[ComfyUI]阿里重磅开源!视频修复神器DiffuEraser来了,ComfyUI一键擦除穿帮/水印/杂物
![[ComfyUI]阿里重磅开源!视频修复神器DiffuEraser来了,ComfyUI一键擦除穿帮/水印/杂物](https://blog.liuan.org/wp-content/uploads/2025/03/v2-6b7170d56cefcce71156b8105e89bea5_720w-706x300.jpg)
![[ComfyUI]阿里重磅开源!视频修复神器DiffuEraser来了,ComfyUI一键擦除穿帮/水印/杂物](https://blog.liuan.org/wp-content/uploads/2025/03/v2-6b7170d56cefcce71156b8105e89bea5_720w.jpg)
一、介绍
最近阿里巴巴开源了一个最新的项目Diffueraser,用来视频修复用的,可以一键擦除穿帮/水印/杂物。
受到 BrushNet 和 Animatediff 的启发。该架构由主要的去噪 UNet 和一个辅助的 BrushNet 分支组成。BrushNet 分支提取的特征在经过零卷积块后逐层整合到去噪 UNet 中。去噪 UNet 执行去噪过程以生成最终输出。为了增强时间一致性,在自注意力和交叉注意力层之后都加入了时间注意力机制。去噪后,使用模糊掩码将生成的图像与输入的掩码图像进行混合。
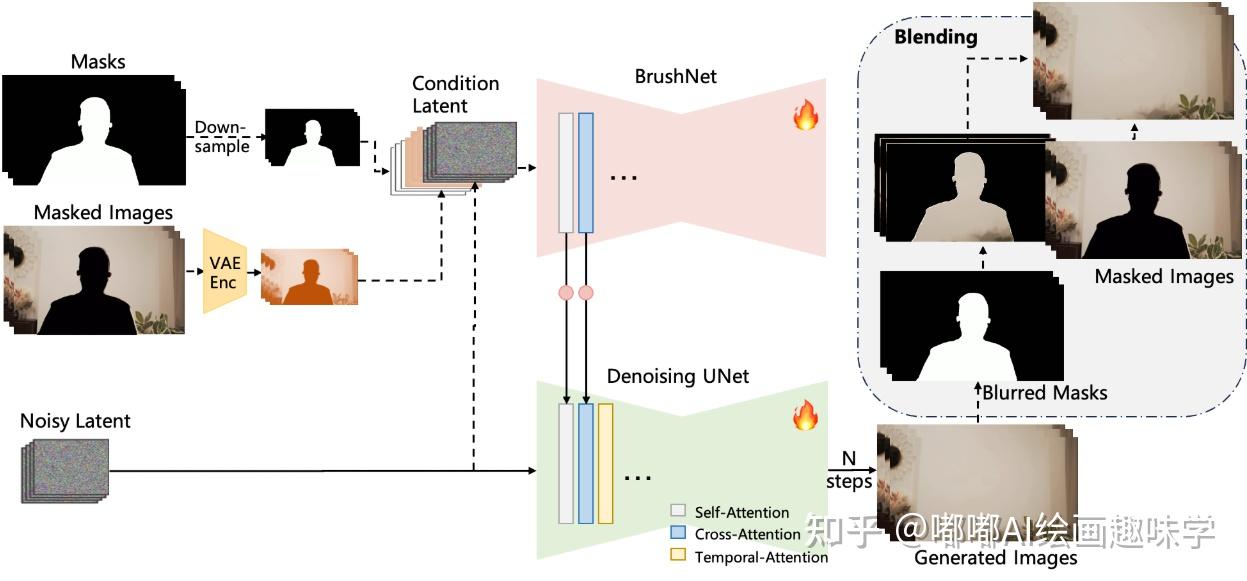
官方:https://github.com/lixiaowen-xw/DiffuEraser
二、相关安装
插件地址:https://github.com/smthemex/ComfyUI_DiffuEraser
节点管理器还搜不到
自己下载了丢custom_nodes即可
模型挺多的,核心模型如下
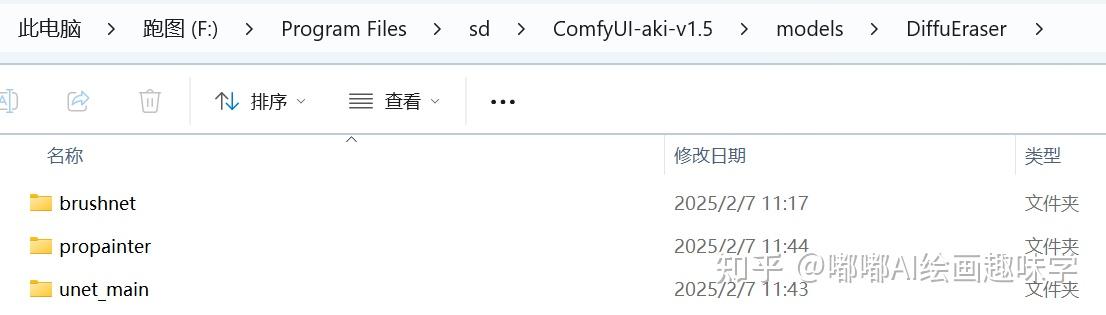
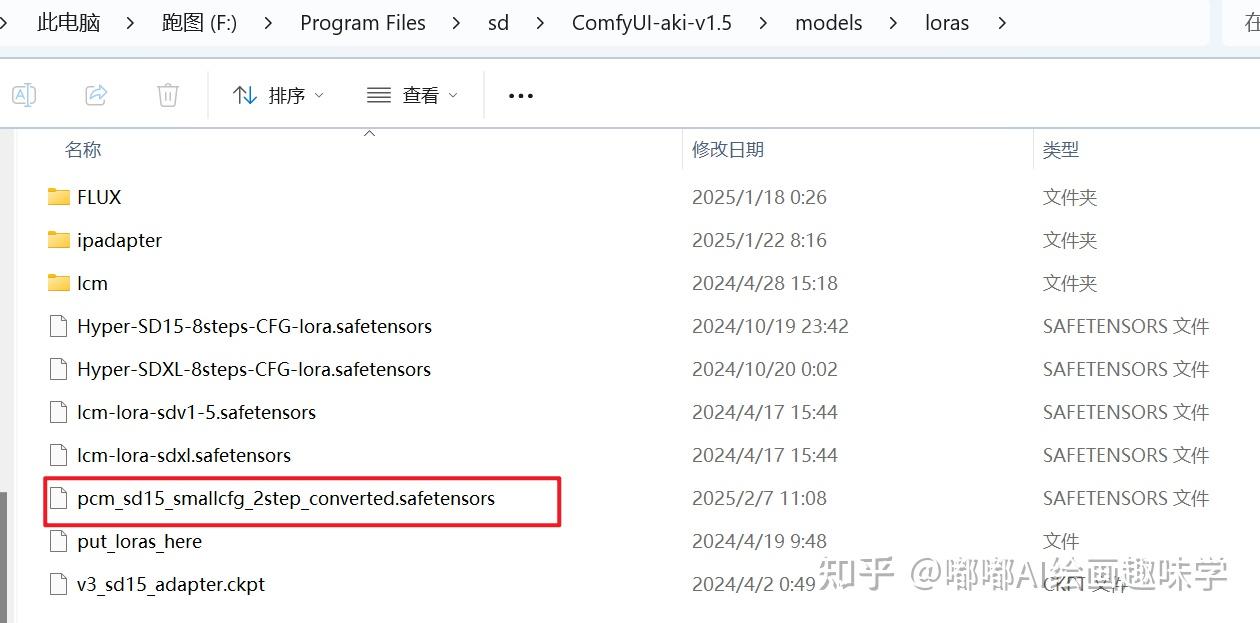
还需要一个PCM模型,放到lora目录下
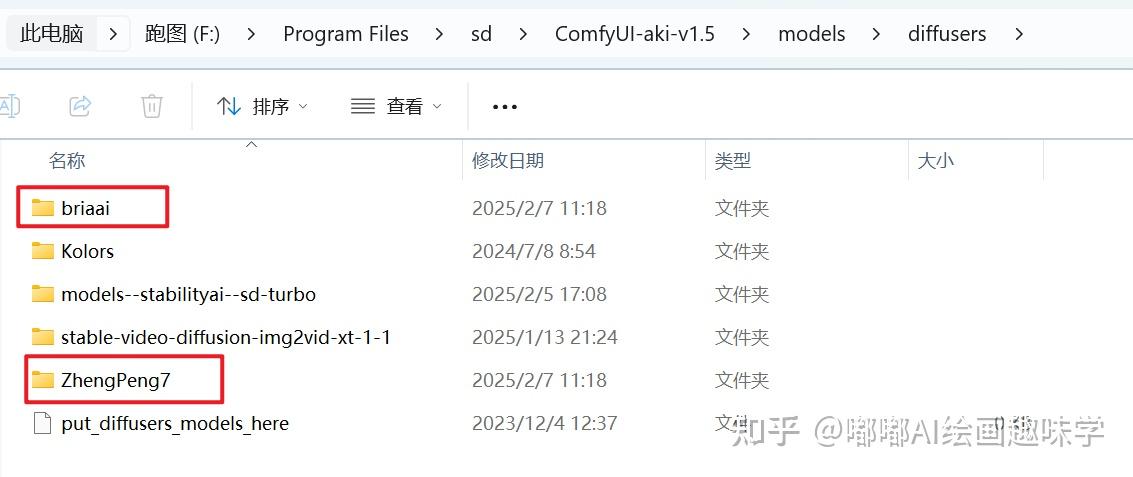
如果要自动建议处理,还需要下面红色框圈中的2个模型,分别是RMBG-2和BiRefNet,都是熟悉的扣主体的插件了。
文末网盘会提供这些给大家,自行提取
三、使用说明
核心工作流有2个,这个官方有给出
第一个是自动扣主体,然后消除了
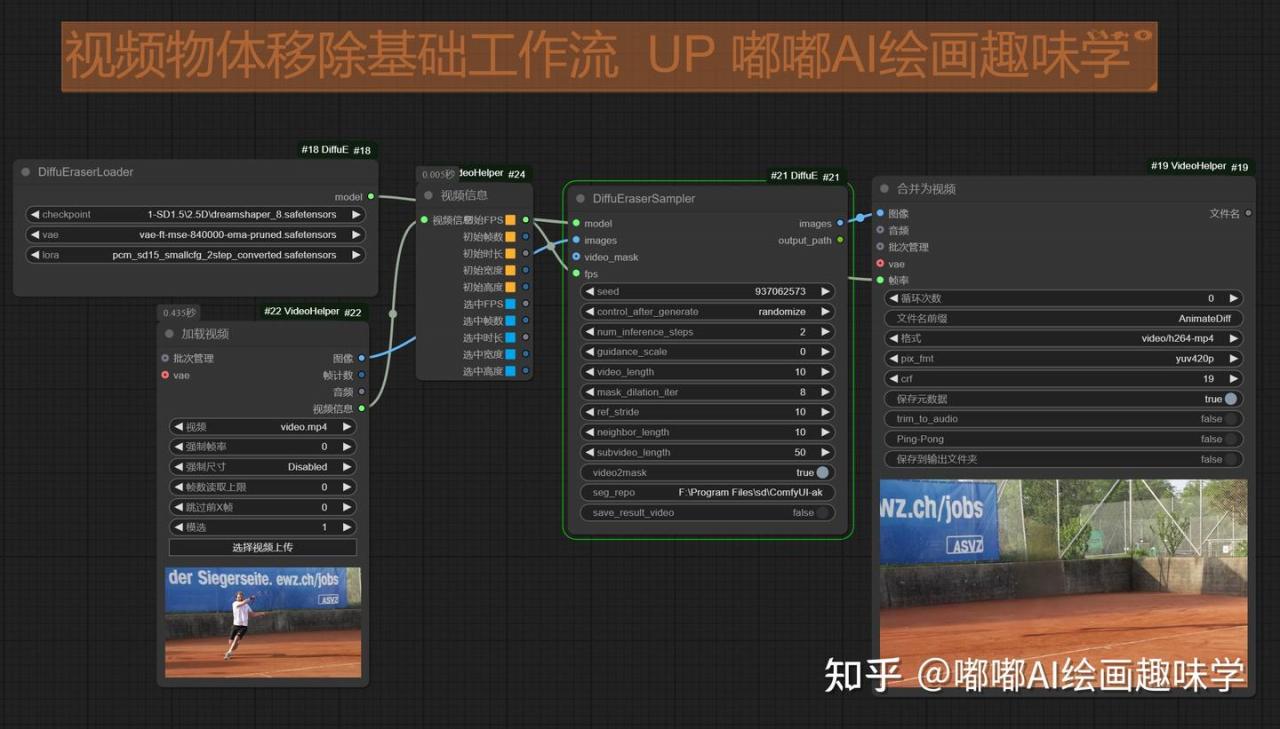
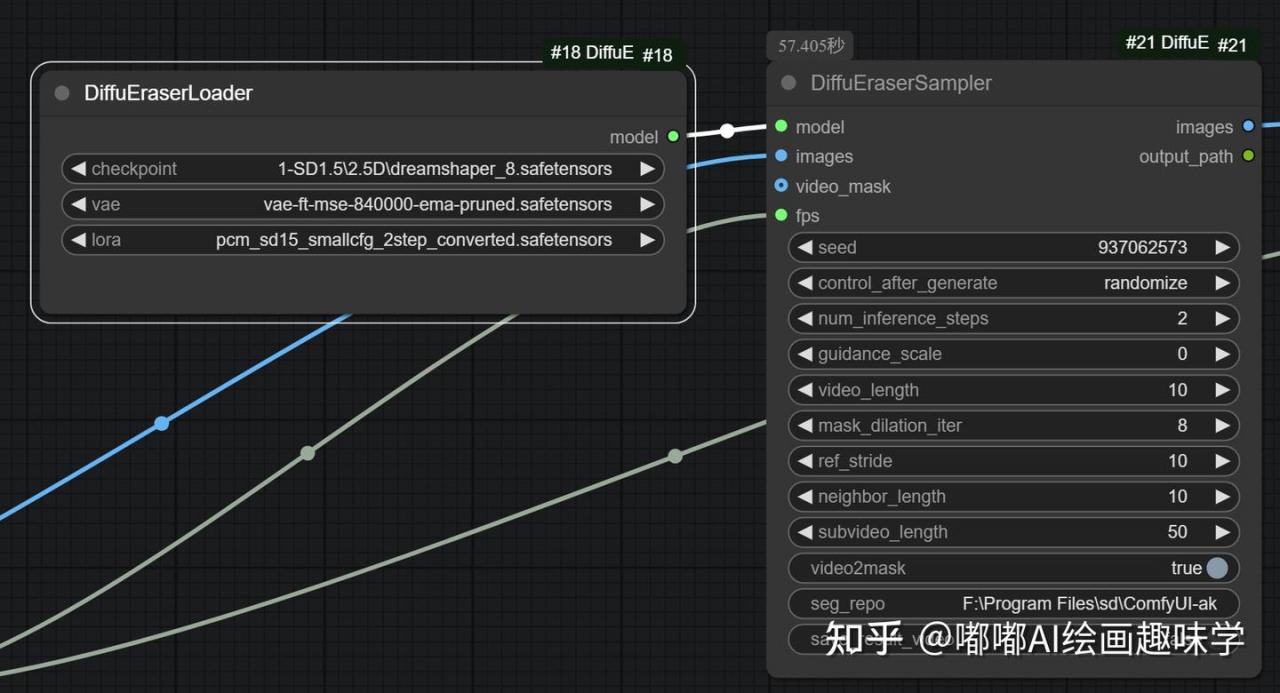
核心节点如下
左边是加载模型用的DiffuEraserLoader节点,一共有3个
checkpoint:随便选一个SD 1.5的模型,我这里用了dreamshaper8
vae:选一个SD1.5常用的vae模型即可
lora:选择上面发的pcm模型,这个模型让我们提速用的,步骤2步就可以使用了
右边是DiffuEraserSampler节点
参数按我截图的配置即可,默认就这样
需要自己调整的是
video2mask参数选中的话,才会自动扣主体
然后seg_repo这个参数需要自己填写,填模型存放的路径
这个模型也会分享给大家,放到\models\diffusers下面就行
F:\Program Files\sd\ComfyUI-aki-v1.5\models\diffusers\briaai\RMBG-2.0
执行完效果如下:效果还行,不过认真看好像还是有点人影。

第二种方案是遮罩视频自己上传
video_mask这个入参用来接一个遮罩的视频
然后记得把video2mask关闭
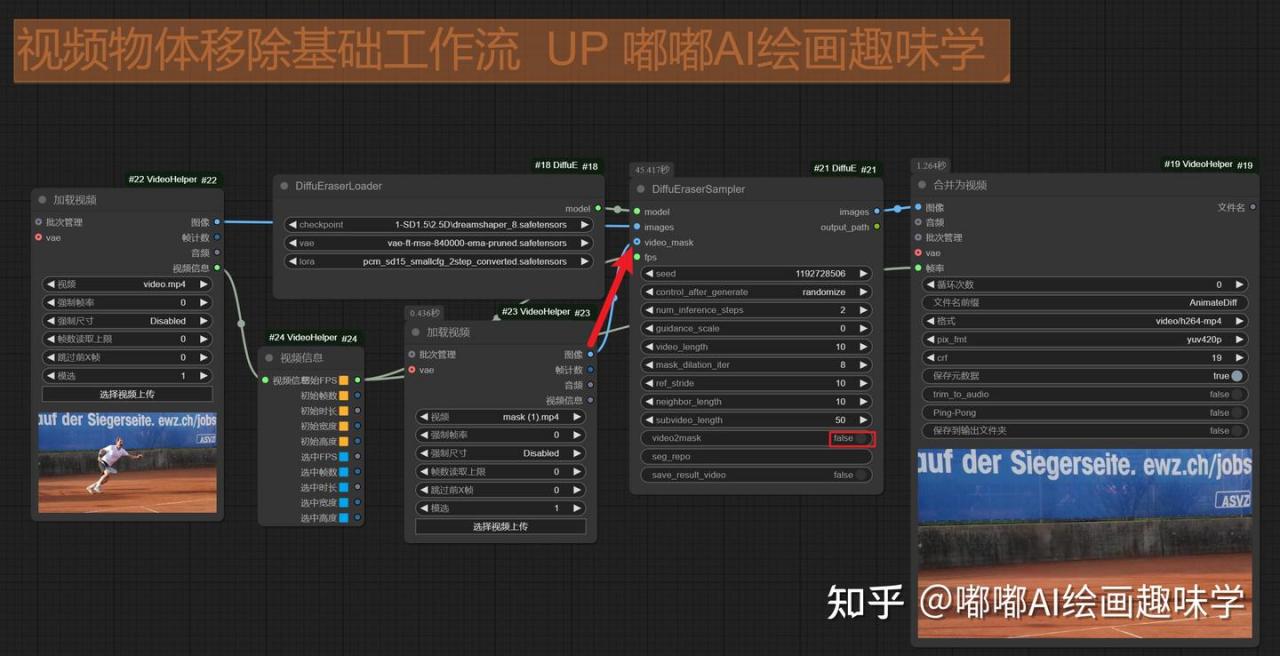
效果如下

那有人就会问了,没有遮罩视频,想怎么弄呢,也有办法
以前写过一篇介绍SAM2的,我们这里可用SAM2分割来获取遮罩的图片,再接入到video_mask参数即可。
这是我用下来感觉最好的,工作流如下
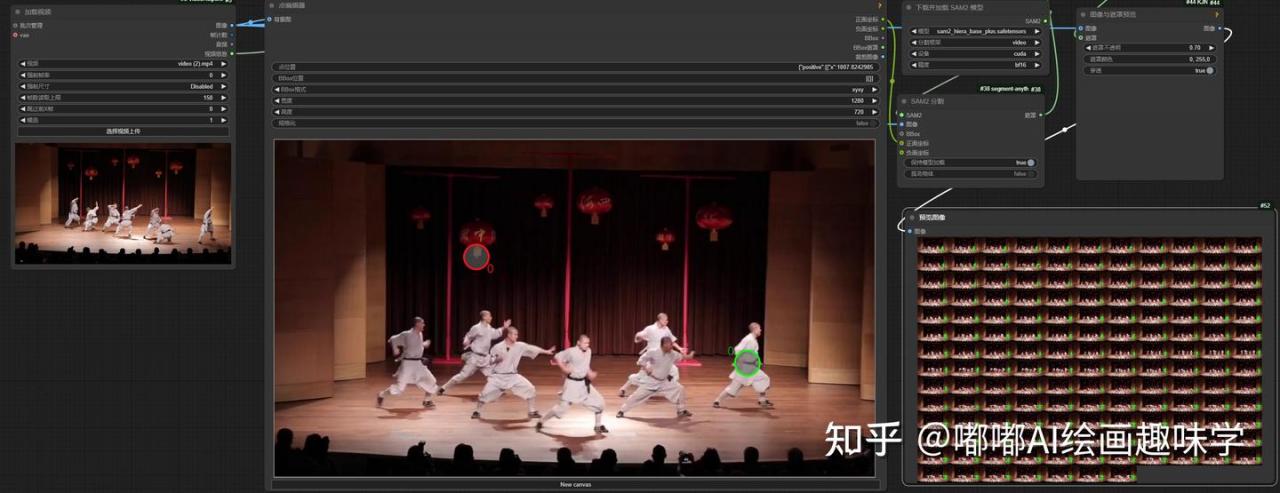
点编辑器这里,点击下面的New Canvas,生成一个面板
然后先跑一帧图,接下来就是移动绿色的点和红色的点
shift+鼠标左键:新增一个绿点
shift+鼠标右键:新增一个红点
绿点就是你要提取的遮罩,红点就是不要提取的
然后把这个遮罩当做参数接入到 DiffuDraserSampler的 video_mask即可
再看一个我跑的效果,这么多人,我就想消除右边这个人
我还想到了用来处理字幕水印的,用了其他的节点
不过效果和其他线上的工具比差不多,但是离完美还差点意思
希望这个模型后续可以继续优化

四、总结
以上就是视频消除模型的介绍了,挺有意思的,我感觉去字幕这个再强一些,可以商用了。
技术的迭代是飞快的,要关注最新的消息才不会掉队。
嘟嘟每天分享最新的ComfyUI技术前沿。
本篇中的工作流和模型网盘链接:https://pan.quark.cn/s/c8666dfb117c
我是嘟嘟,专注于 AI 绘画以及 AI 工具分享,更多内容可以进我的个人主页查看,欢迎来一起交流。
如果觉得文章有帮助,请帮忙点赞收藏关注一下呦~