DeepSeek-R1微调三种方法(DeepSeek-R1-Distill-Qwen-7B)
本文整理了目前博客中常见的几种关于deepSeek-r1蒸馏模型的微调方法,分别是通过Unsloth、openMind和直接使用transformers微调,三种方法大同小异,完整代码和视频教程后续会更新同步,详细微调过程如下:
微调实验设备:ubuntu22.04,RTX4060Ti 16G,python=3.9
1、模型和数据集下载
1.1 模型下载:
huggingface下载(https://huggingface.co)
- 直接haggingface官网页面下载
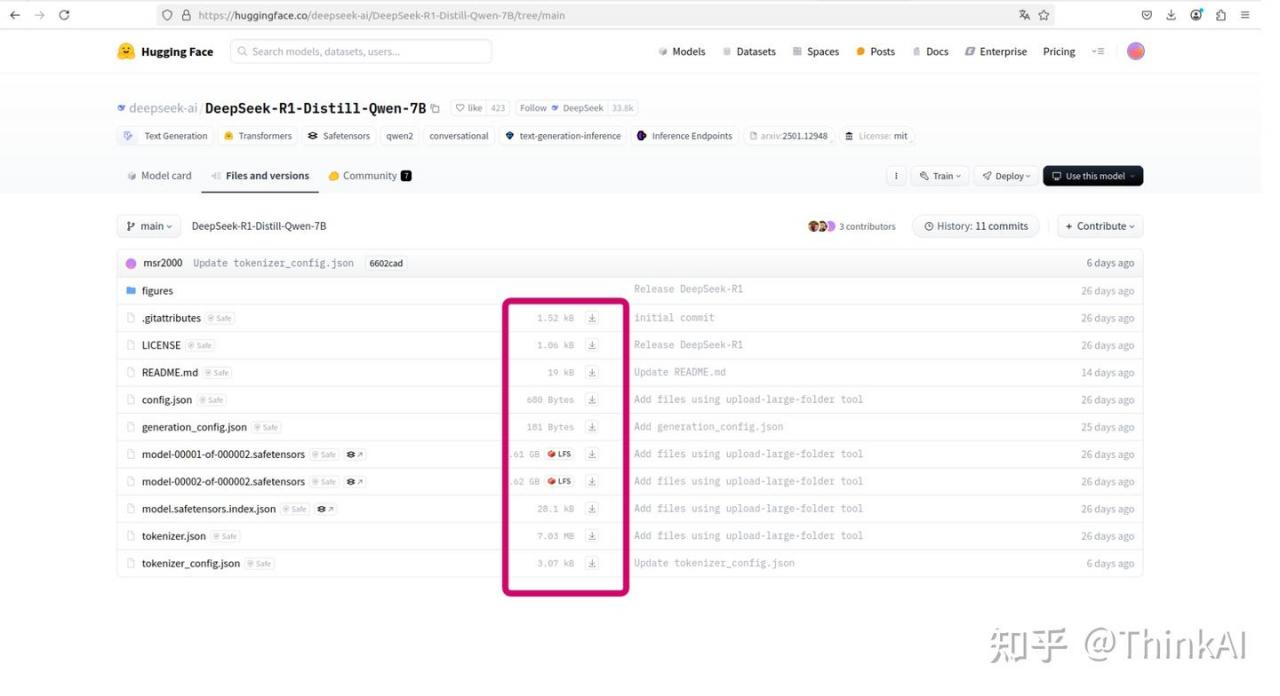
- transformers api下载
from huggingface_hub import snapshot_download
snapshot_download(repo_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B", local_dir="./haggingfaceModels", allow_patterns=["*.json", "*.safetensors"])huggingface官网和transformers api下载都需要科学上网,而且实际测试通过api下载的方式即使开了梯子,下载也不是很稳定,经常出现连接超时或者下载中断的报错,下载速度也不是很快。
- huggingface-cli下载
网上教程推荐用这个https://github.com/LetheSec/HuggingFace-Download-Accelerator.git下载,但查看代码后发现其实就是用的huggingface-cli,测试通过这种方法下载速度确实很快,自测能达到5M/s,而且连接也稳定不少。
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --local-dir ./haggingfaceModels镜像下载(HF-Mirror)
下载方法和使用haggingface类似,可以直接在网页上下载,也可以使用transformers api下载,只需要在导入huggingface_hub修改HF_ENDPOINT变量,通过镜像的方式不需要搭梯子,速度也还可以,但镜像中似乎有些模型没有:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from huggingface_hub import snapshot_download
snapshot_download(repo_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-7B", local_dir="./haggingfaceModels", allow_patterns=["*.json", "*.safetensors"])脚本下载
wget https://hf-mirror.com/hfd/hfd.sh
chmod a+x hfd.sh
# 修改haggingface下载地址为镜像地址
export HF_ENDPOINT=https://hf-mirror.com(或者直接修改hfd.sh中的HF_ENDPOINT=${HF_ENDPOINT:-"https://huggingface.co"})
# -x 是线程数
./hfd.sh 模型名称 --tool aria2c -x 16上面方法具体可以参考GitHub – SevenFo/huggingface-downloader,依赖aria2c,需要sudo apt-get install aria2,这中方法自测也不能直接使用huggingface下载,需要将HF_ENDPOINT换成镜像地址。
国内社区下载
魔搭社区(ModelScope 魔搭社区),可以直接在页面下载也可以通过modelscope api下载,不需要梯子,下载速度和稳定性都不错:
from modelscope import snapshot_download
model_dir = snapshot_download('skyline2006/llama-7b')1.2 数据集下载
实验数据集为medical-o1-reasoning-SFT的medical_o1_sft_Chinese.json文件,下载地址:https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT/tree/main,数据集下载和模型下载方法类似,可以直接在huaggingface网页下载,没有梯子的可以直接在魔搭社区搜索medical-o1-reasoning-SFT下载,也可以通过api和执行网上别人写好的脚本下载,调用transformers_hub或者transformer_cli下载,加上repo_type=”dataset”参数,和模型下载大同小异。
- huggingface_hub下载数据集
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from huggingface_hub import snapshot_download
local_dir = "./haggingfaceDatas"
snapshot_download(repo_id="FreedomIntelligence/medical-o1-reasoning-SFT", repo_type="dataset", local_dir=local_dir, allow_patterns=["*.json"])- huggingface_cli下载数据集
huggingface-cli download --repo-type dataset --resume-download FreedomIntelligence/medical-o1-reasoning-SFT --local-dir ./haggingfaceDatas博主自测huggingface-cli和国内社区下载速度和稳定性都不错,有梯子也可以尝试去haggingface官网网页下载,速度也还可以。
2、加载模型并推理验证
2.1 transformers api
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, GenerationConfig, DataCollatorForSeq2Seq
import torch
import pandas as pd
from datasets import Dataset
model_path = "/home/serein/PycharmProjects/llm/models"
tokenizer = AutoTokenizer.from_pretrained(model_path)
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForCausalLM.from_pretrained(model_path, quantization_config=quantization_config)
# 推理测试
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
question = "一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?"
model.generation_config = GenerationConfig.from_pretrained(model_path)
messages = prompt_style.format(question, "")
model_inputs = tokenizer([messages], return_tensors="pt").to("cuda")
attention_mask = model_inputs.input_ids.ne(tokenizer.pad_token_id).long().to("cuda")
generated_ids = model.generate(
model_inputs.input_ids,
attention_mask=attention_mask,
max_new_tokens=2048,
pad_token_id=tokenizer.eos_token_id,
use_cache=True
)
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(response[0].split("### Response:")[1])使用transformers推理时,遇到一个warning:The attention mask is not set and cannot be inferred from input because pad token is same as eos token. As a consequence, you may observe unexpected behavior. Please pass your input’s `attention_mask` to obtain reliable results.
字面意思理解好像是没有设置attention_mask,设置好attention_mask = model_inputs.input_ids.ne(tokenizer.pad_token_id).long().to(“cuda”),并在model.generate函数中配置好attention_mask=attention_mask。
2.2 unsloth api
from unsloth import FastLanguageModel
MAX_SEQ_LENGTH = 2048
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/home/serein/PycharmProjects/llm/models",
max_seq_length = MAX_SEQ_LENGTH,
dtype = None,
load_in_4bit = True
)
## 推理测试
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
question = "一个患有急性阑尾炎的病人已经发病5天,腹痛稍有减轻但仍然发热,在体检时发现右下腹有压痛的包块,此时应如何处理?"
FastLanguageModel.for_inference(model)
model_inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
attention_mask = model_inputs.input_ids.ne(tokenizer.pad_token_id).long().to("cuda")
outputs = model.generate(
input_ids=model_inputs.input_ids,
attention_mask=attention_mask,
max_new_tokens=2048,
pad_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])使用unsloth加载模型可能遇到的问题:ImportError: cannot import name ‘patch_compiled_autograd’ from ‘unsloth_zoo.patching_utils’,原因是unsloth没有使用最新的版本,直接pip uninstall unsloth -y && pip install –upgrade –no-cache-dir –no-deps git+https://github.com/unslothai/unsloth.git。
3、制作微调数据集
3.1 transformers和unsloth微调方式数据集制作
## 数据集制作
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
# 迭代训练集数据,处理prompt
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
from datasets import load_dataset
dataset = load_dataset('json', data_files='/home/serein/PycharmProjects/llm/datas/medical_o1_sft_Chinese.json', split = "train")
dataset = dataset.map(formatting_prompts_func, batched = True,)3.1 openMind微调方式数据集制作
使用openMind微调制作数据会有些不同,openMind缺少数据封装的函数,需要调用transformers手动创建一个数据封装函数,debug进transformers的DataCollatorForLanguageModeling类中,按照torch_call函数中相同的方式构建数据封装函数,deepSeek-r1是自回归模型,构建输入input_text为train_prompt_style格式,labels和inputs_ids相同,构建batch时,按batch内长度最长的inputs_ids将其它inputs_ids填充到该长度,用0补充:
def process_data(data, tokenizer, max_seq_length):
input_ids, attention_mask, labels = [], [], []
inputs = data["Question"]
cots = data["Complex_CoT"]
outputs = data["Response"]
input_text =tokenizer.bos_token + train_prompt_style.format(inputs, cots, outputs) + tokenizer.eos_token
input_tokenizer = tokenizer(
input_text,
add_special_tokens=False,
truncation=True,
padding=False,
return_tensors=None,
)
input_ids += input_tokenizer['input_ids']
attention_mask += input_tokenizer['attention_mask']
if len(input_ids) > max_seq_length: # 做一个截断
input_ids = input_ids[:max_seq_length]
attention_mask = attention_mask[:max_seq_length]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": input_ids
}
data = pd.read_json(data_path)
train_ds = Dataset.from_pandas(data)
train_dataset = train_ds.map(process_data,
fn_kwargs={"tokenizer": tokenizer, "max_seq_length": tokenizer.model_max_length},
remove_columns=train_ds.column_names)
class DataCollatorForSeq2SeqCustom:
def __init__(self, tokenizer, padding=True, return_tensors="pt"):
self.tokenizer = tokenizer
self.padding = padding # 是否填充到最大长度
self.return_tensors = return_tensors # 返回格式,默认为 pytorch tensor
def __call__(self, batch):
# 从 batch 中提取 input_ids, attention_mask, 和 labels
input_ids = [example['input_ids'] for example in batch]
attention_mask = [example['attention_mask'] for example in batch]
labels = [example['labels'] for example in batch]
# 填充所有 sequences 到最大长度
input_ids = self.pad_sequence(input_ids)
attention_mask = self.pad_sequence(attention_mask)
labels = self.pad_sequence(labels)
# 将数据转换为 tensor 格式
if self.return_tensors == "pt":
input_ids = torch.tensor(input_ids)
attention_mask = torch.tensor(attention_mask)
labels = torch.tensor(labels)
return {"input_ids": input_ids, "attention_mask": attention_mask, "labels": labels}
def pad_sequence(self, sequences):
# 填充序列到最大长度
max_length = max(len(seq) for seq in sequences)
padded_sequences = [
seq + [self.tokenizer.pad_token_id] * (max_length - len(seq)) for seq in sequences
]
return padded_sequences
# 创建数据封装器
data_collator = DataCollatorForSeq2SeqCustom(tokenizer=tokenizer, padding=False, return_tensors="pt")4、模型微调和可视化
使用openMind微调需要注意第三方库版本,用最新的transformers版本,一直报错,测试了很多版本确定下面版本能微调起来:
transformers == 4.39.1
bitsandbytes==0.37.2
accelerate==0.28.0
peft==0.10.0
openmind==1.0.0三种微调方式大同小异,实际测试unsloth微调显存占用最小,其它两种方法显存占用接近,显存不够的话,可以尝试减少per_device_train_batch_size,或者减小qlora微调的r、lora_alpha参数,测试使用的4060Ti-16G只能使用unsloth微调,使用openMind和transformers api只用一个batch显存还是不够,下面代码实际测试显存占用:
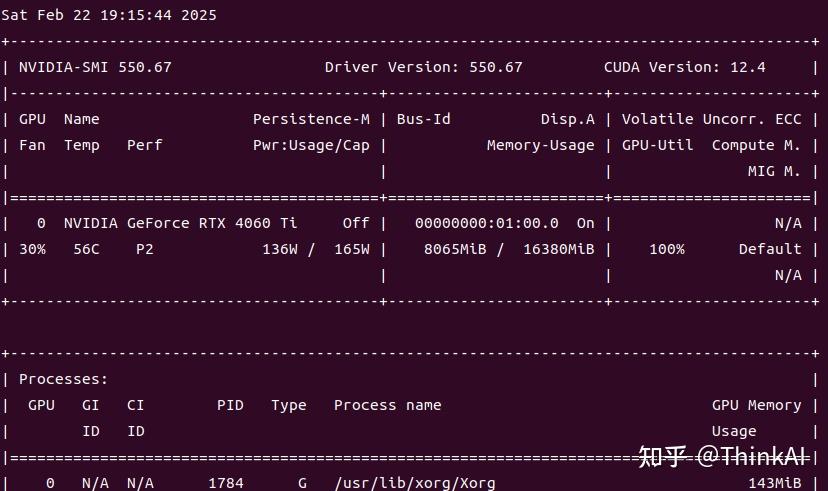
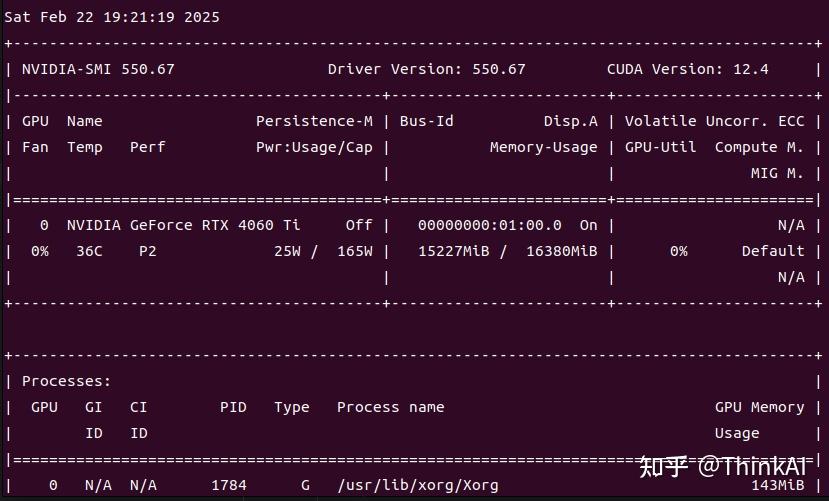
4.1 unsloth微调
model = FastLanguageModel.get_peft_model(
model,
r = 8, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = MAX_SEQ_LENGTH,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
# num_train_epochs = 1, # For longer training runs!
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none", # Use this for WandB etc
),
)
# 训练
trainer_stats = trainer.train()4.2 openMind或transformers微调
lora_config = LoraConfig(
r=8,
lora_alpha=16,
lora_dropout=0.01,
bias="none",
target_modules=["q_proj", "v_proj"],
task_type=TaskType.CAUSAL_LM,
inference_mode=False # 训练模式
)
try:
from openmind import TrainingArguments
except:
from transformers import TrainingArguments
# 输出地址
output_dir="/root/autodl-tmp/models/loraFile/outPut"
# 配置训练参数
train_args = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=1,
gradient_accumulation_steps=8,
logging_steps=50,
num_train_epochs=2,
save_steps=500,
learning_rate=2e-4,
save_on_each_node=True,
gradient_checkpointing=True,
report_to=None,
seed=42,
optim="adamw_8bit",
fp16=True,
bf16=False,
remove_unused_columns=False,
)
from swanlab.integration.transformers import SwanLabCallback
swanlab_config = {
"dataset": data_path,
"peft":"lora"
}
swanlab_callback = SwanLabCallback(
project="deepseek-finetune-test",
experiment_name="first-test",
description="微调多轮对话",
workspace=None,
config=swanlab_config,
)
from peft import get_peft_model
try:
from openmind import Trainer
except:
from transformers import Trainer
# 用于确保模型的词嵌入层参与训练
model.enable_input_require_grads()
# 应用 PEFT 配置到模型
model = get_peft_model(model,lora_config)
model.print_trainable_parameters()
# 配置训练器
trainer = Trainer(
model=model,
args=train_args,
train_dataset=train_dataset,
data_collator=data_collator,
callbacks=[swanlab_callback],
)
# 启动训练
trainer.train()可视化使用的是swanlab(https://swanlab.cn)工具,需要先去官网注册登录后,获取API Key,pip install swanlab,安装完成后执行swanlab login,将API Key输入即可。

微调结果可视化
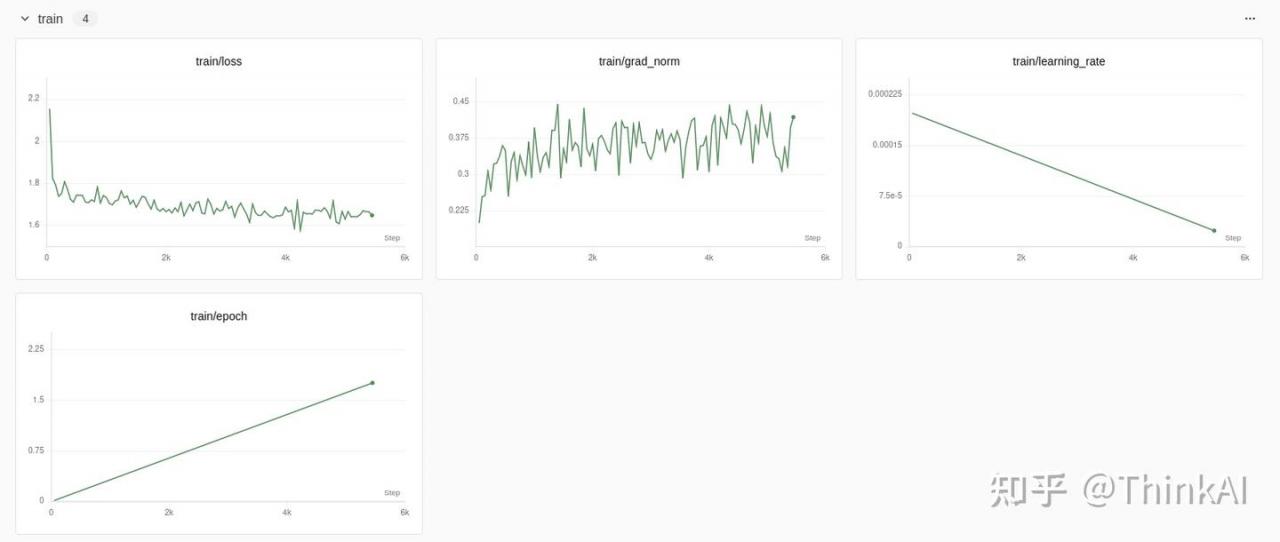
5、微调模型保存
from os.path import join
final_save_path = join(output_dir)
trainer.save_model(final_save_path)6、微调后模型验证
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, GenerationConfig, DataCollatorForSeq2Seq
from peft import PeftModel
base_model_path = "./DeepSeek-R1-Distill-Qwen-7B"
lora_model_path = "./LoraOutModels/checkpoint-5000"
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
base_model = AutoModelForCausalLM.from_pretrained(base_model_path, quantization_config=quantization_config)
lora_model = PeftModel.from_pretrained(base_model, lora_model_path)
merged_model = lora_model.merge_and_unload()
## 推理测试
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
question = "患者表现为干咳,或咯少量粘痰,有时痰中带血,胸部隐痛,午后手足心热,皮肤干灼,或有盗汗,舌质红苔薄,脉细数。请问该患者的中医辨证是什么?"
model_inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
# attention_mask = model_inputs.input_ids.ne(tokenizer.pad_token_id).long().to("cuda")
outputs = merged_model.generate(
input_ids=model_inputs.input_ids,
attention_mask=model_inputs.attention_mask,
max_new_tokens=2048,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])测试问题:
Question "患者表现为干咳,或咯少量粘痰,有时痰中带血,胸部…质红苔薄,脉细数。请问该患者的中医辨证是什么?"
Complex_CoT "干咳,还有少量粘痰,有时痰中带血,这些症状听起来像是和肺部有关,可能有什么炎症或者热在作怪。我记得这种情况下有时候是因为肺里的津液不足。 \n\n \n\n接着,有午后手足心热这些表现,而且舌红,脉细数,感觉挺像是阴虚内热。如果是阴虚,体内的阴液不够,就容易这种内热的感觉。\n\n \n\n此外,患者居然还有皮肤干灼,有时出汗的症状!这些是典型的阴虚表现,尤其是肺阴虚的典型症状。看得出,是体内津液无法滋润皮肤导致的。\n\n \n\n所以综合起来,干咳、少痰、咳血,这说明肺阴虚外加点内热。这可能是因为阴虚,体内没有足够的津液滋润。\n\n \n\n嗯,细想一下,咳血还有可能是因为肺中有热,把血络给伤到了,更加说明内有热的感觉。这种情况应该就是阴虚然后内热引起的。 \n\n \n\n再有,患者说有胸部隐痛,这可能是气血不畅,还真挺符合阴虚导致的状况。这个痛说明虚火在身体里面扰动着。\n\n \n\n还有舌红苔薄,痰少,这些都和阴虚内热是一致的症状。患者阴虚的可能性更加大了,而且这和干咳症状很对得上。\n\n \n\n总是觉得症状和肺阴虚夹着内热的结合挺吻合。特别是干咳、皮肤干燥这些症状都在一个方向。\n\n \n\n再进一步想,肺阴亏虚是怎么样的呢?主要是津液不足导致外部的表现,因此有干咳、少痰还有皮肤干这些情况。哦,这和患者的症状基本完全吻合。\n\n \n\n所以,要是症状都是这种方向的话,归为肺阴亏虚应该是对的,也能解释所有的症状组合。影响了皮肤、呼吸等等,看来这个方向不容小视。\n\n \n\n这样子回头看看,所有症状的点线都很一致,确实是肺阴亏虚。这也符合大部分分析和患者症状的实际表现。"
Response "根据患者所表现的症状,干咳、少量粘痰、痰中带血、胸部隐痛、午后手足心热、皮肤干灼、盗汗、舌质红苔薄、脉细数,这些症状综合起来符合中医中的“肺阴虚”夹“内热”的表现。肺阴虚是指肺的阴液不足,无法滋润肺脏和其他相关系统,导致干咳、皮肤干燥等症状,而内热则会导致痰中带血、手足心热等表现。因此,该患者的中医辨证为“肺阴虚夹内热”。"微调前基础模型推理结果:
<think>
患者表现出干咳,有时会有少量粘痰,甚至痰中带血。这些症状让我想到肺火的问题,因为肺火旺盛常常会引起这样的症状。再看下,患者还提到胸部隐痛,午后手足心热,皮肤干灼,甚至有盗汗。这些症状让我想到肺火上炎,导致身体上火。
哦,舌质红苔薄,脉细数,这似乎也是肺火旺盛的表现。这些表现都是肺火旺盛的典型症状。嗯,看起来患者是肺火旺盛。
不过,仔细想想,痰中带血,这不像是单纯的肺火旺盛。这让我想到是不是有更深层次的湿热呢?湿热和肺火一起作用,会增加痰的黏稠度,甚至出现血丝。
再看,患者皮肤干灼和盗汗,这些症状提示身体内有热邪,可能不仅仅是肺火。湿热可能在皮肤上表现在干灼和盗汗。所以,湿热可能在某种程度上影响了肺火。
哦,等一下,湿热可能和肺火一起作用,导致这些症状。湿热的上行可能让肺火更旺盛,同时又导致了痰湿内盛,甚至血液中的异常。
结合所有这些症状,似乎湿热和肺火一起在发挥作用。湿热可能在肺火的基础上增加了痰湿,而痰湿进一步影响了肺火的上炎。这样看来,湿热与肺火的共同作用是更合理的解释。
这样想来,患者的症状可能更符合湿热和肺火并存的情况。嗯,这个方向看起来更准确,也能解释所有症状。
</think>
根据患者的症状表现,中医辨证为湿热和肺火并存。患者干咳、痰中带血、胸部隐痛、午后手足心热、皮肤干灼、盗汗等,都提示肺火旺盛,但痰中带血和皮肤症状则提示湿热的可能参与。舌质红苔薄,脉细数,进一步支持肺火旺盛。因此,湿热和肺火的共同作用可能是导致这些症状的原因。<|end▁of▁sentence|>微调后模型推理结果:
<think>
患者有干咳,咳出少量粘痰,有时候痰里还带血,这让我想到可能是肺的问题。嗯,肺部有气虚或者有痰阻的情况,可能会导致这些症状。再看看,患者还会有胸部隐痛,这是肺气虚导致的吗?再加上午后手足心热,皮肤干灼,甚至有盗汗,这些都提示身体可能有阴虚内热。舌质红苔薄,脉细数,似乎也支持阴虚内热的诊断。
哦,我得再想想,痰里有血,这说明肺气不畅,可能有痰瘀结。再加上胸胁隐痛,这种情况下,气虚和痰瘀可能同时存在。还有,手足心热和盗汗,这更加强了阴虚的特征。
嗯,结合这些症状,肺气虚和痰瘀结的可能性很大。痰瘀导致了痰中带血,而阴虚内热则解释了午后手足心热,皮肤干灼,还有盗汗。这样一来,患者的症状就都能解释了。
总结一下,患者的中医辨证应该是痰瘀兼阴虚内热。这样看来,这些症状都符合这个诊断,挺有道理的。
</think>
根据患者的症状表现,中医辨证为“痰瘀兼阴虚内热”。患者表现出干咳、咳痰带血、胸部隐痛,以及午后手足心热、皮肤干灼、盗汗等症状,这些都提示肺气虚或痰瘀结的存在。同时,舌质红苔薄、脉细数也支持阴虚内热的诊断。痰瘀导致痰中带血,而阴虚内热则解释了手足心热、皮肤干灼和盗汗。因此,结合这些症状,痰瘀兼阴虚内热的诊断较为符合。<|end▁of▁sentence|>模型融合结果保存:
savePath = "./mergePath"
tokenizer.save_pretrained(savePath)
merged_model.save_pretrained(savePath, safe_serialization=False)7、总结
1:建议新手还是新创建一个conda环境用于大模型微调测试,不然很容易报版本错误信息,python版本最好选用3.9以上版本(unsloth还是openmind需要3.9+版本,具体是哪个忘记了),本人使用的3.9。
2:个人觉得unsloth是这几中微调方式中体验感最好的方式。
3:微调代码大同小异,难点其实在数据处理上,对于不同模型的inputs_ids、attention_mask、labels怎么处理还需要进一步加深理解。