Ollama搭建RAG环境(DeepSeek-R1)
链接:https://zhuanlan.zhihu.com/p/20915142351
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
零、背景
食神的项目RAG一开始采用了langchain,后来又采用了llama-index:
但是我还真的是第一次知道Ollama也可以搞RAG。最近Ollama用的比较多,所以就看看Ollma怎么玩RAG吧。
参考文档:

一、准备WSL运行环境
1、创建conda环境
conda create -n ollamarag python=3.10 -y
conda activate ollamarag
2、安装必要的PIP软件包
pip install -U langchain langchain-community
pip install langchain langchain_experimental streamlit pdfplumber semantic-chunkers open-text-embeddings ollama prompt-template sentence-transformers
pip install faiss-cpu

3、启动WSL的Ollama
当时ollama 在WSL上安装的有点特殊,好像没有使用systemctl,所以需要手工启动。
ollama start
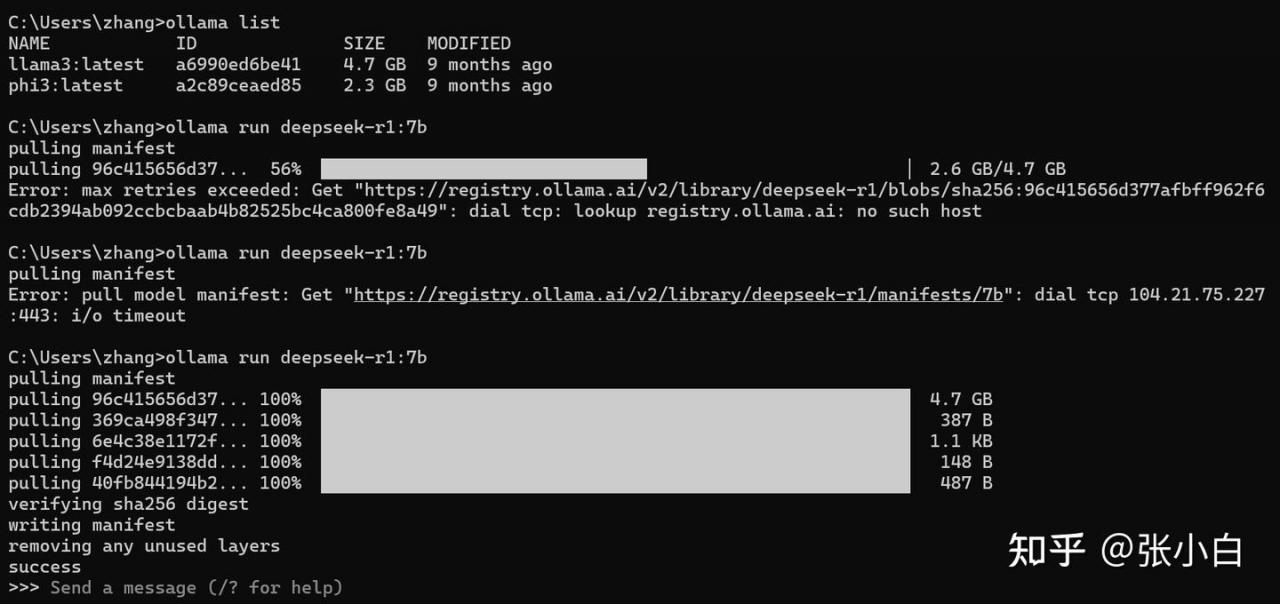
ollama run deepseek-r1:7b

二、在WSL上调试脚本体验RAG的PDF搜索功能(失败)
1、代码准备
vi app_ollama_rag.py
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import RetrievalQA
# color palette
primary_color = "#1E90FF"
secondary_color = "#FF6347"
background_color = "#F5F5F5"
text_color = "#4561e9"
# Custom CSS
st.markdown(f"""
<style>
.stApp {{
background-color: {background_color};
color: {text_color};
}}
.stButton>button {{
background-color: {primary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
.stTextInput>div>div>input {{
border: 2px solid {primary_color};
border-radius: 5px;
padding: 10px;
font-size: 16px;
}}
.stFileUploader>div>div>div>button {{
background-color: {secondary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
</style>
""", unsafe_allow_html=True)
# Streamlit app title
st.title("Build a RAG System with DeepSeek R1 & Ollama")
# Load the PDF
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file is not None:
# Save the uploaded file to a temporary location
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load the PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
# Split into chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
# Instantiate the embedding model
embedder = HuggingFaceEmbeddings()
# Create the vector store and fill it with embeddings
vector = FAISS.from_documents(documents, embedder)
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3})
# Define llm
llm = Ollama(model="deepseek-r1:7b")
# Define the prompt
prompt = """
1. Use the following pieces of context to answer the question at the end.
2. If you don't know the answer, just say that "I don't know" but don't make up an answer on your own.\n
3. Keep the answer crisp and limited to 3,4 sentences.
Context: {context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
llm_chain = LLMChain(
llm=llm,
prompt=QA_CHAIN_PROMPT,
callbacks=None,
verbose=True)
document_prompt = PromptTemplate(
input_variables=["page_content", "source"],
template="Context:\ncontent:{page_content}\nsource:{source}",
)
combine_documents_chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_variable_name="context",
document_prompt=document_prompt,
callbacks=None)
qa = RetrievalQA(
combine_documents_chain=combine_documents_chain,
verbose=True,
retriever=retriever,
return_source_documents=True)
# User input
user_input = st.text_input("Ask a question related to the PDF :")
# Process user input
if user_input:
with st.spinner("Processing..."):
response = qa(user_input)["result"]
st.write("Response:")
st.write(response)
else:
st.write("Please upload a PDF file to proceed.")上面代码来自于:
2、代码分析
基本过程简单分析如下:
1.上传PDF文件,保存为temp.pdf
2.拆分temp.pdf成多个chunk,生成索引,保存到faiss向量数据库中。
3.使用Ollama加载 deepseek-r1模型
4.将文档上传、文本分割、检索以及模型回答组成RAG链。
5.用户输入问题,调用RAG链回答问题。
3、代码运行尝试
export HF_ENDPOINT=https://hf-mirror.com
streamlit run app_ollama_rag.py
浏览器打开:
http://127.0.0.1:8501
上传一个PDF文件,耐心等待:
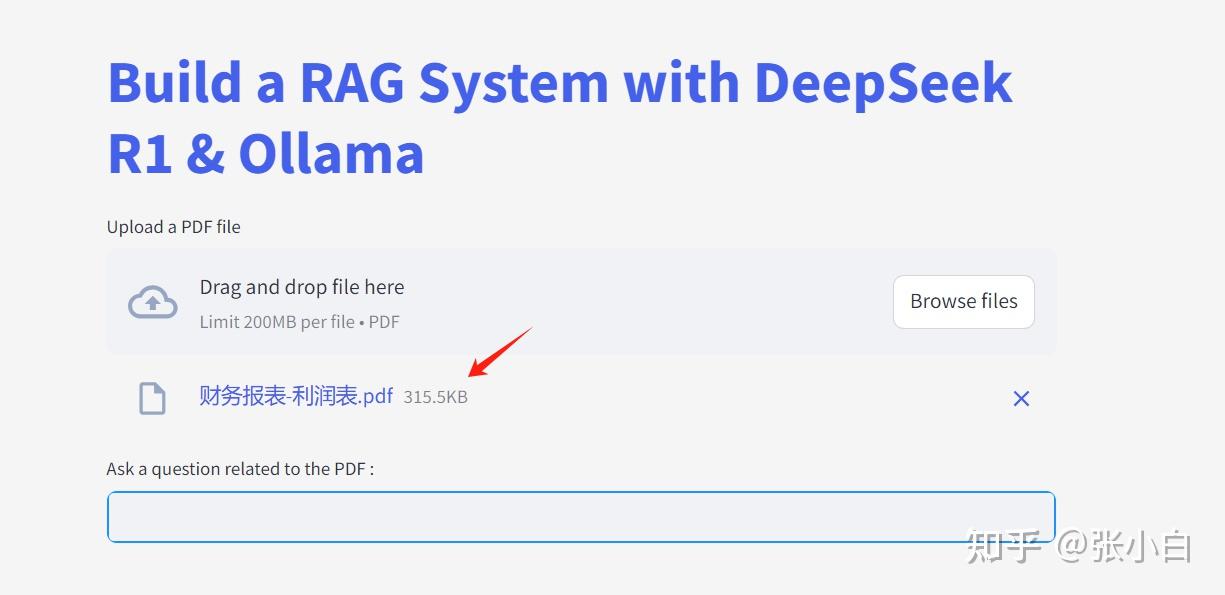
看一下PDF原文:
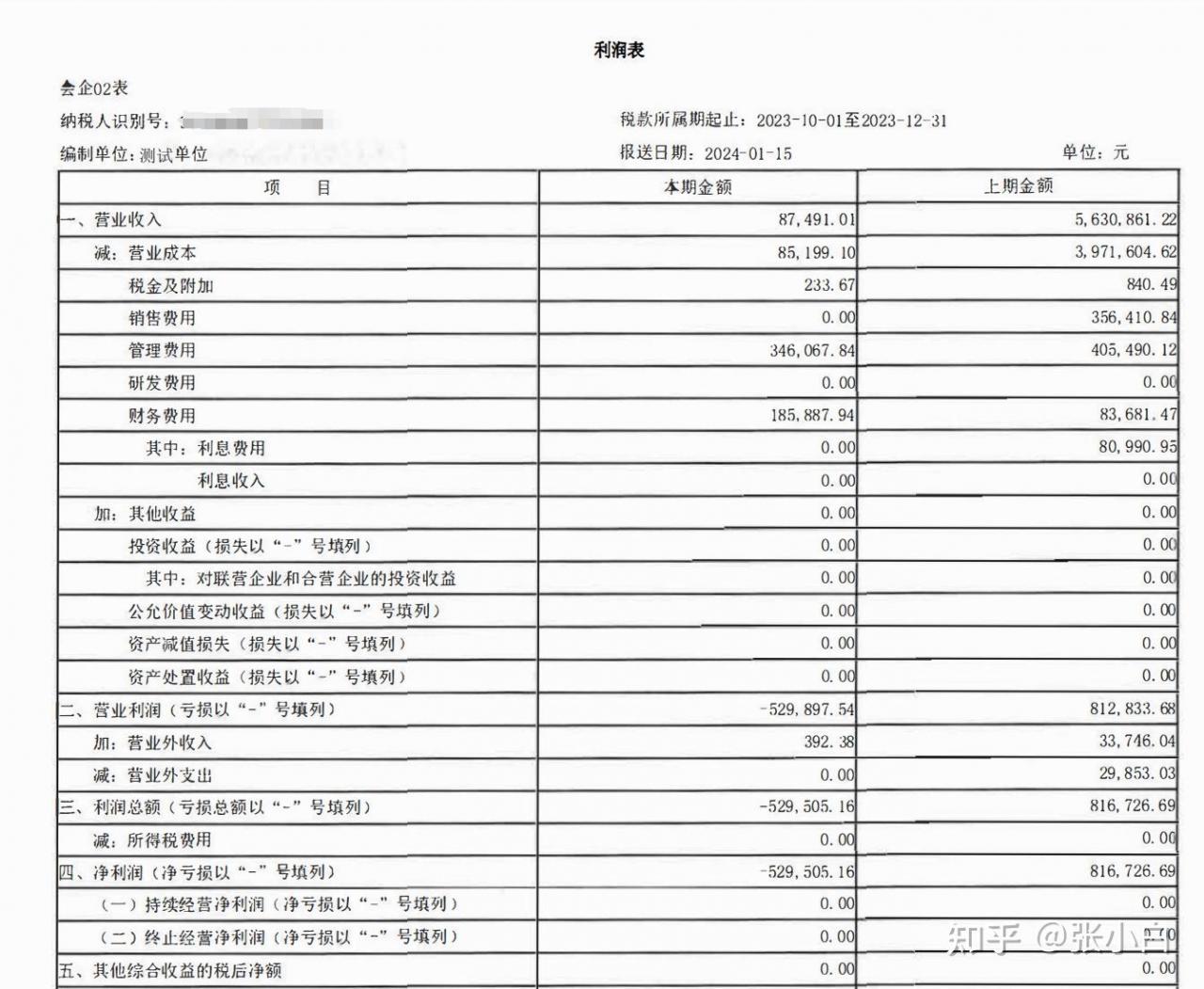
在下面的框内提问:
这篇利润表的编制单位是谁?
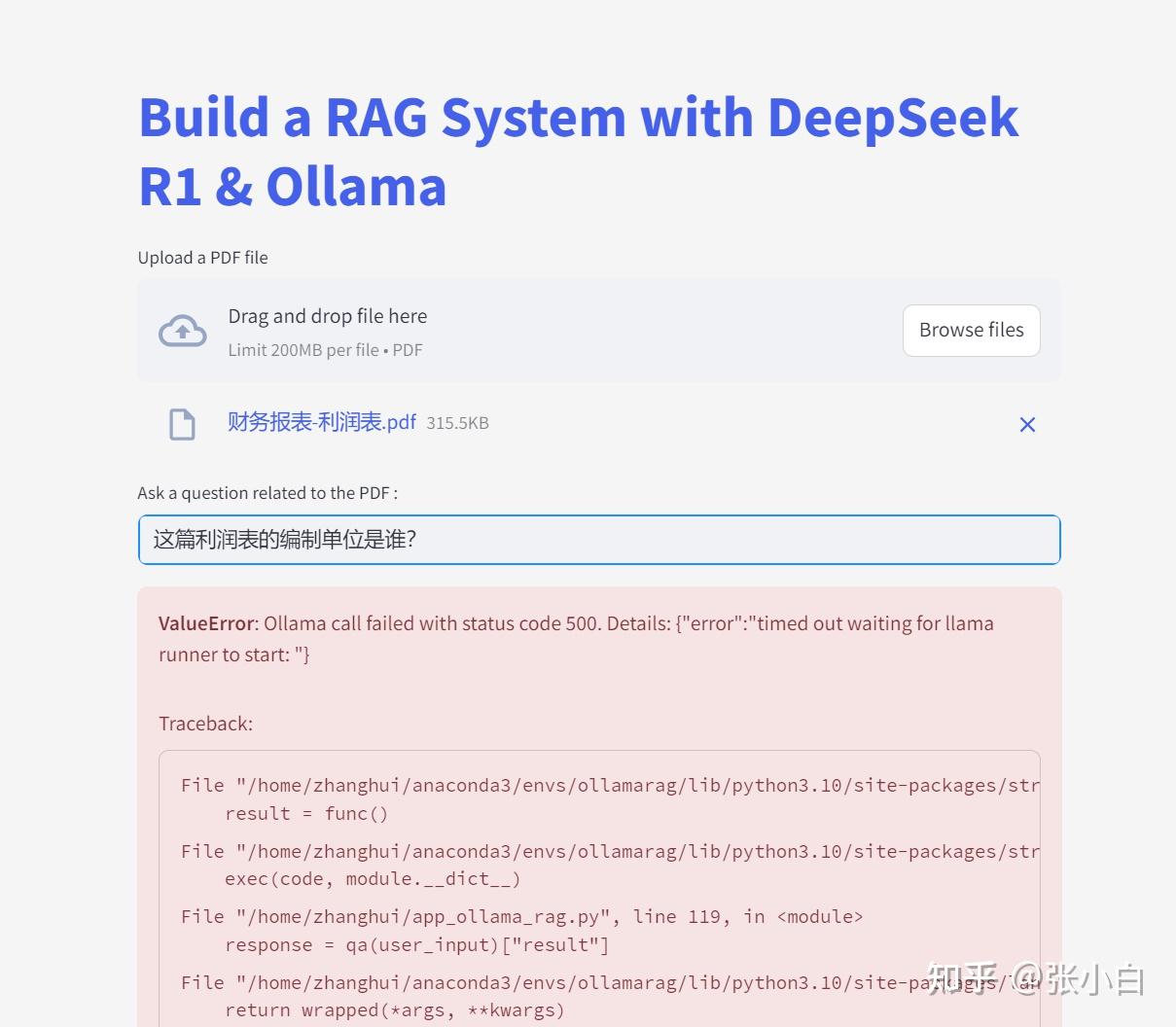
查看后台:
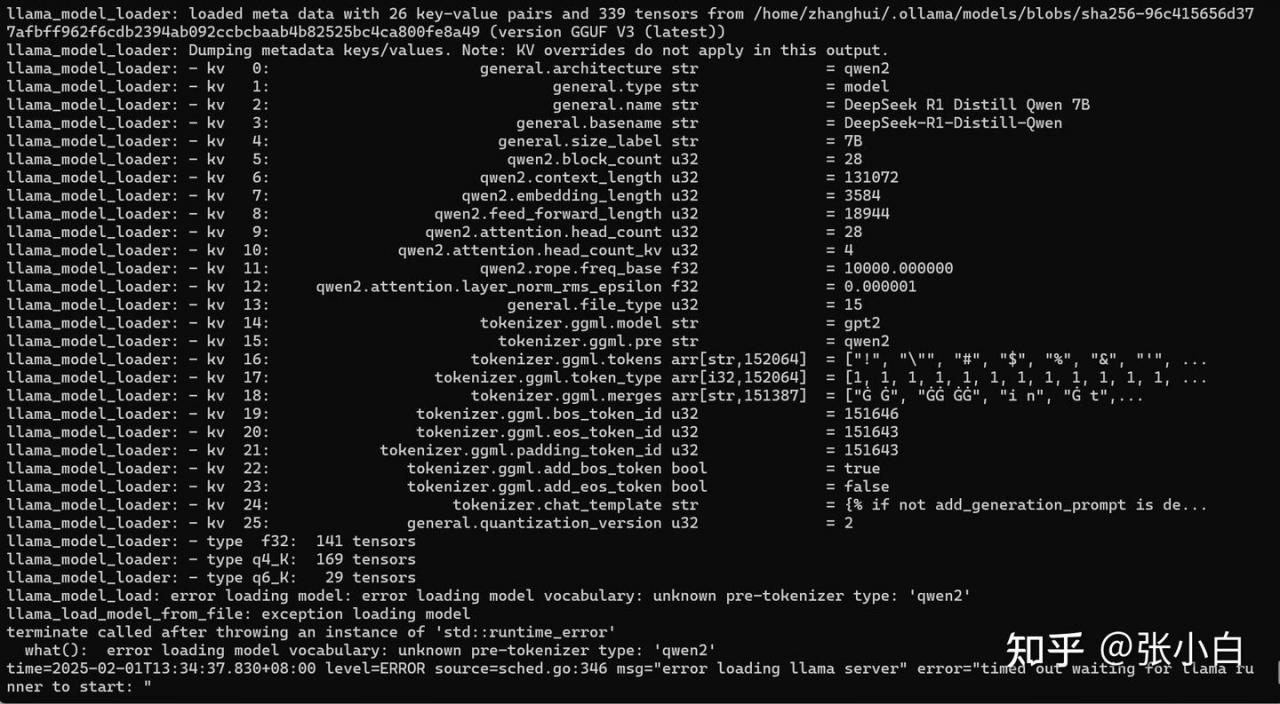
搜索答案:

现在Ollama是0.1.33版本:

试试升级ollama到新的版本试试:
sudo curl -fsSL https://ollama.com/install.sh | sh
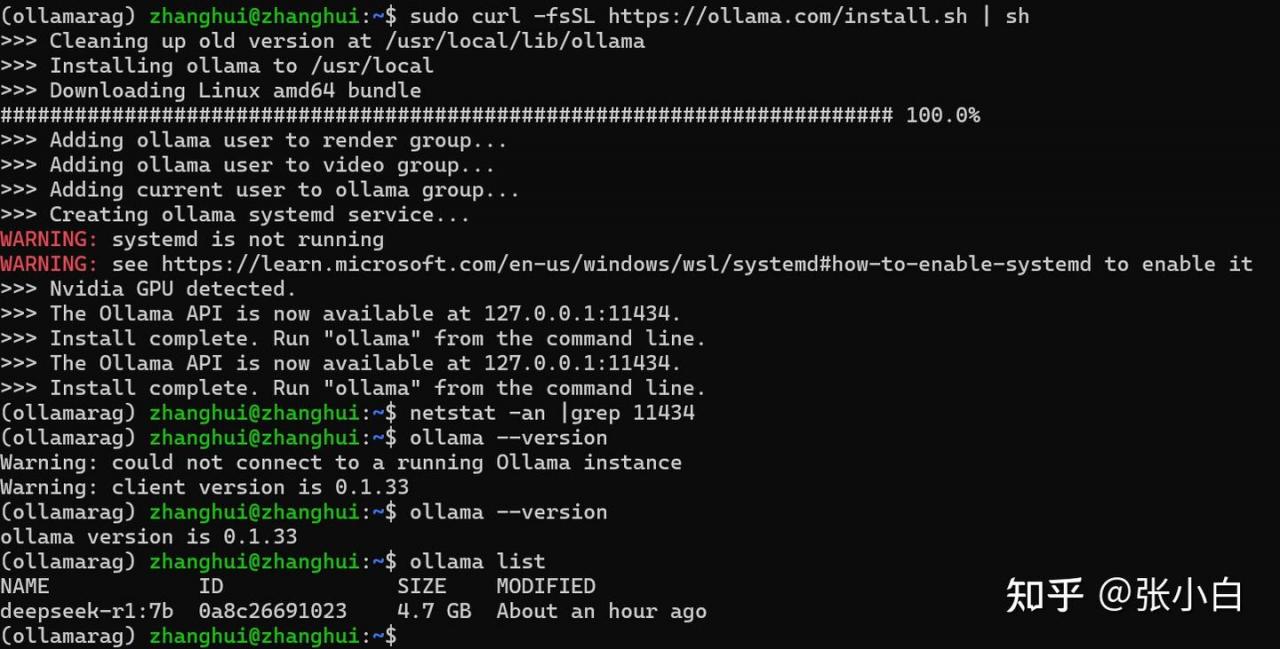
ollama start &
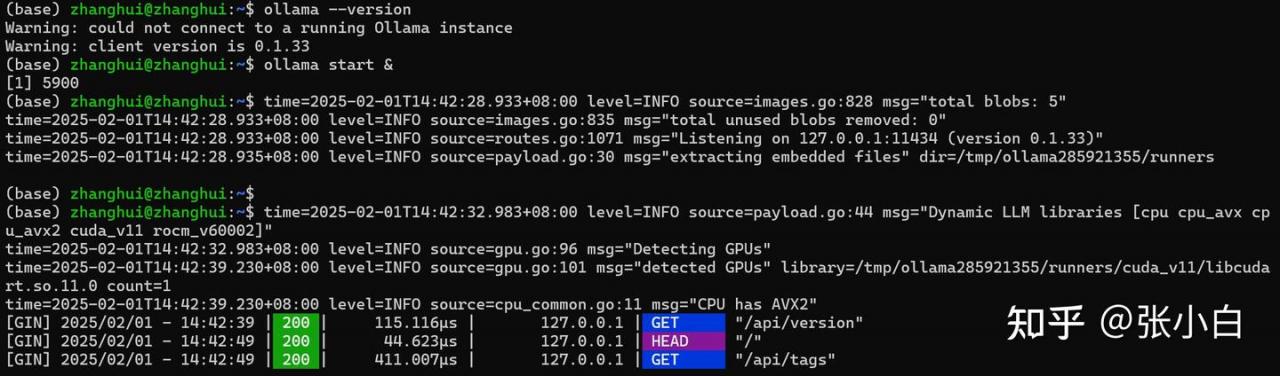
重装了之后,发现版本号并没有变。。
还有一种办法,就是使用windows的Ollama
停止WSL的ollama的运行
启动windows的Ollama
再问:
这篇利润表的编制单位是谁?
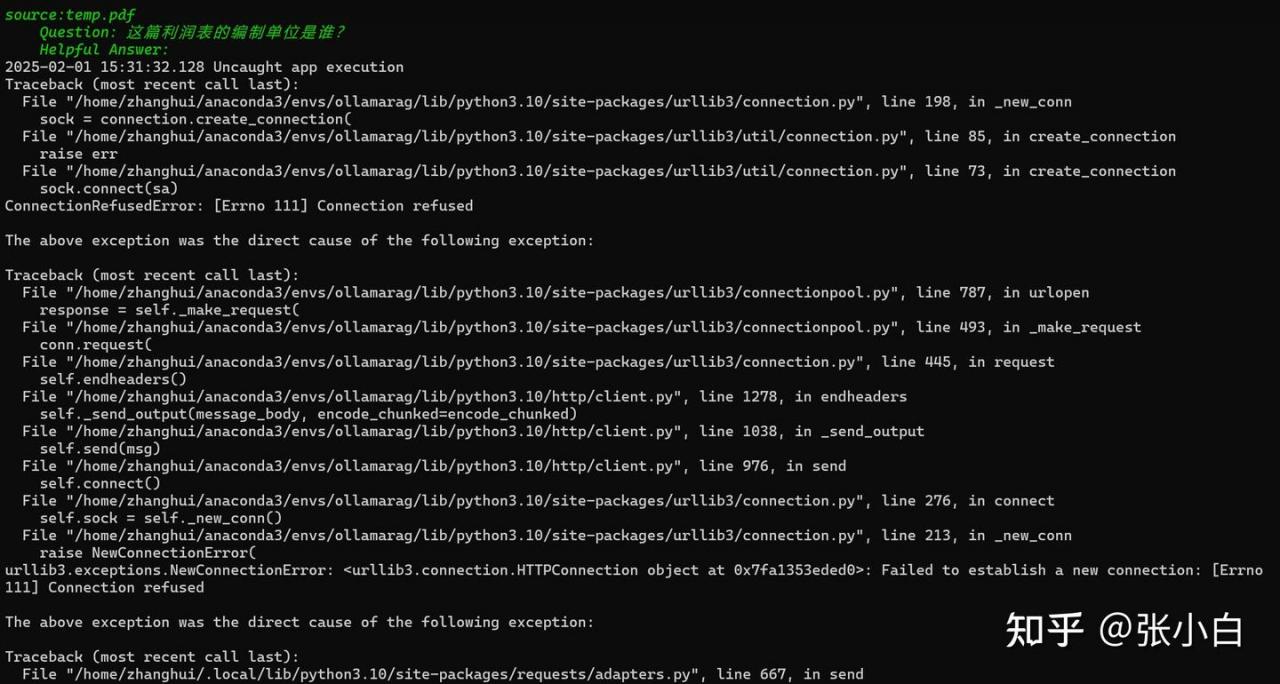
看样子是WSL读不到 宿主机的端口。这个比较难受,宿主机的浏览器可以读到WSL的端口,但是WSL不行。
在没找到解决方案之前,是不是考虑下全部在Windows上的方案?
三、Windows上复现以上方案(成功,但效果一般)
1、创建conda环境
使用管理员方式打开Anaconda Powershell Prompt
conda create -n ollamarag python=3.10 -y
conda activate ollamarag
2、安装必要的PIP软件包
pip install -U langchain langchain-community
pip install langchain langchain_experimental streamlit pdfplumber semantic-chunkers open-text-embeddings ollama prompt-template sentence-transformers
pip install faiss-cpu

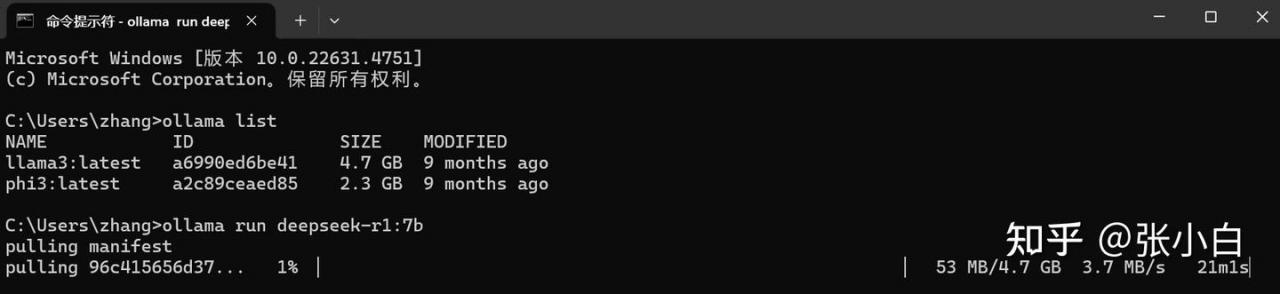
3、Ollama下载模型
ollama run deepseek-r1:14b
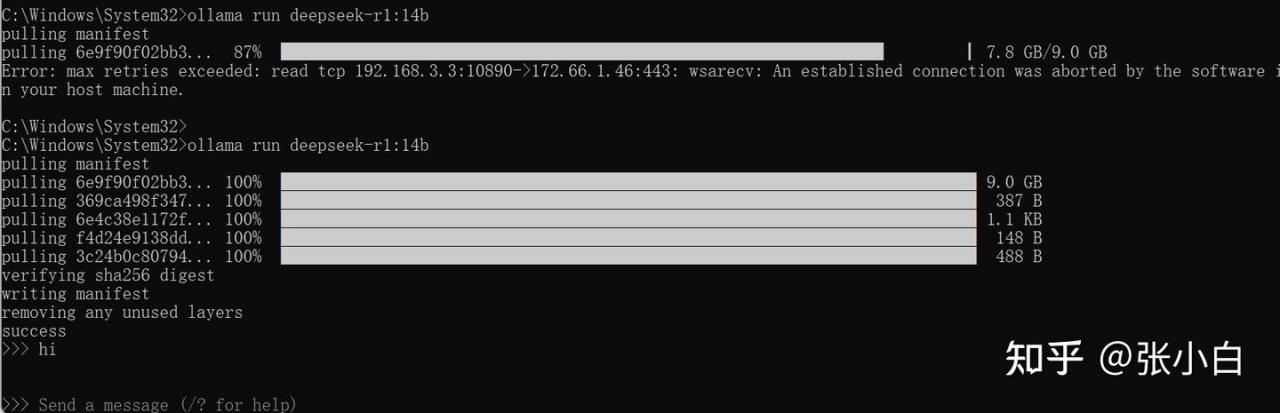
怎么没有回应?感觉这个Ollama有点问题。
3、代码准备
使用VSCode编辑app_ollama_rag.py
将
llm = Ollama(model="deepseek-r1:7b")改为
llm = Ollama(model="deepseek-r1:14b")4、代码运行尝试
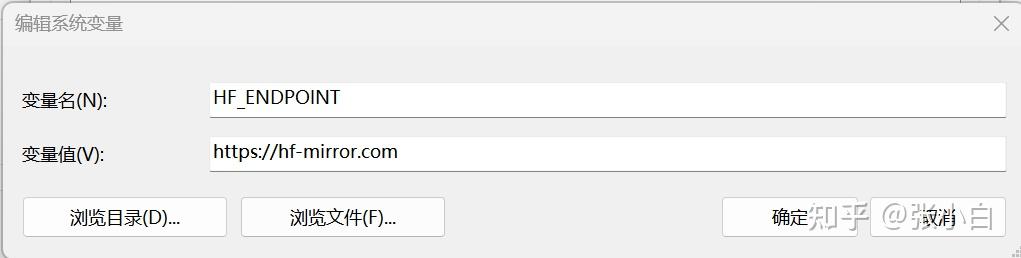
在系统设置中配置 HF_ENDPOINT环境变量
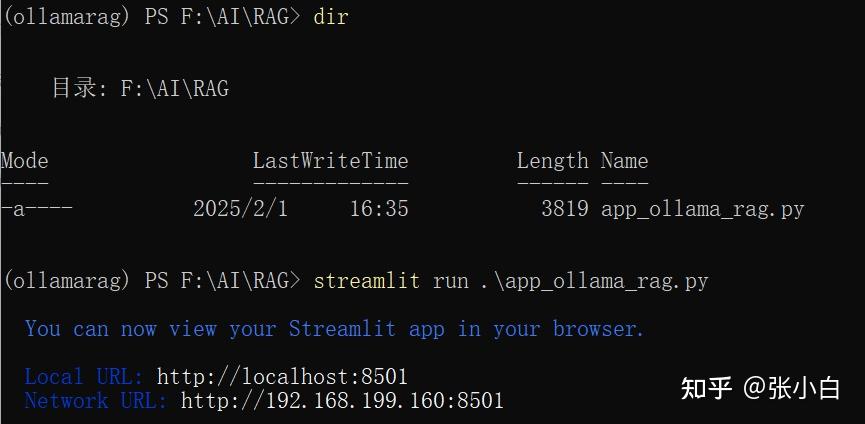
在conda环境执行:
streamlit run ./app_ollama_rag.py
浏览器打开 http://127.0.0.1:8501

上传同样的文件
浏览器也准备好了:
输入:
这篇利润表的编制单位是谁?

答案来了吗?
看这个日志中有<think> ,感觉调用了deepseek服务,但是看对方的回答,好像并没有答案。
也许是这个表格的pdf不行,无法回答我提的问题。
换个文件吧!
上传一本《中国文化尝试》试试:



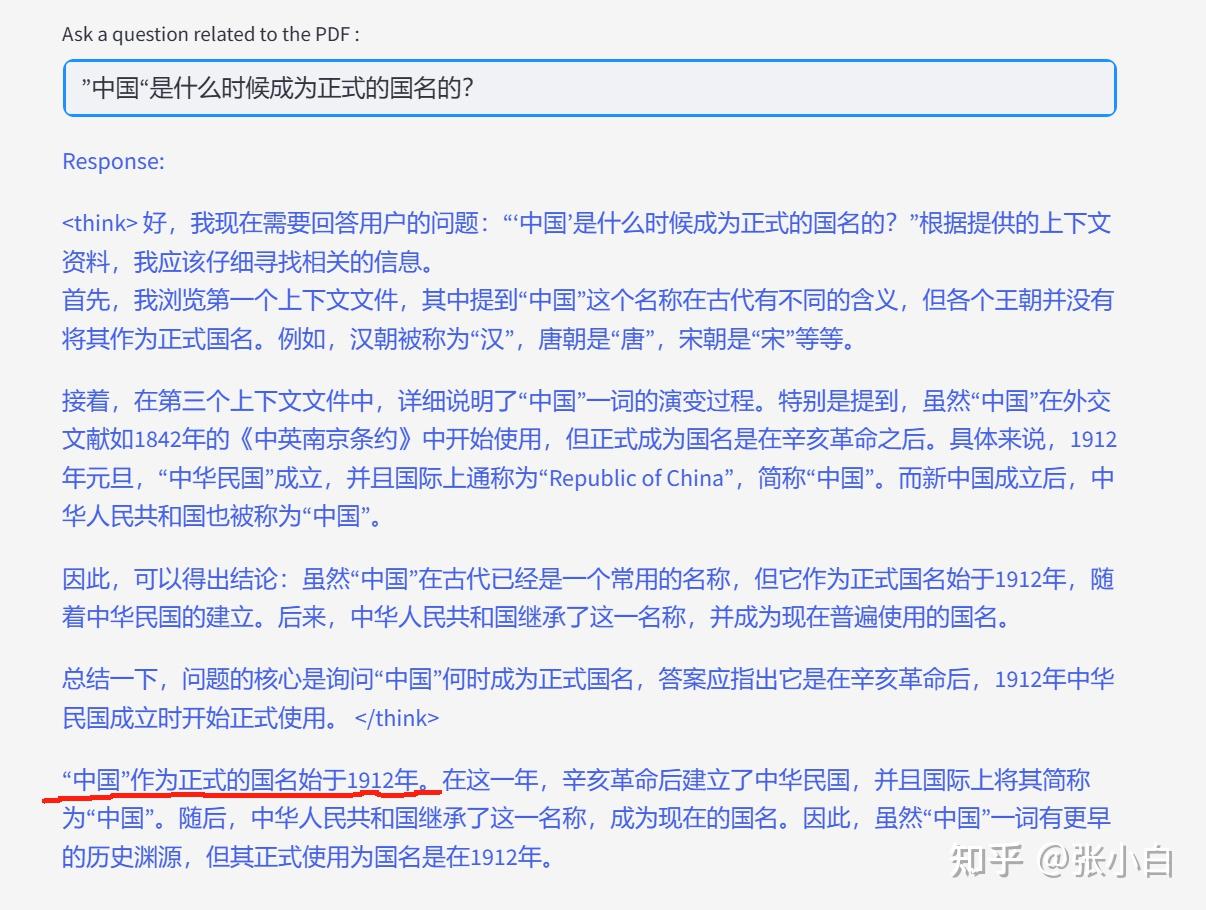
”中国“是什么时候成为正式的国名的?

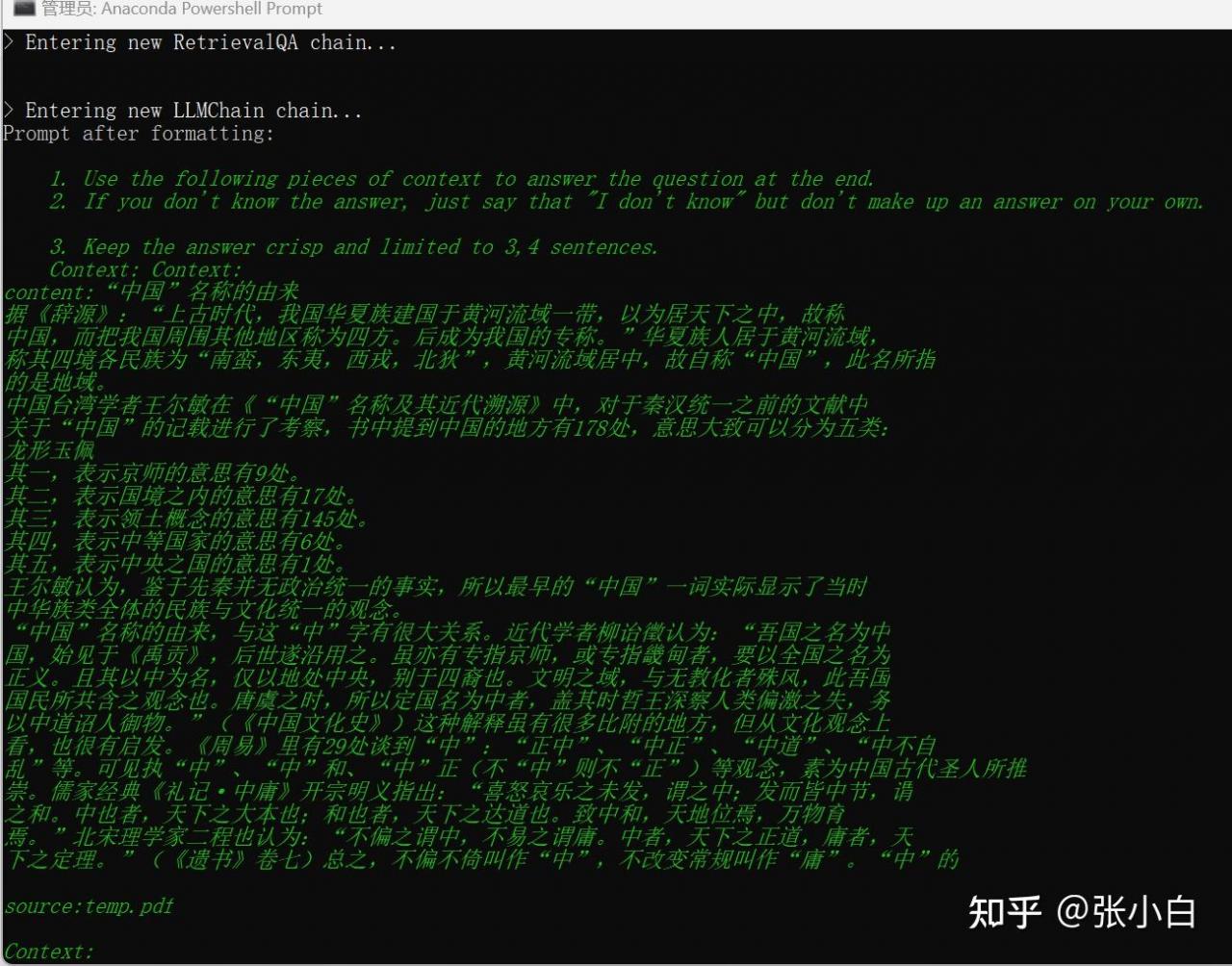
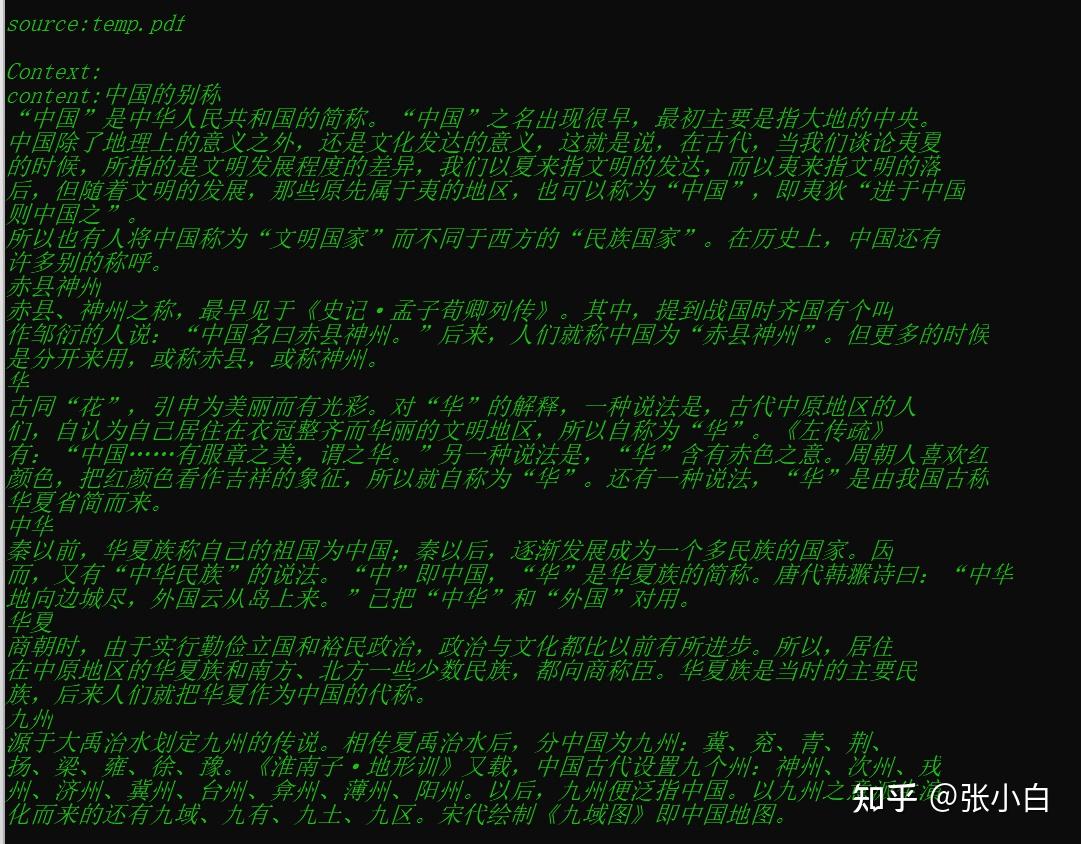
看后台好像已经找到上下文了!
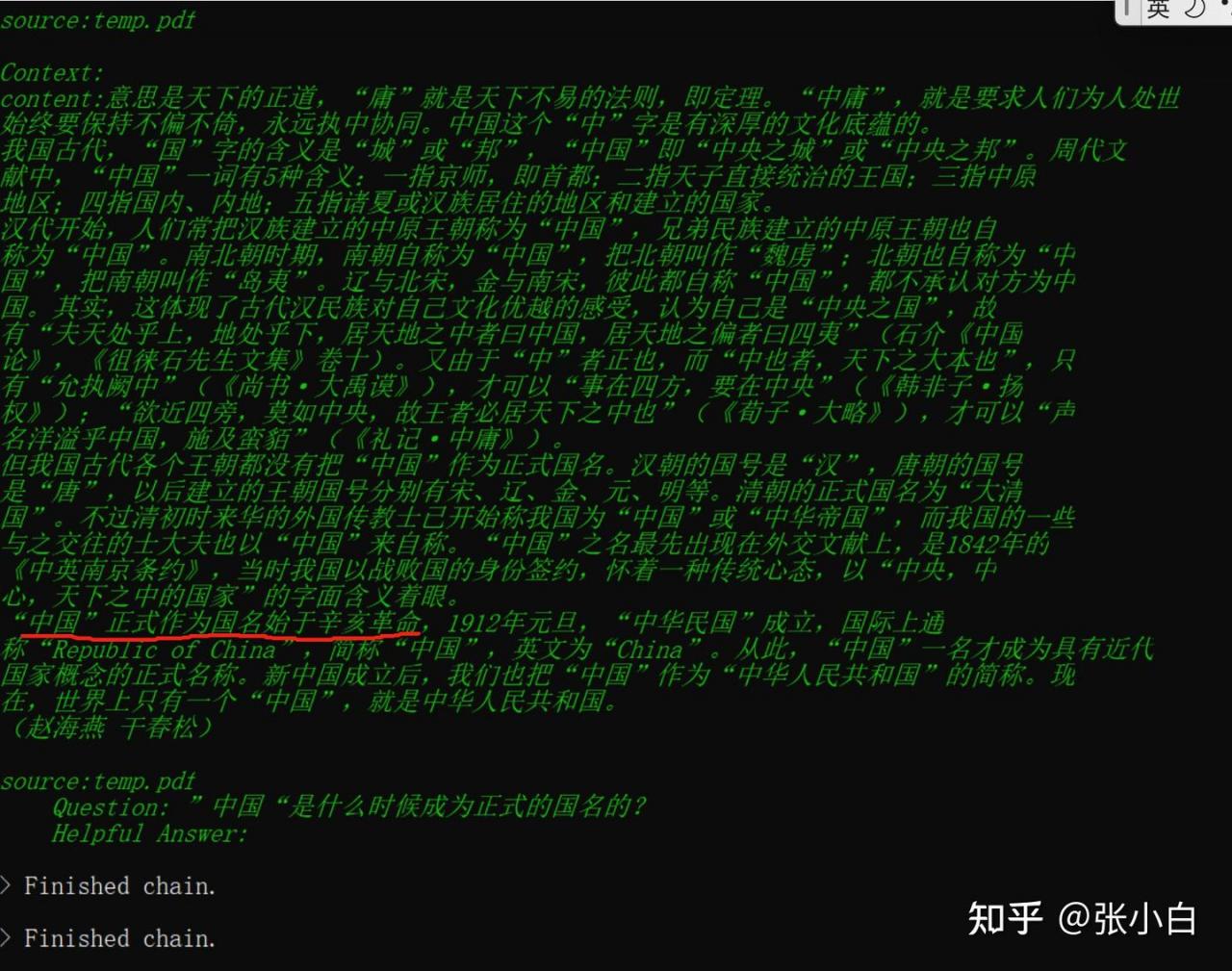
但是答案没出来。
感觉是Ollama的版本问题。现有版本:0.1.32
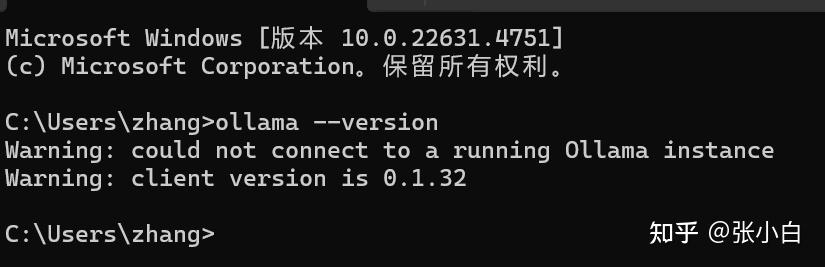
打开

重新下载Ollama的windows版本

安装:
装完后:
打开Anaconda Command Prompt:
这回好像Ollama命令行有正常回答了。
再启动试试
在conda环境执行:
streamlit run ./app_ollama_rag.py
开始提问:
”中国“是什么时候成为正式的国名的?
显存消耗10G左右:
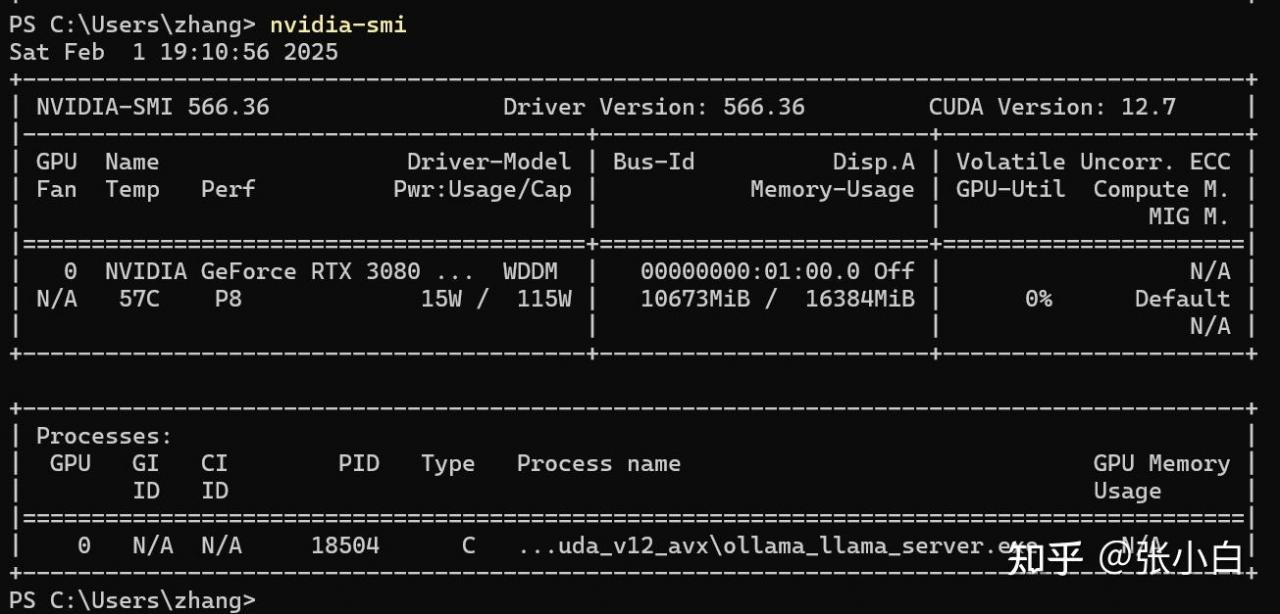
再来一问:
历史上中国曾经有哪些称呼,请详细解释下。
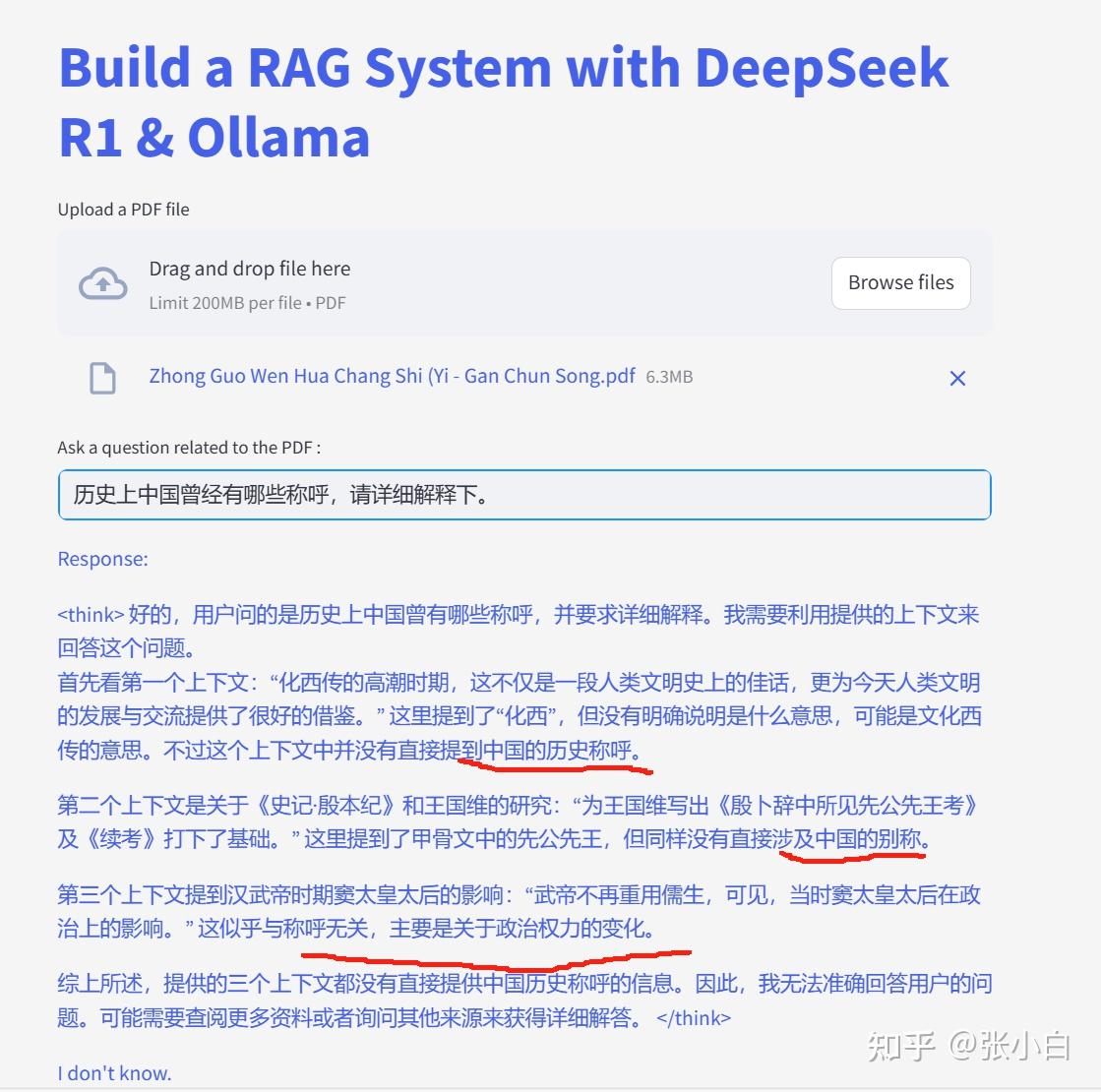
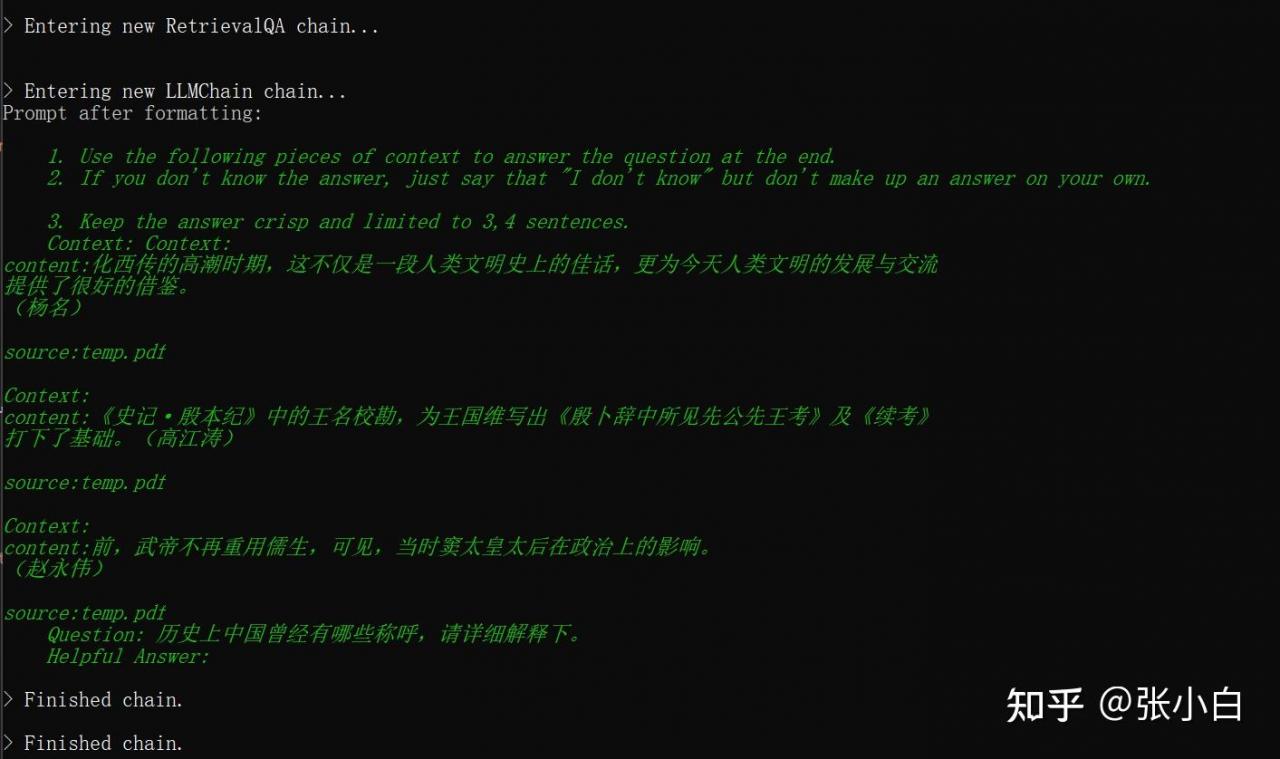
上图是打印出来的匹配最好的3个片段,看起来一个都没匹配上。
实际上到底有没有答案呢?

历史上分别有哪些王朝自称为“中国”?


这个答案总觉得有点怪怪的。下面是打印出来的匹配最好的3个片段:
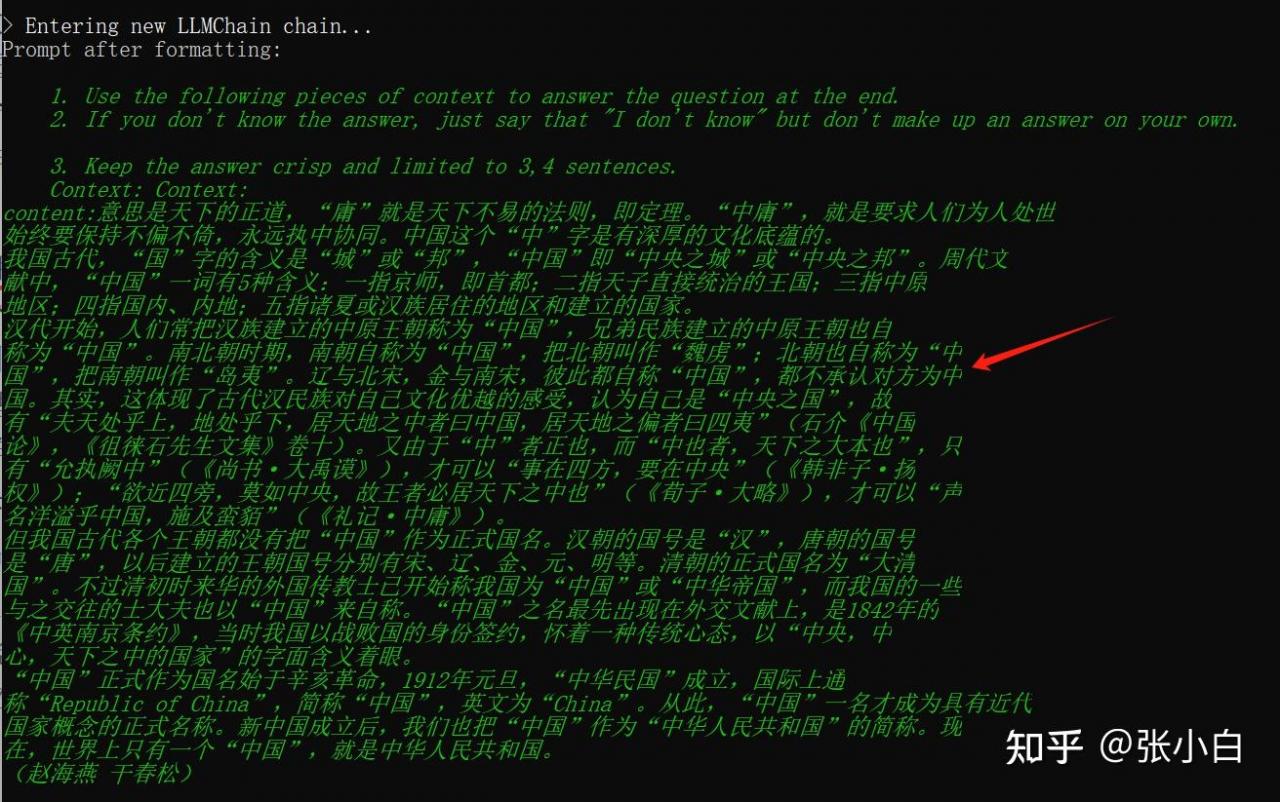

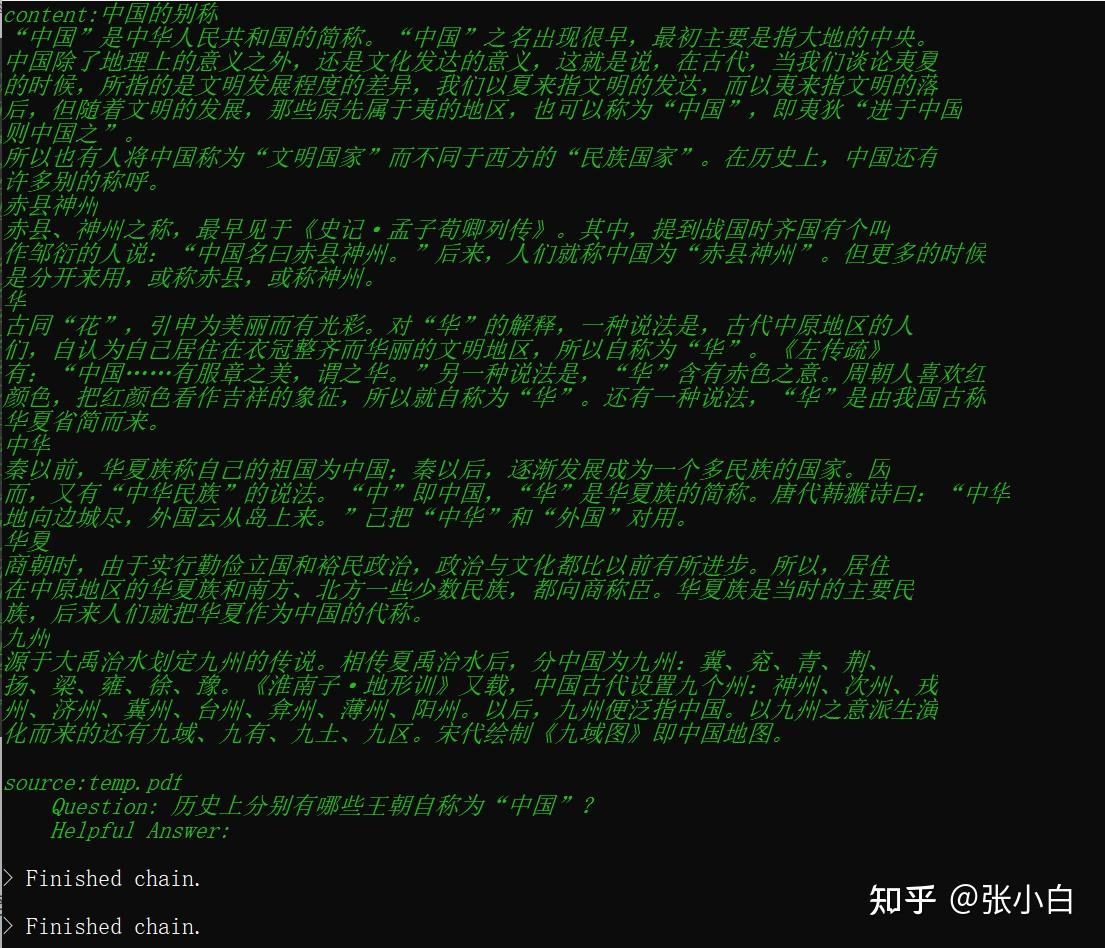
其实汉语挺难的。
虽然答案至少答对了1个,但是这代码跑得贼慢,6M的pdf文件能解析好半天,100多M的pdf文件解析就不知道等多久了。所以现在只是证明了这串代码可以跑通,但是基本上不具备使用价值。
以后可以从几个方面对其进行优化:
1.将pdf文件解析生成faiss向量库的任务分开,离线处理。一次性处理后,保存起来。不要每次启动都去加载pdf文件。
2.提高RAG检索的匹配准确度。
3.优化prompt。