如何把deepseek-R1微调/蒸馏为某领域的一个专家?
链接:https://www.zhihu.com/question/10555876430/answer/95927198141
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
DeepSeek-R1是一个通过大规模强化学习训练出的强大推理模型,在数学、编程等推理任务上达到了与OpenAI-o1相当的性能水平。本文将基于DeepSeek团队发布的技术报告,详细解析如何通过知识蒸馏技术,将DeepSeek-R1的推理能力高效地迁移到参数量更小的Qwen系列模型中。
1. 什么是知识蒸馏
知识蒸馏是一种机器学习中的模型压缩技术,旨在将复杂的大型模型(称为教师模型,Teacher Model)的知识迁移到较小的模型(称为学生模型,Student Model)。这一方法特别适用于计算资源有限的设备(如手机或嵌入式设备),在显著降低模型规模的同时,尽量保留性能和精度。
核心原理
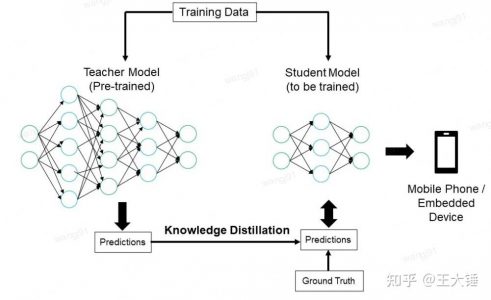
知识蒸馏的核心思想是教师模型通过其预测结果(如概率分布或推理过程)向学生模型传授知识,而学生模型通过学习这些结果逐步提升自己的性能。以下结合流程图具体说明这一过程:
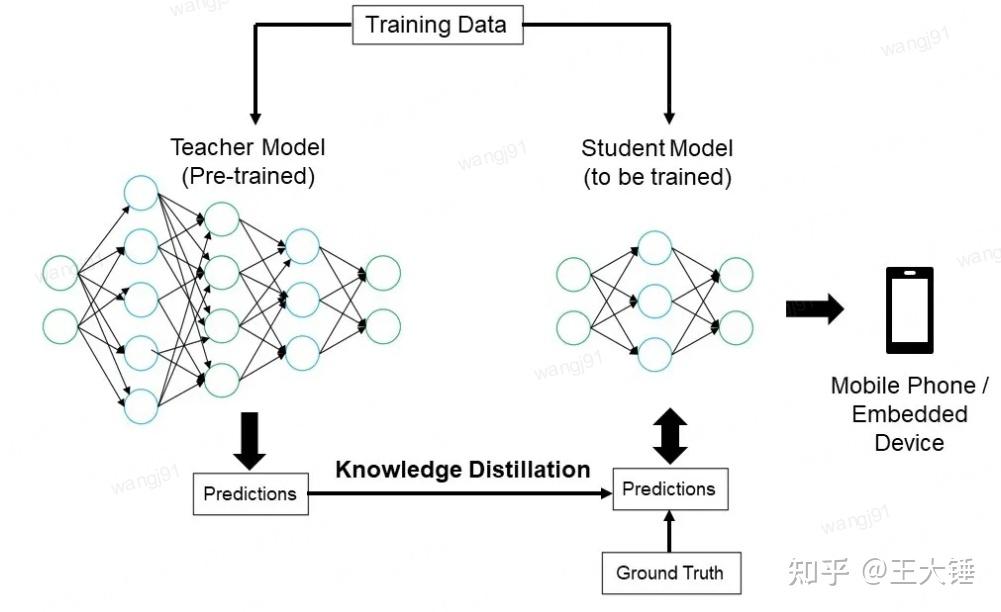
教师模型的作用: 教师模型是一个经过精心设计和充分训练的复杂神经网络,其架构通常包含多个深层结构和复杂的连接方式。这种强大的模型通过处理海量标注数据,能够捕捉到数据中丰富的特征表示和内在规律。与传统的单标签分类不同,教师模型能为每个输入样本生成一个概率分布,即所谓的”软标签”。这种表示方式不仅包含类别信息,还能反映不同类别之间的相似性和潜在关联,为知识蒸馏提供更为丰富的学习信号。
学生模型的训练: 学生模型的设计目标是实现模型压缩与效率提升。其网络架构通常采用更简洁的结构,参数量显著少于教师模型。这种轻量化设计使得学生模型在保持推理能力的同时,具备更低的计算复杂度和更小的存储需求。在训练过程中,学生模型需要同时学习两个目标:一是直接优化与真实标签之间的差异,二是模仿教师模型生成的软标签分布。这种双重学习机制使得学生模型能够捕获教师模型所掌握的领域知识和特征表示能力。此外,还可以通过调整学习率、引入蒸馏温度参数等策略,进一步优化学生模型的学习效果。
知识蒸馏的实现: 知识蒸馏的核心在于将教师模型的知识有效地传递给学生模型。具体实现过程中,教师模型会对每条训练样本生成详细的预测结果,包括各类别的概率分布信息。这些预测结果不仅包含标准的类别标签,还包含了丰富的类别间关系信息。在训练学生模型时,除了使用标准的分类损失函数优化真实标签的预测精度外,还需要引入蒸馏损失,强制学生模型的输出分布与教师模型保持一致。这种多目标优化策略使得学生模型能够在保持高效率的同时,获得接近教师模型的预测能力。此外,还可以通过调整蒸馏温度、引入中间层特征提取等方法,进一步提升知识传递的效果。整个蒸馏过程需要综合考虑模型复杂度、计算效率和学习效果等多个因素,以实现最优的知识迁移。
输出到目标设备:
蒸馏完成后,学生模型被部署到资源受限的设备上,如图中所示的手机或嵌入式设备。
知识蒸馏是一种重要的模型压缩技术,在深度学习领域有着广泛的应用。这项技术的核心思想是通过”以大带小”的方式,将复杂模型的能力迁移到轻量化模型中。下面通过一个典型示例来说明这一过程:
示例场景 我们有一个大型的卷积神经网络(CNN)模型,该模型在猫狗图像识别任务上表现出色。这个高性能模型被称为”教师模型”。为了在移动设备等资源受限的环境中实现高效部署,我们需要创建一个更小、更快的”学生模型”。
知识蒸馏过程
- 教师模型预测:对于一张狗的图片,教师模型生成概率分布输出,例如[0.1, 0.9](表示10%的概率是猫,90%的概率是狗)。
- 学生模型学习:
- 硬标签学习:学习类别标签(如”狗”)
- 软标签学习:学习教师模型的概率分布
- 软标签优势:相比简单的[0,1]硬标签,教师模型的[0.1, 0.9]概率分布提供了更多关于图像特征的细微信息
这项技术的关键优势在于:
- 信息保留:通过软标签保留了教师模型的深层知识
- 模型压缩:显著降低了学生模型的计算复杂度
- 性能提升:学生模型在保持较小体积的同时获得了更好的预测能力
知识蒸馏的应用场景
- 移动端部署:在手机等设备上实现高效推理
- 嵌入式系统:应用于智能家居、自动驾驶等领域
- 边缘计算:在物联网设备中实现本地推理
总结 知识蒸馏提供了一种有效的模型压缩解决方案,使复杂的深度学习模型能够部署到资源受限的环境中。通过让高性能的”教师模型”指导轻量化的”学生模型”,这项技术在保持模型性能的同时显著降低了计算资源需求,为实际应用提供了重要的技术支撑。
2. DeepSeek-R1如何通过知识蒸馏把推理能力迁移到Qwen
接下来我们将基于DeepSeek团队发布的技术报告,详细解析如何通过知识蒸馏技术,将DeepSeek-R1的推理能力高效地迁移到参数量更小的Qwen系列模型中。
2.1 核心概念解析
在深入技术细节前,我们先解释几个关键概念,帮助读者理解蒸馏过程的核心逻辑。
2.1.1 模板:结构化的输出格式
- 定义:模板是预先设计的文本格式,用于规范模型的输出。例如:
<think>:标记推理过程的开始。</think>:标记推理过程的结束。<answer>:标记最终答案的开始。</answer>:标记最终答案的结束。
- 作用:
- 清晰性:像填空题的“提示词”一样,告诉模型“思考过程写在这里,答案写在那里”。
- 一致性:确保所有输出遵循相同结构,便于后续处理和分析。
- 可读性:人类可以轻松区分推理过程和答案,提升用户体验。
2.1.2 推理轨迹:模型解题的“思维链”
- 定义:模型在解决问题时生成的详细步骤也即解决问题时的思考过程,例如:

- 作用:展示模型的逻辑链,使答案生成过程透明化。
2.1.3 拒绝采样:从“试错”中筛选优质数据
- 定义:生成多个候选答案,通过规则筛选保留高质量样本。
- 过程:
- 生成:模型对同一问题输出多个推理轨迹。
- 过滤:通过自动化规则(如答案正确性检查)或人工审核,剔除错误或低质量样本。
- 保留:仅将优质样本加入训练集。
- 类比:类似于考试时先写草稿,最后誊抄正确答案到答题卡。
2.2 蒸馏数据的生成:如何准备“教学材料”
知识蒸馏的第一步是生成高质量的“教学数据”,供小模型学习。
2.2.1 数据来源
- 推理数据(80%):由DeepSeek-R1生成,覆盖数学、编程、逻辑推理等任务。
- 通用数据(20%):来自DeepSeek-V3的通用任务数据(如写作、问答),确保小模型的多任务能力。
2.2.2 数据生成流程
- 模板引导生成:要求DeepSeek-R1按
<think>和<answer>模板输出推理轨迹。 - 拒绝采样筛选:
- 规则过滤:自动检查答案正确性(如数学答案是否符合公式)。
- 可读性检查:剔除语言混合(如中英文混杂)或冗长段落。
- 数据整合:最终形成80万条高质量样本,其中推理数据约60万条,通用数据约20万条。
2.3 蒸馏过程:如何让小模型“学以致用”
2.3.1 教师与学生的角色
- 教师模型:DeepSeek-R1(复杂的大模型,擅长推理)。
- 学生模型:Qwen系列(如Qwen-7B,参数较小,需学习推理能力)。
2.3.2 训练步骤
- 数据输入:将80万样本中的问题部分输入Qwen模型,要求其按模板生成完整的推理轨迹(思考过程 + 答案)。
- 损失计算:对比学生模型生成的完整输出与教师模型(样本)的推理轨迹,通过监督微调(SFT)对齐文本序列。
- 参数更新:通过反向传播优化Qwen模型的参数,使其逼近教师模型的输出。
- 迭代训练:重复多轮训练,确保知识充分迁移。
2.4 实例演示:从方程求解看蒸馏效果
2.4.1 任务示例
- 输入:解方程 (x²-5x+6=0)。
- 教师模型的标准输出:

2.4.2 蒸馏前后对比
- 蒸馏前Qwen-7B输出:

- 问题:缺乏推理过程,答案正确但不可解释。
- 蒸馏后Qwen-7B输出:
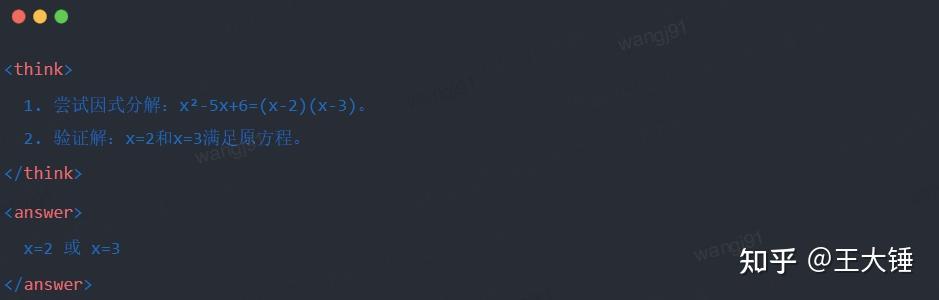
- 改进:生成结构化推理过程,答案与教师模型一致。
总结
通过知识蒸馏,DeepSeek-R1的推理能力被高效迁移至Qwen系列小模型。这一过程以模板化输出和拒绝采样为核心,通过结构化数据生成和精细化训练,使小模型在资源受限的场景中也能实现复杂推理任务。这一技术为AI模型的轻量化部署提供了重要参考。