应的请求。可调用过来,但由于不是对话生成模型(/v1/chat/completions)所以会 404。
第三部分:接入知识库
上面我们配置好了!我们要让知识库能顺利调用它!还需要改改文件!
不然,知识库不知道怎么调用这个嵌入模型!
我们打开fastgpt的配置文件!还记得在哪吗?
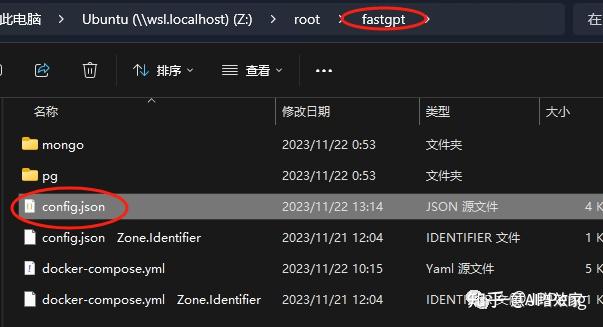
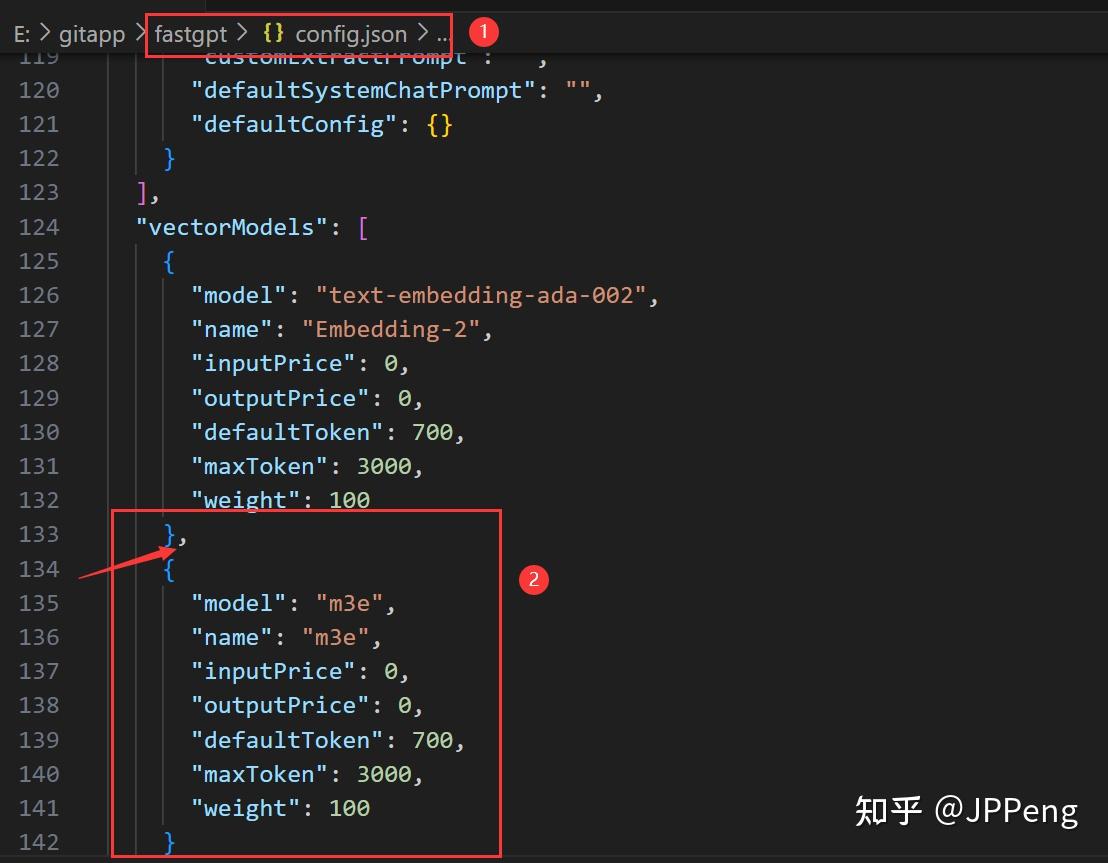
直接复制原先的,粘贴新建!改为m3e!
注意这个小逗号啊!如果你这个逗号少了,那这个配置文件就失效了!
保存!在docker上重启!【重启fastgpt对应的docker容器就可以了】
第四部分:塞知识库进去测试!
重启之后,我们打开docker上fastgpt的端口,自动跳转到登录页面!
输入账号密码!登录!
现在先跟着创建知识库!测试!
如果你在这一步,看不到m3e的选项,那肯定是配置文件写错了!
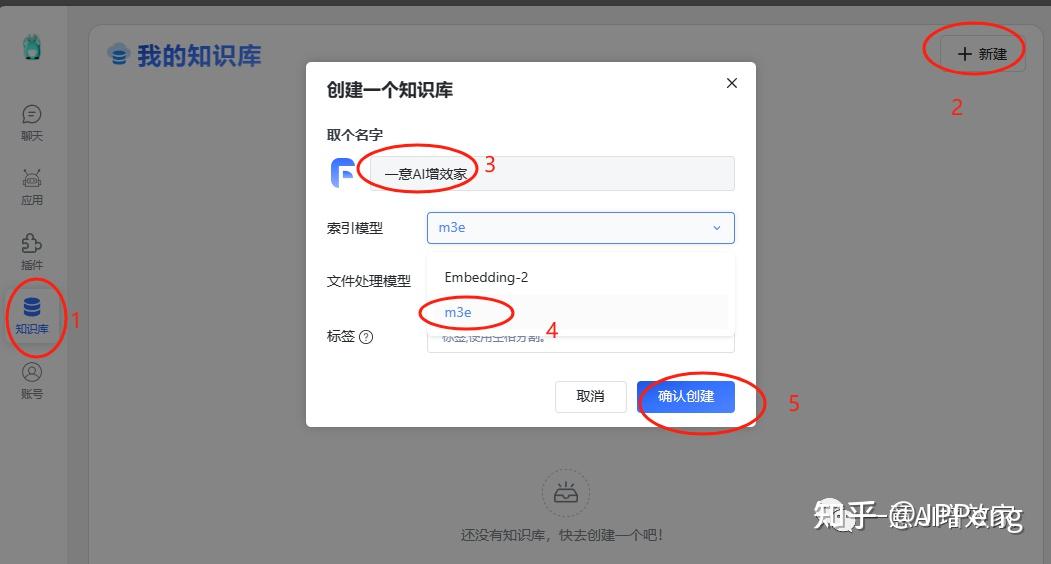
创建成功后,我们就可以上传文件了!
确定导入之后!我们看到这个速度非常快!都是因为使用了GPU部署,两秒钟搞掂!
现在去测试一下吧!
到这里!我们的知识库和大模型已经部署完成了!
下一步,我们要开始搭建属于自己的知识库进去!
最后输出到微信/网页上提供服务!
也许你会遇到很多问题!请坚持下去!
原文链接:完全体!本地大模型+知识库大功告成!让知识库可以存知识!fastgpt部署m3e嵌入模型!20/45_将自己的一篇文档转换为gpt能识别的知识库-CSDN博客
【超详细】纯本地部署的FastGPT知识库教程(基于ChatGLM3+m3e+oneapi)_哔哩哔哩_bilibili