Deepseek本地化部署及训练
一、本地化部署 DeepSeek(Ollama)
Ollama 提供了便捷的 LLM 本地运行环境,支持 DeepSeek 这样的模型。
1. 安装 Ollama
如果还未安装 Ollama,可以用以下命令安装:

然后验证是否安装成功:

2. 拉取 DeepSeek 模型
目前 Ollama 可能还未正式支持 DeepSeek,你可以手动拉取:

或者自定义 Modelfile:

然后运行:

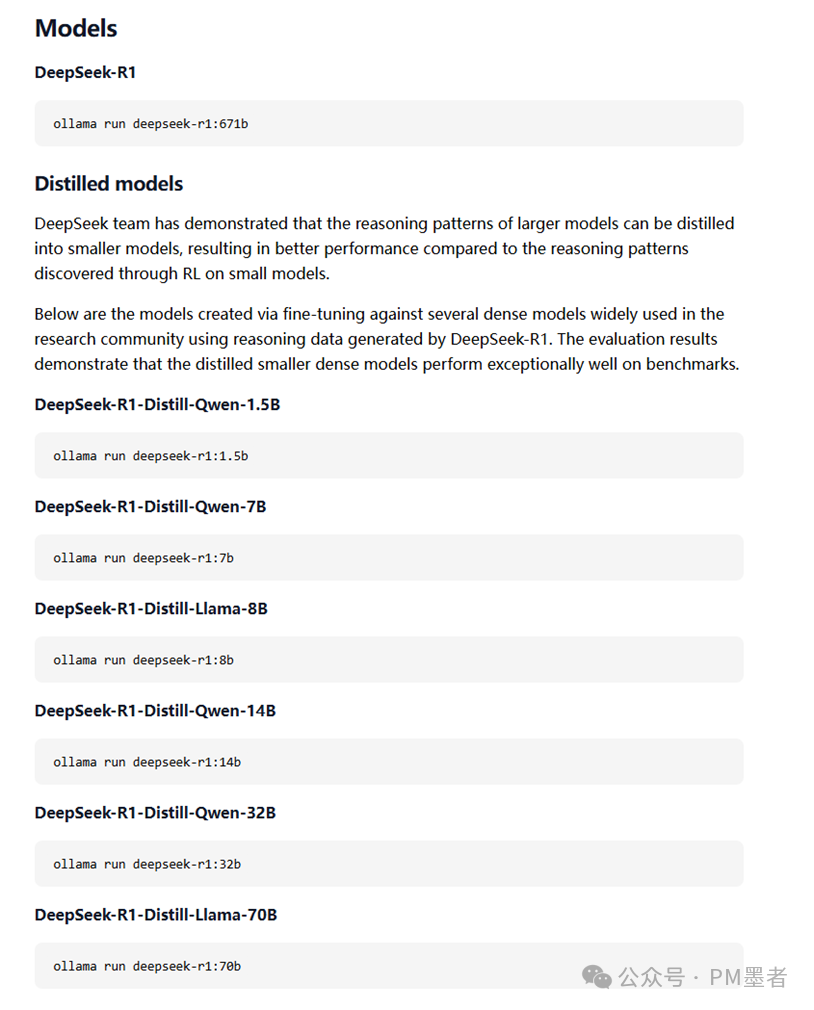
如已经支持则直接运行相应的模型:
二、定制化训练(Fine-tuning)
由于 Ollama 目前不支持直接在 Ollama 内训练模型,你需要使用 LoRA/QLoRA 或 全量微调,然后再将训练后的模型打包进 Ollama。
1. 训练方式
Ollama 主要支持的是 基于 Hugging Face Transformers 训练后,再打包到 Ollama,你可以选择:
✅ LoRA/QLoRA(轻量微调):适用于本地训练,显存占用少。
✅ 全量微调(Full Fine-tuning):适用于大显存 GPU 服务器。
(1)LoRA 训练(推荐)
安装依赖:
pip install peft transformers accelerate bitsandbytes
训练代码:

这样,你的 LoRA 微调模型 就准备好了。
(2)全量微调(Full Fine-tuning)
全量微调会调整 所有模型参数,需要 大量 GPU 计算资源,建议:
✅GPU:A100 (80GB) 或多个 3090 (24GB)
✅CUDA & cuDNN:CUDA 11.8+
✅框架:Hugging Face transformers + DeepSpeed 或 FSDP(分布式训练)
1)安装依赖
先安装必要的 Python 库:

2)下载 DeepSeek 模型
Ollama 目前不支持直接训练,你需要 先用 Hugging Face 下载模型:

或者:

3)准备训练数据
训练数据应采用 指令微调格式(如 Alpaca):
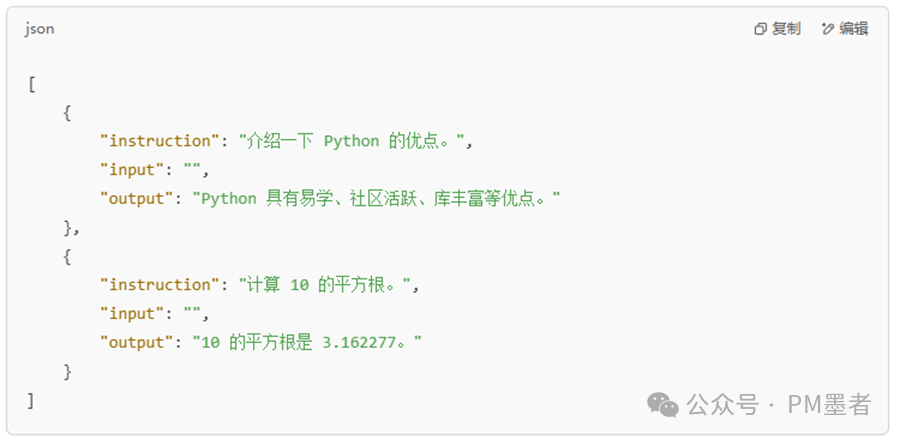
存储为 train.json,然后加载:

4训练配置
创建 train.py:

运行:

三、重新部署到 Ollama
Ollama 支持自定义模型,你可以用 Modelfile 来创建一个新的模型:
1. 创建 Ollama 模型文件
在你的工作目录下创建 Modelfile:
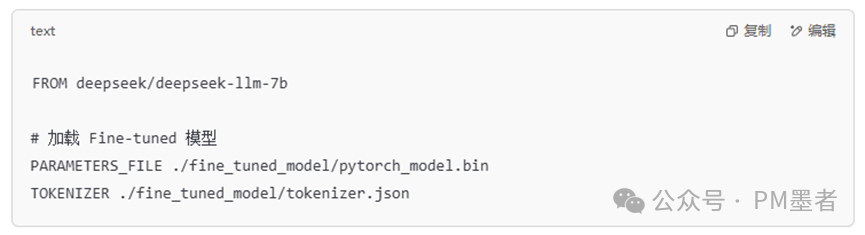
2. 编译并添加到 Ollama
运行:

3. 运行定制模型

总结
1.本地 Ollama 部署 DeepSeek
-
ollama pull deepseek/deepseek-llm-7b
-
或使用 Modelfile 来手动加载 DeepSeek 模型。
2.定制化训练
-
选择 LoRA/QLoRA(推荐)或者 全量微调。
-
使用 transformers + peft 进行训练。
3.重新部署
-
-
训练完成后,把模型打包进 Ollama:
-
-
-
-
创建 Modelfile
-
ollama create deepseek-custom -f Modelfile
-
运行 ollama run deepseek-custom
-
-
这样,你就可以在 Ollama 里运行自己的 Fine-tuned DeepSeek 了!