个人知识库 — AnythingLLM
写在前面
前面几篇文章,介绍了 Ollama、Chatbox、Continue。

这次介绍个人知识库软件 AnythingLLM。
安装
目前语言大模型越来越融入日常办公生活与学习。阅读是常规学习方式,但有了大模型,我们学习方式可以改为与模型进行交流。比如我们可以与模型就某一本书进行深入交流。
这就是 AnythingLLM 主要的作用。
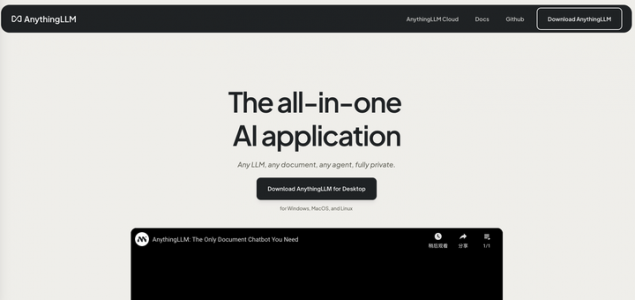
官网下载 AnythingLLM,安装后,界面如下。
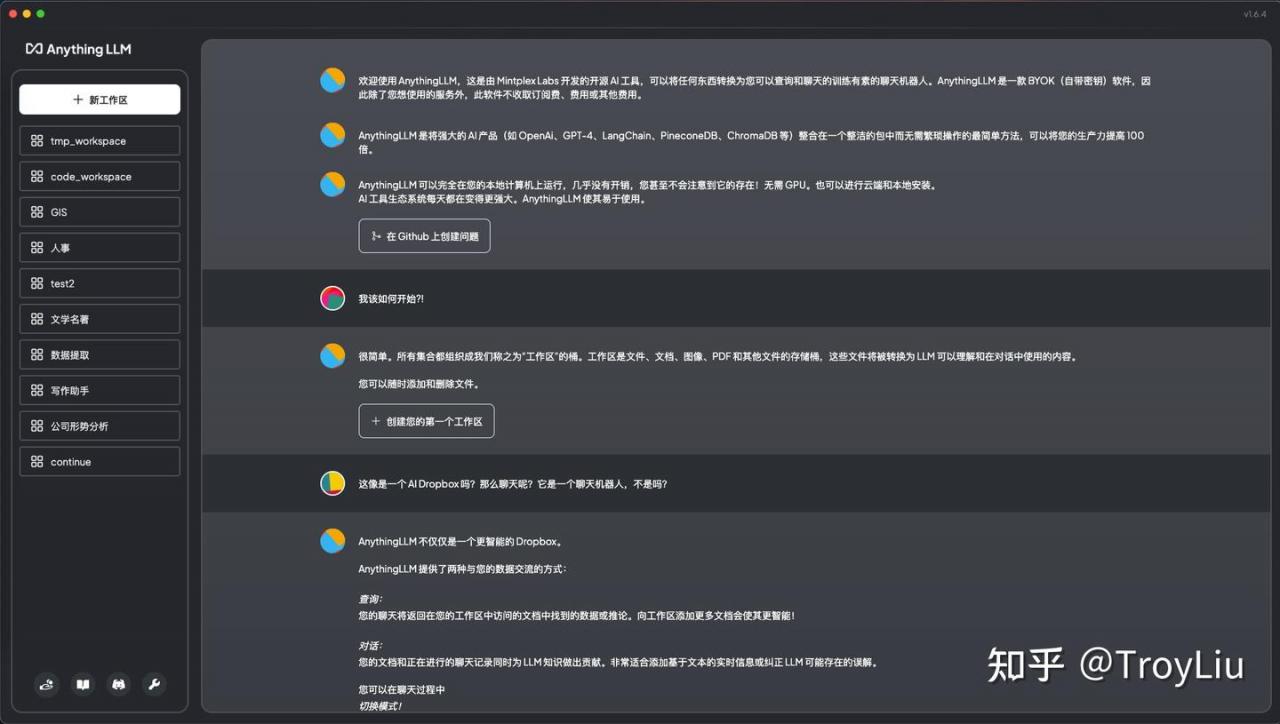
由于本人先前已经安装过,已经创建了很多工作区。
配置
全局设置
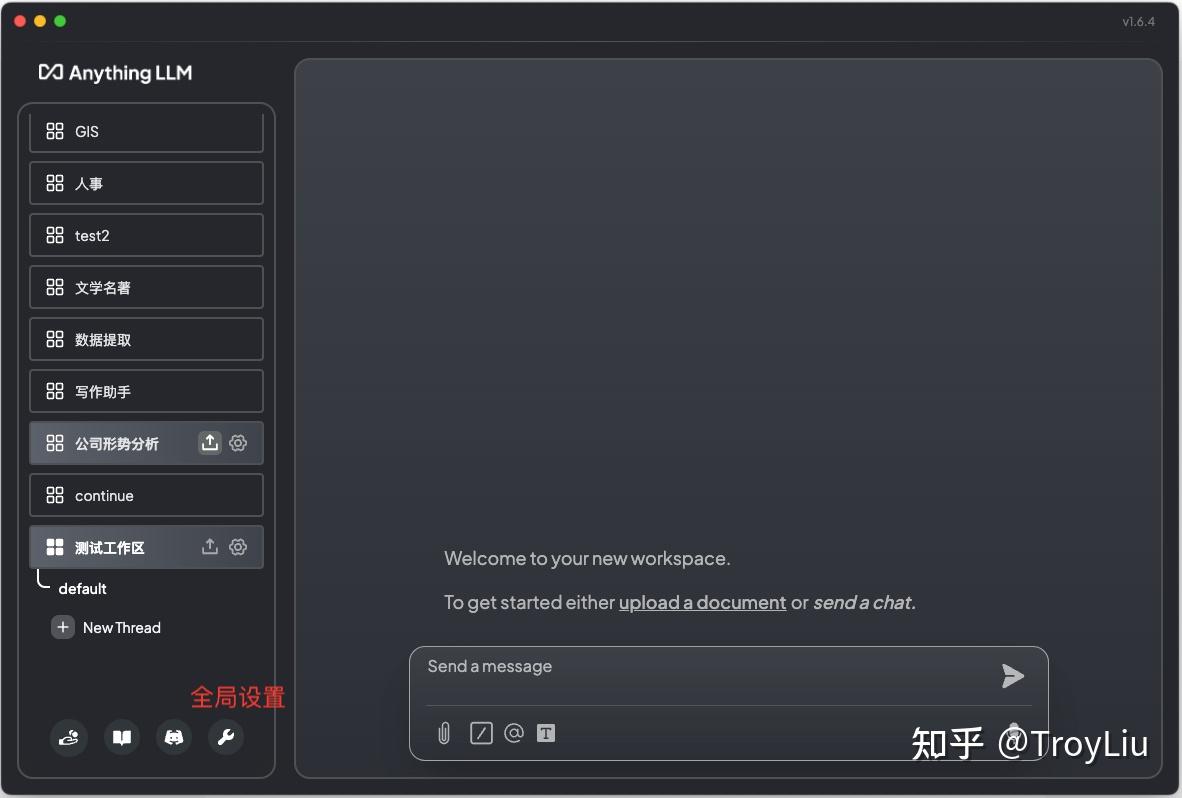
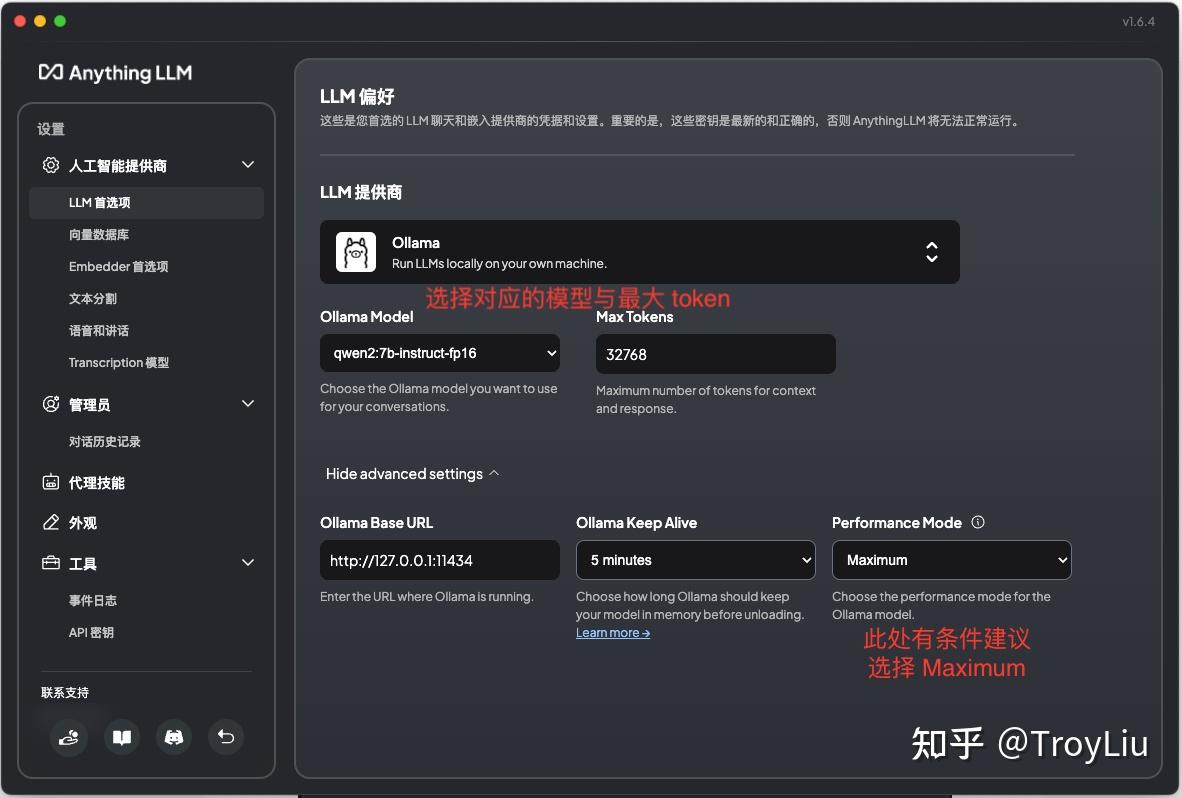
由于本人主要使用本地模型,所以选择 Ollama。如果不清楚如何使用 Ollama,可以参考专栏之前的文章。
模型配置
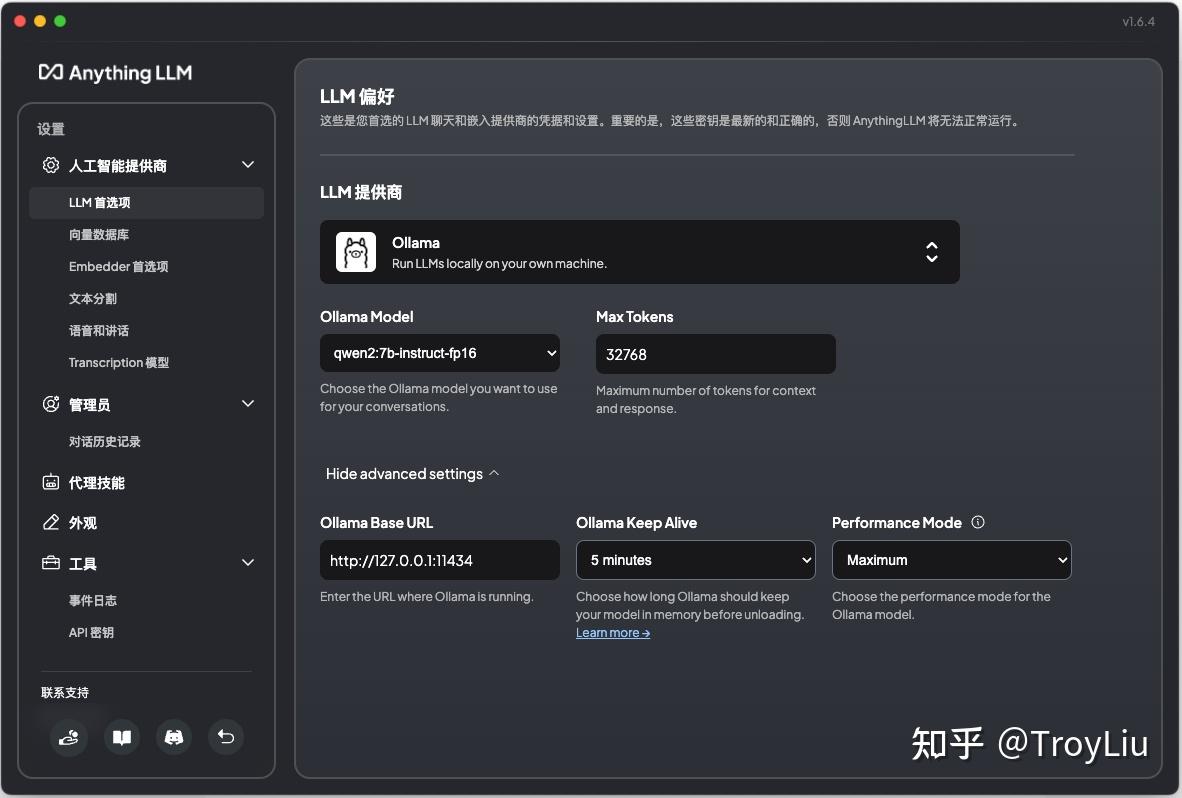
当然,模型大家可以自行选择其他商业模型:
说明:
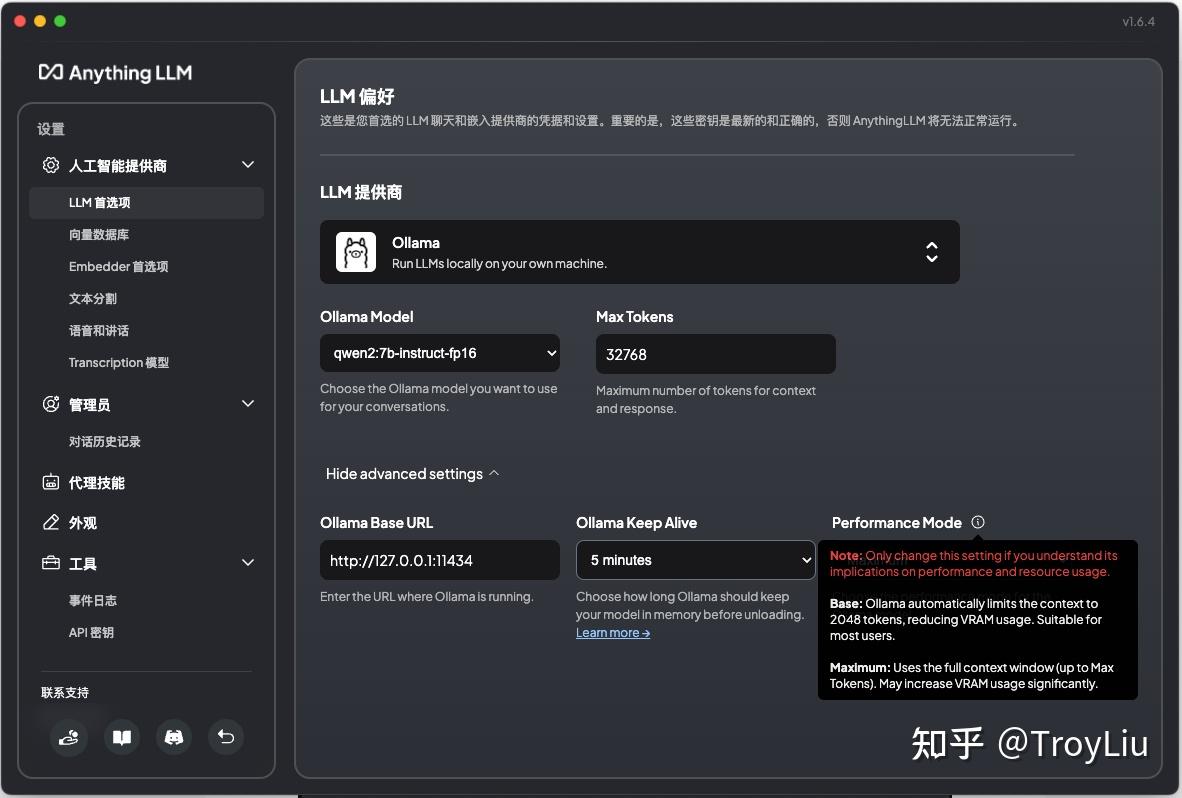
注意:只有理解其对性能和资源使用的影响时才更改此设置。
基本设置:Ollama 自动将上下文限制在 2048 个令牌,减少了 VRAM 的使用。适合大多数用户。
最大值:使用整个上下文窗口(最高 令牌数)。可能会显著增加 VRAM 使用量。
意思是如果配置 Base(Default),会使用 Ollama 默认的 2048 token,主要处于性能考虑。整体效果与 Maximum 对比有差距。 向量数据库配置
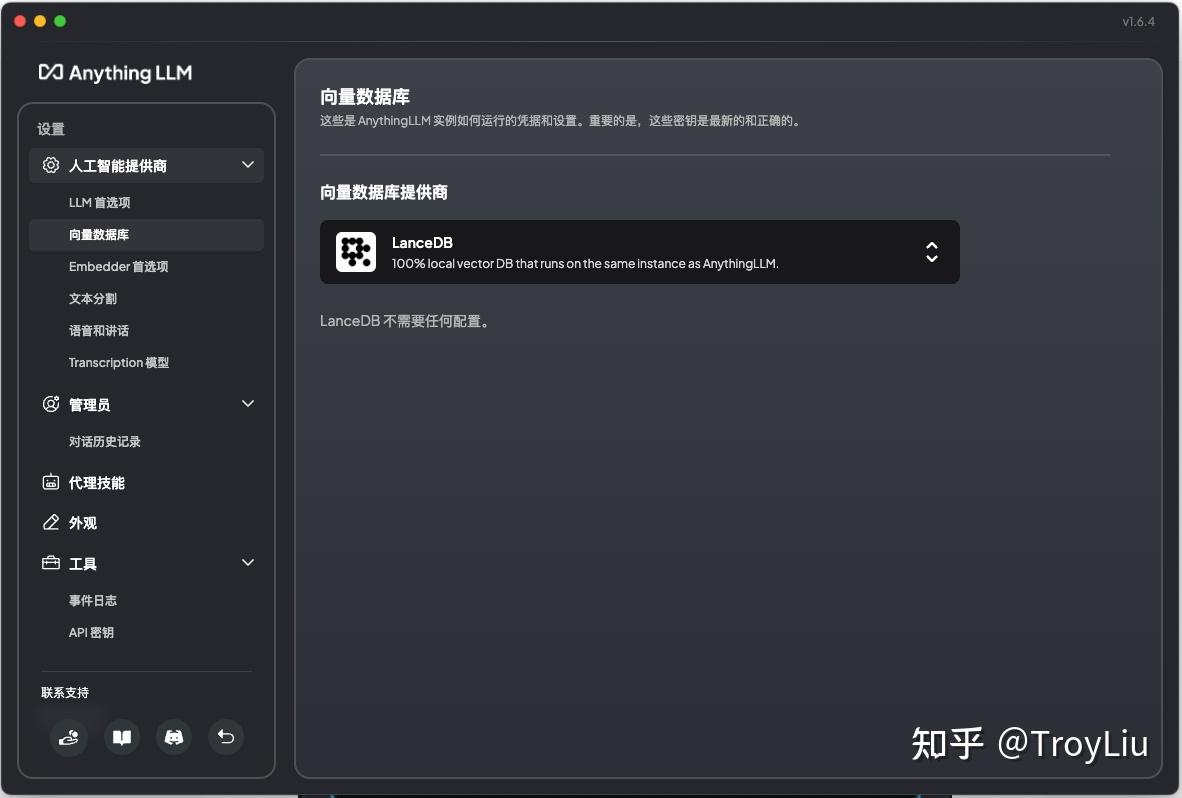
向量数据库选择默认的 LanceDB 即可。
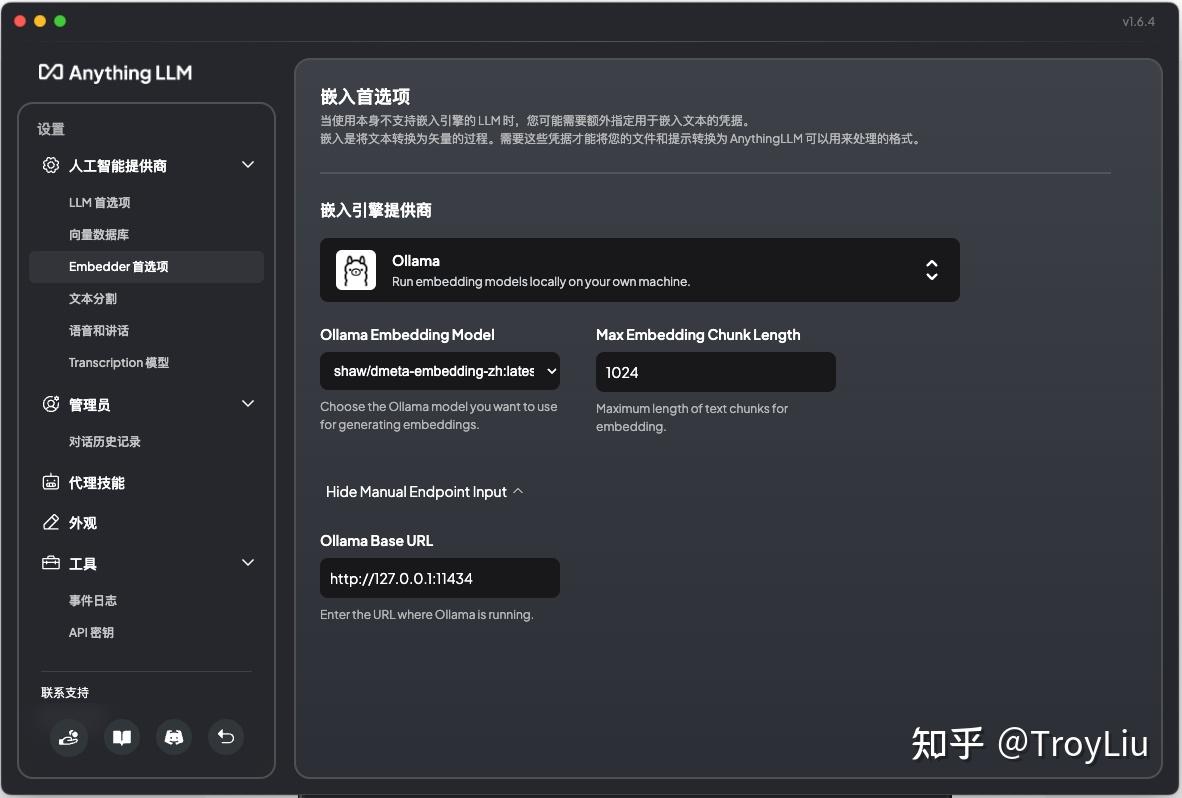
Embedder 模型配置
Embedder 本人选择 Ollama 中的 shaw/dmeta-embedding-zh,选择该模型主要原因是它对于中文支持比较好。如果英文比较好,也可以选择 nomic-embed-text。
其他配置
其他均选择默认配置,无须更改
使用
创建工作区
配置工作区
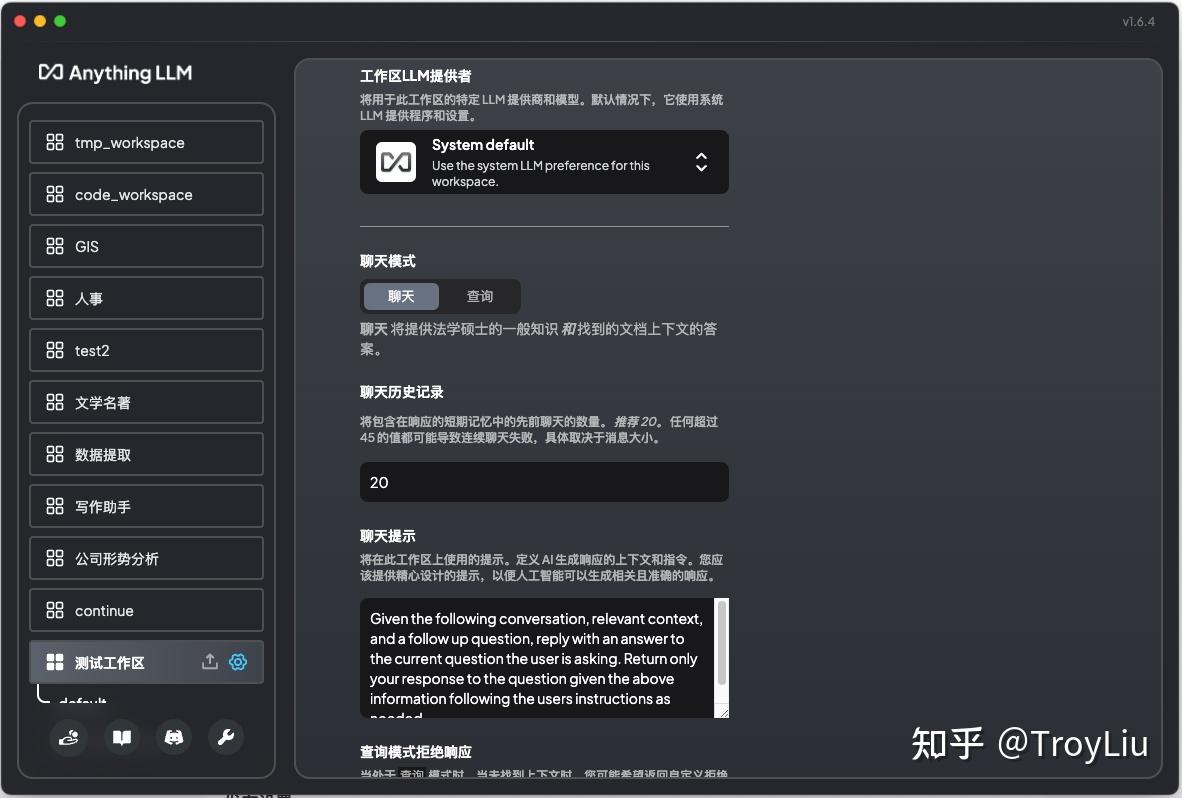
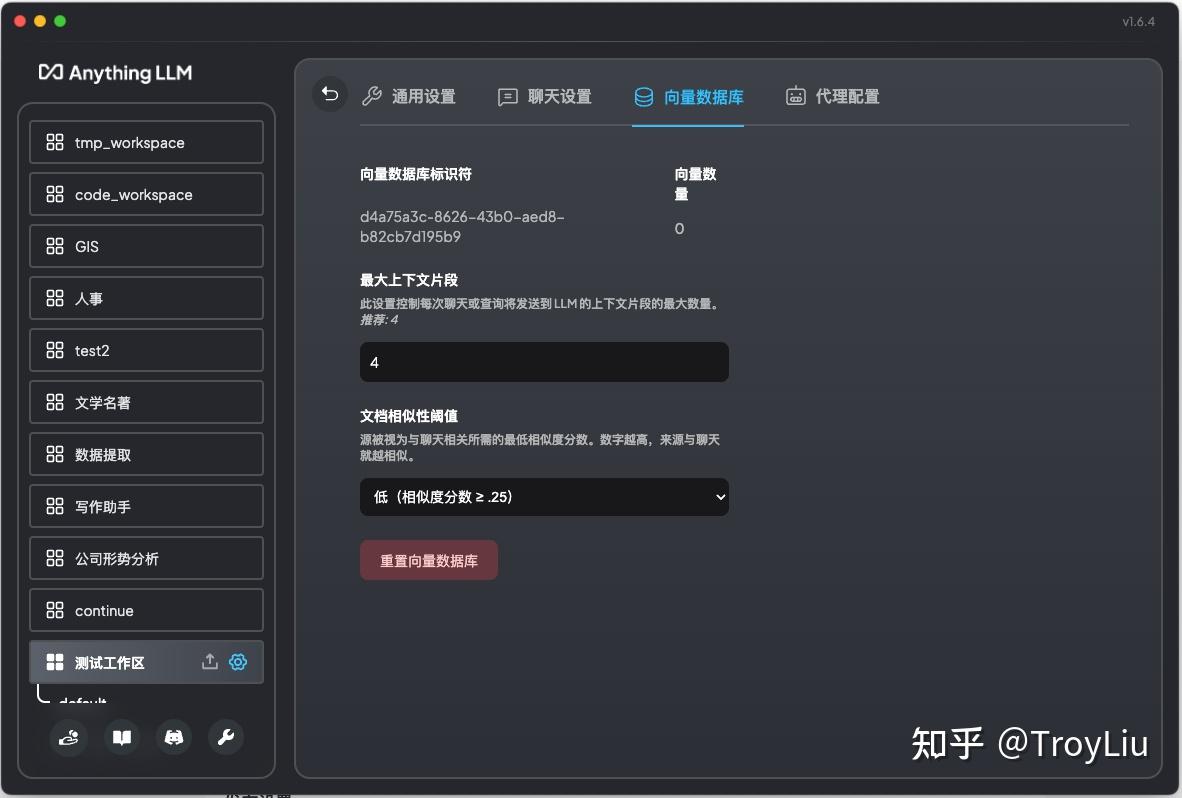
可以针对当前工作区配置 prompt、模型、历史记录条数、最大上下文片段、代理等分别配置:
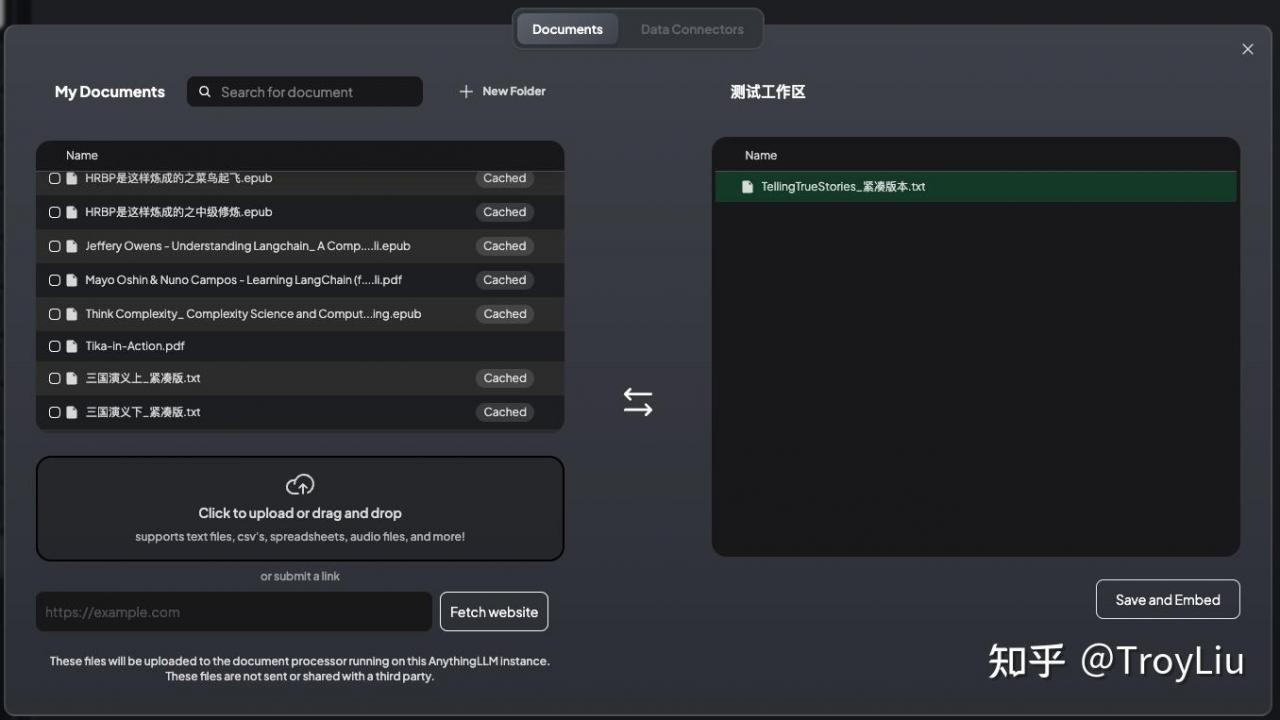
上传文档
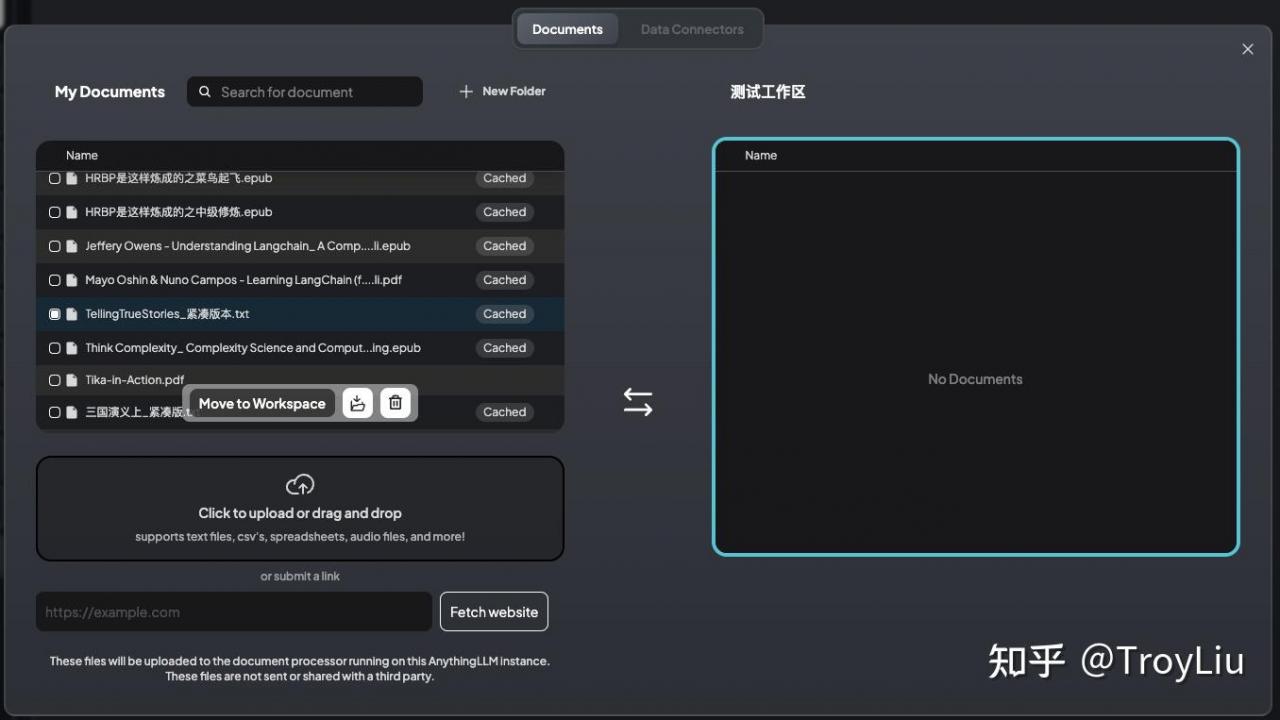
将文件拖动上传,选中上传文件,Move To Workspace,点击 Save and Embed,等待上传完成。
与模型对话
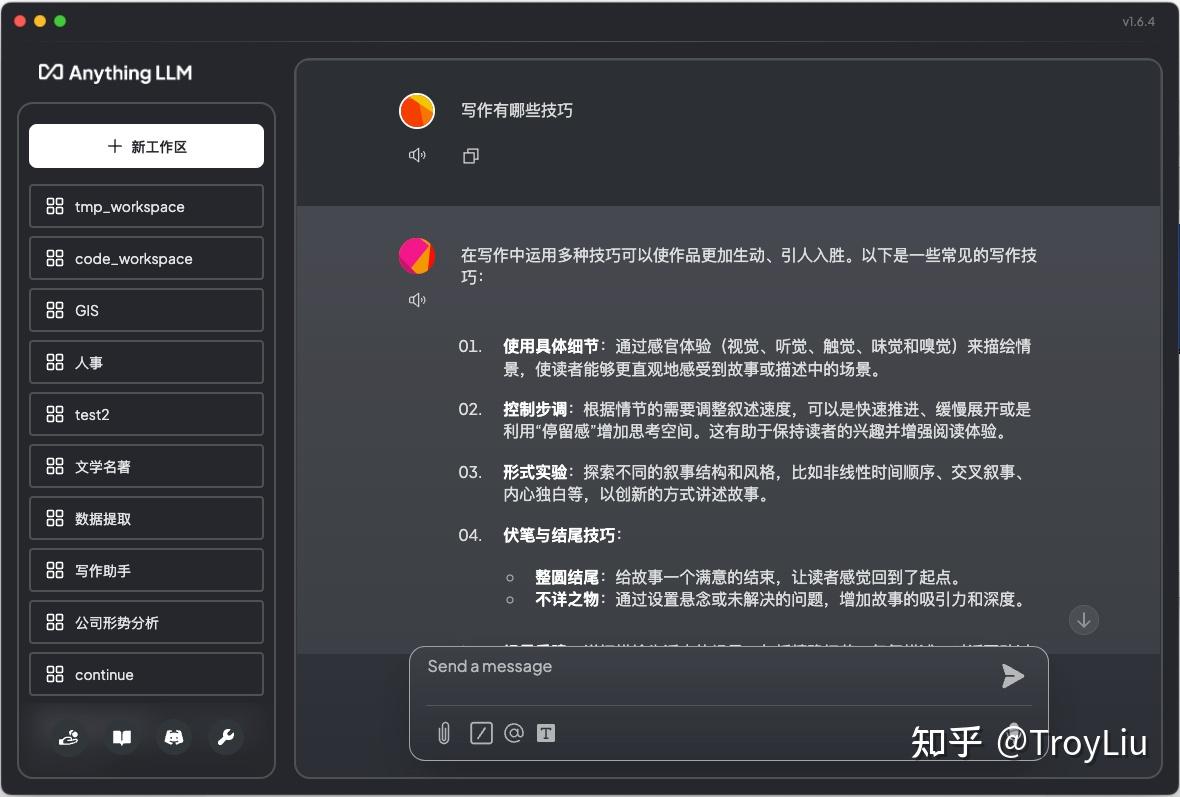
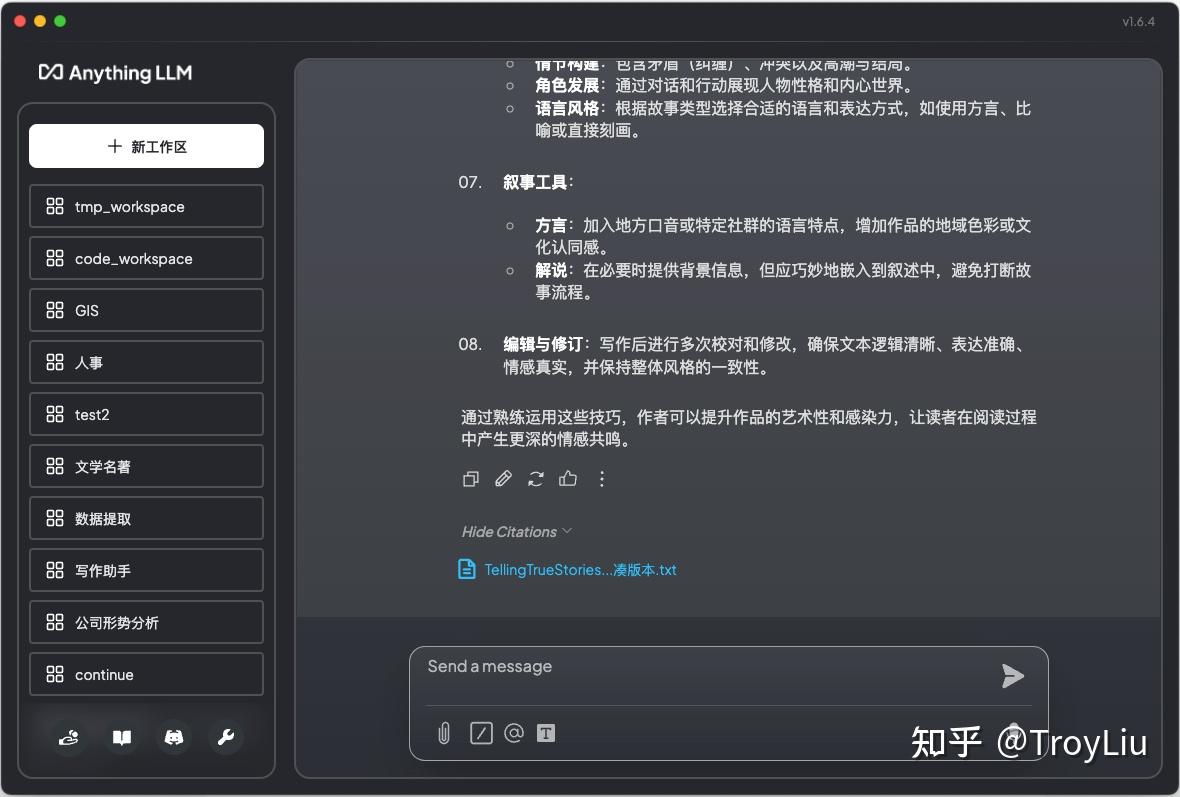
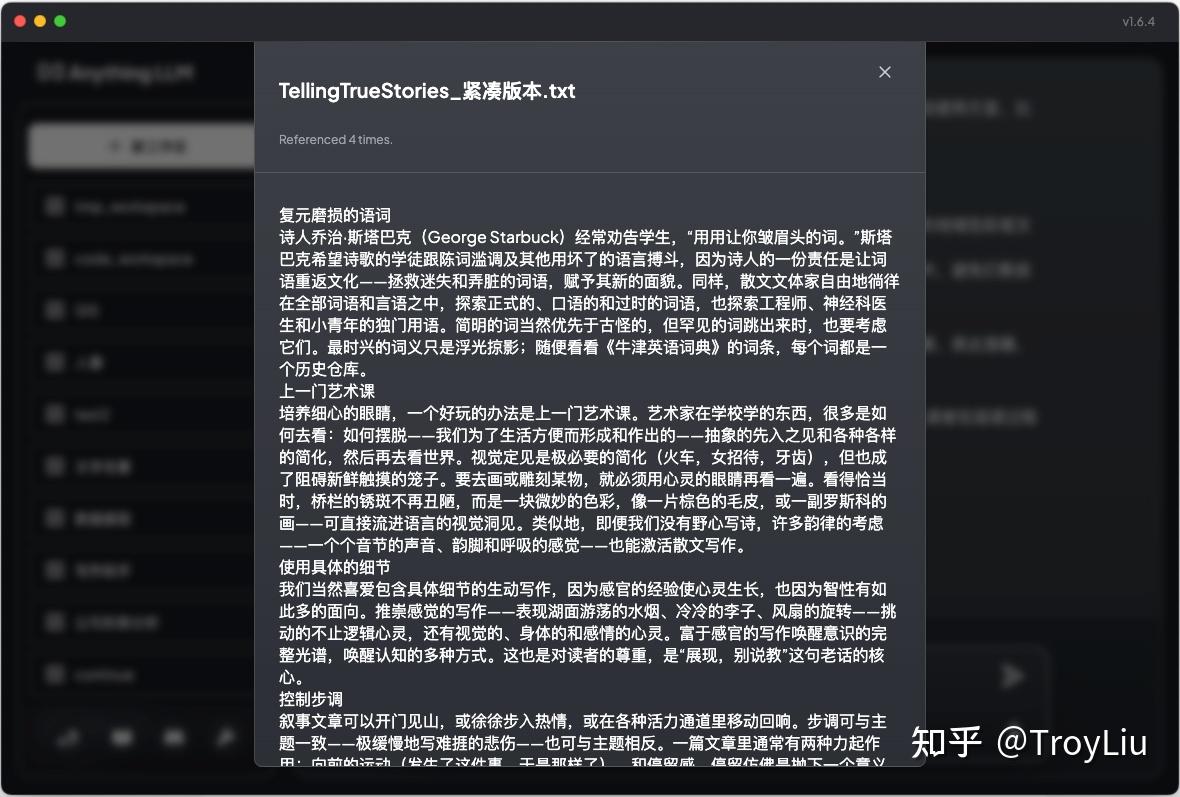
大家可以看到,与模型沟通后,模型会引用当前工作区上传的文档,根据文档内容进行回复。
当然,这也高度依赖模型的质量,如果允许,尽可能选择参数多的模型。
回答质量
结论:只能说进行了参考,硬要说质量,也没有很高。
如果大家尝试使用,会发现模型回答的内容虽然会引用工作区文件,但回答质量的确没有达到可以使用的要求。很多时候你会发现模型根据你的问题在回答,并没有引用工作区文件。
这里官网文档也有相关内容,在这里也贴出,供大家参考。
其中最重要的一点是,参考官方,把文档 Pin to workspace
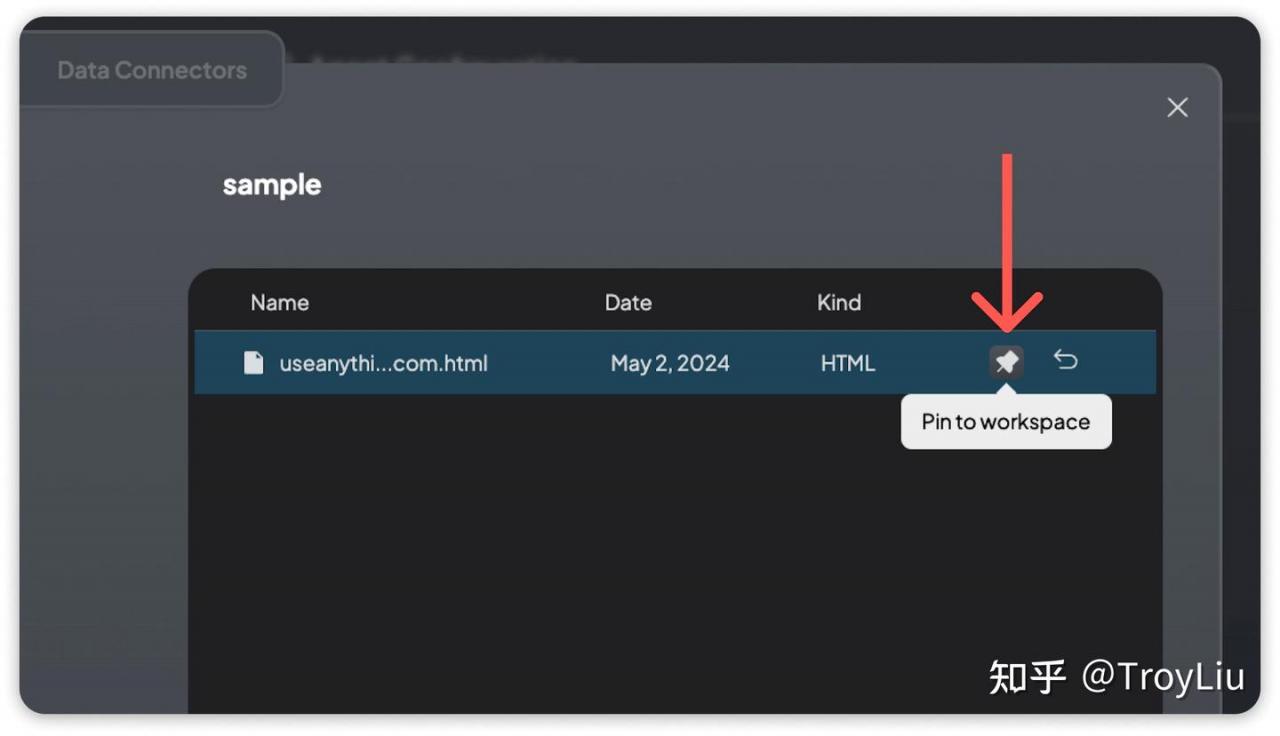
Document Pinning
As a last resort, if the above settings do not seem to change anything for you - then document pinning may be a good solution.
Document Pinning is where we do a full-text insertion of the document into the context window. If the context window permits this volume of text, you will get full-text comprehension and far better answers at the expense of speed and cost.
Document Pinning should be reserved for documents that can either fully fit in the context window or are extremely critical for the use-case of that workspace.
解释:
文档固定是指将文档中的全部文本插入到上下文窗口中。如果上下文窗口允许这种大量的文本插入,你将获得更全面的理解和更好的答案,但是在速度和成本方面会有所牺牲。
文档固定应该只用于那些能够完全在上下文窗口中放置或对于工作区使用案例来说是极其重要的文档。在使用过程中,的确发现很多问题,这些问题都是模型通用问题,想要模型按照我们要求来进行反馈,需要理解内部工作原理。
下一篇文档,将会进一步介绍,如何提到 AnythingLLM 对文档的理解能力。