Dify接入这套n8n自动化方案后,能吞下整个微信公众号了(可自动更新),直接封神!【一】
大家好,我是袋鼠帝
一直以来我都有一个痛点,就是我想把我所有的公众号文章导入我的私有知识库,并且在我 后续发布新文章的时候,可以自动导入 。
我做公众号私有知识库的目的很简单,就是想打造一个数字分身,替我回答粉丝朋友的一些AI相关的问题。 _
一直以来也做了多次尝试,但都没有找到一个令我满意的方案。 比如 腾讯元器 可以做到这一点,但是我并不太想用它,因为它 自由度太低了。
直到这个假期,我再次投入时间来研究,终于有了一套比较满意的方案 我现在最常用的私有化部署的知识库还是Fastgpt,因为它开源免费,相对轻量,而且RAG效果好,还可以提供API,MCP,能非常方便的集成到外部应用中。我知道还有很多朋友在用dify。 所以,本次我会先把我的公众号历史文章(169篇)全部抓取下来,导入fastgpt、以及dify的知识库。
然后在通过n8n监听我的公众号最新文章,自动将后续增加的文章导入fastgpt、dify知识库,同时也自动保存一份到本地文件夹。 这套方案不仅对自己的公众号适用,同样也可以用来 抓取其他博主的公众号文章 (用来学习可以,但是请不要用于商业目的)。 除了可以用来保持知识库自动更新,还可以用于 热点监控,爆文分析 等等,用处非常多。 整个工程相对较大,所以 我准备分2篇文章来介绍 好了,话不多说,我们开始第一篇的喂饭~
通过API获取公众号数据
其实这套流程里面, 最难的就是自动获取公众号数据源 ,众所周知,公众号的文章等信息,官方并没有直接提供API接口,很难批量自动获取公众号数据。 所以,我第一步是打开了最近常用的Agent- Skywork
_ 通常一起用的还有:Flowith、MiniMax的Agent、Gemini DeepResearch、纳米AI超级搜索等… 搜索结果可以互相参考 _
全网搜索,能批量获取公众号数据的方案 Skywork很快就给到了我以下几个非常符合我需求的方案
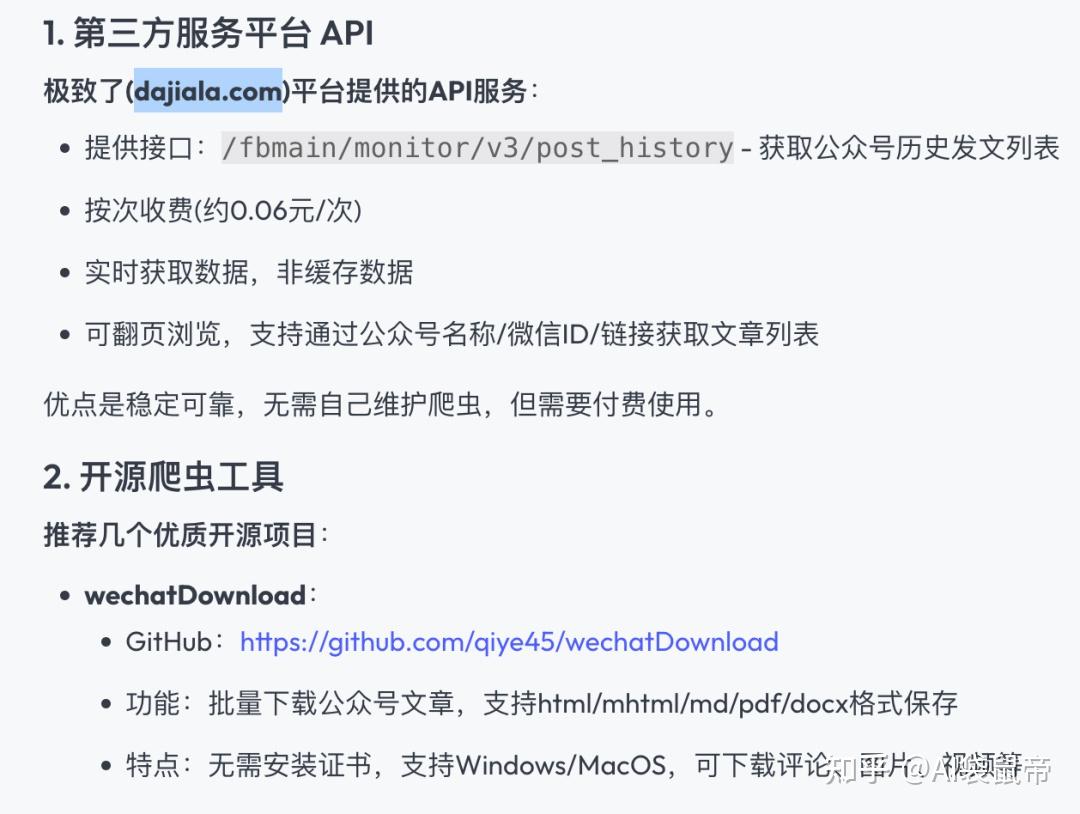
第一个方案 是 一个付费的API平台(极致了):
API功能相当丰富

第二个方案 是开源项目,提供了三个开源项目,第2、3个项目都太老了,已经5年以上没有更新了 而第一个开源项目: wechatDownload ,最近一次更新就在上个月。
它可以批量导出某个博主的公众号文章,但它 不提供API,是一个桌面应用
当然,通过抓包或许可以找出它所调用的API接口,有研究过的朋友欢迎在评论区分享~
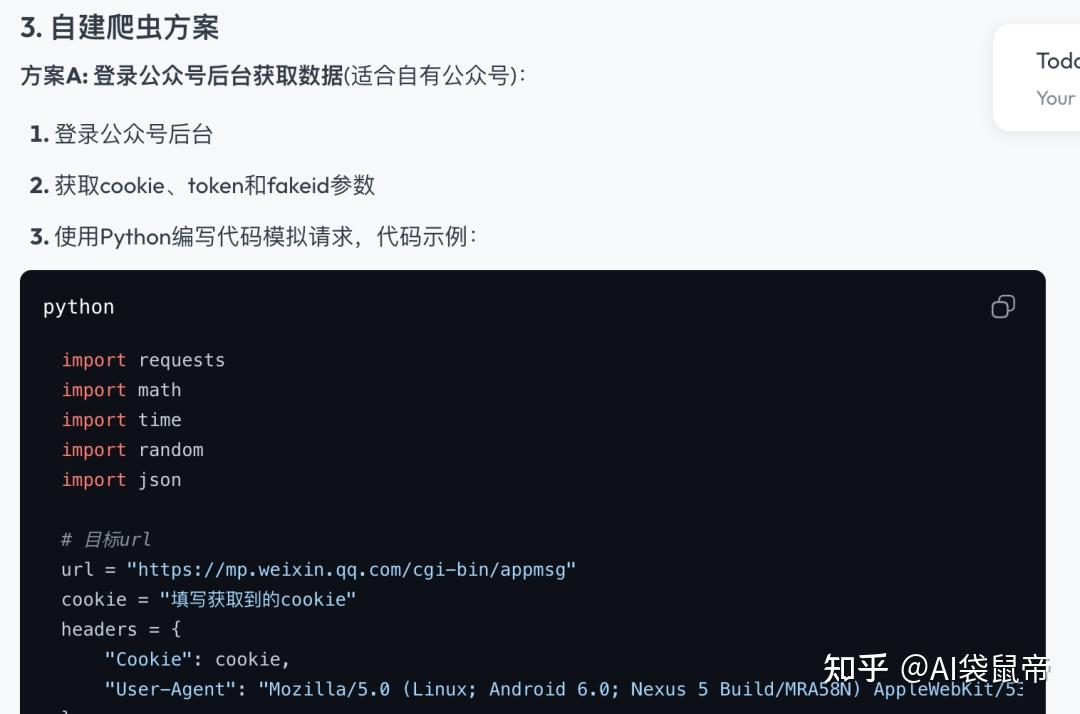
第三、四个方案其实都是利用公众号后台的这些API
比如文章的编辑页,添加超链接,打开之后就能获取到某个账号的历史文章列表可以通过F12,network去查看所调用的API。 _
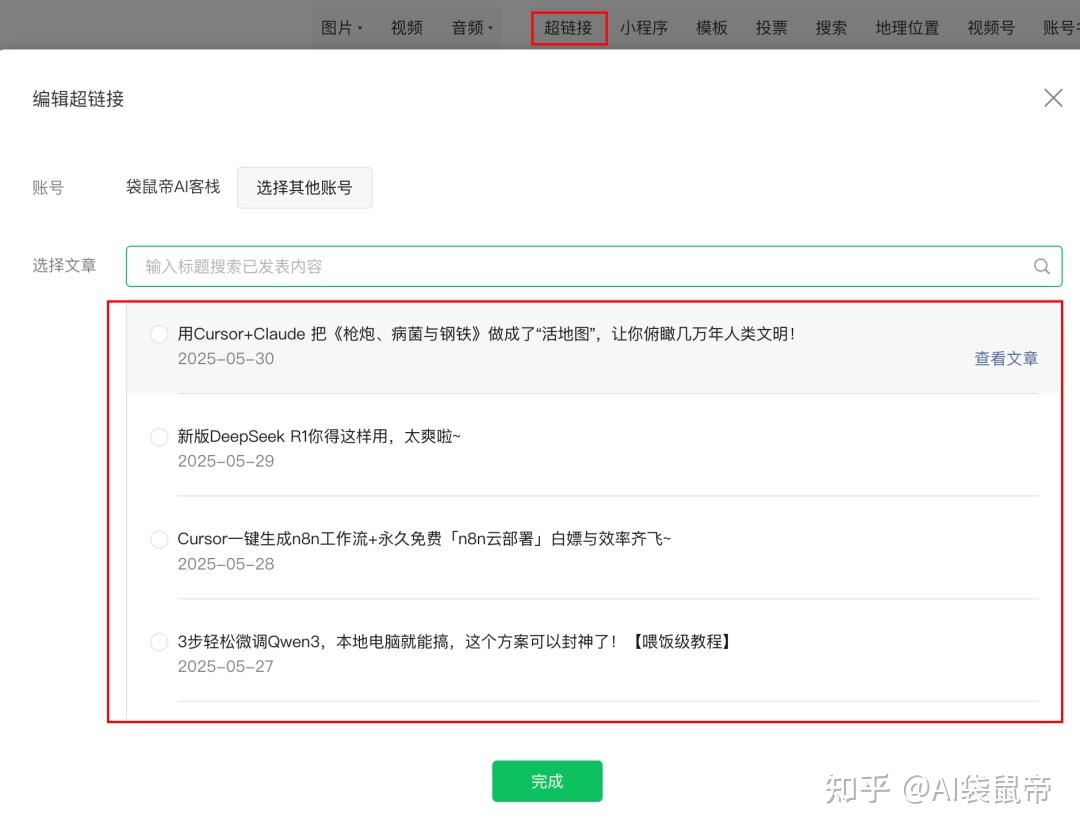
__ 但是这个方案依赖有效的cookie(登录凭证),一旦登录状态过期,得手动更新cookie,比较麻烦,不符合我们全自动的要求。 _ _
综合考虑,我选择了付费API平台和开源的wechatDownload 另外, 带DeepResearch的Agent真的是抹平信息差的一大利器 ,推荐大家都用起来,信息获取的效率提升太多了 可以看看我之前写的DeepResearch应用相关文章 Skywork 和 AI超级搜索
批量获取历史文章
第一步,我们 先获取历史文章导入知识库 说实话,历史文章,咱们没必要去搞API批量全自动了
_ 除非你想要批量获取几十上百个博主的公众号文章,可以用上面说的付费API去自动获取 _
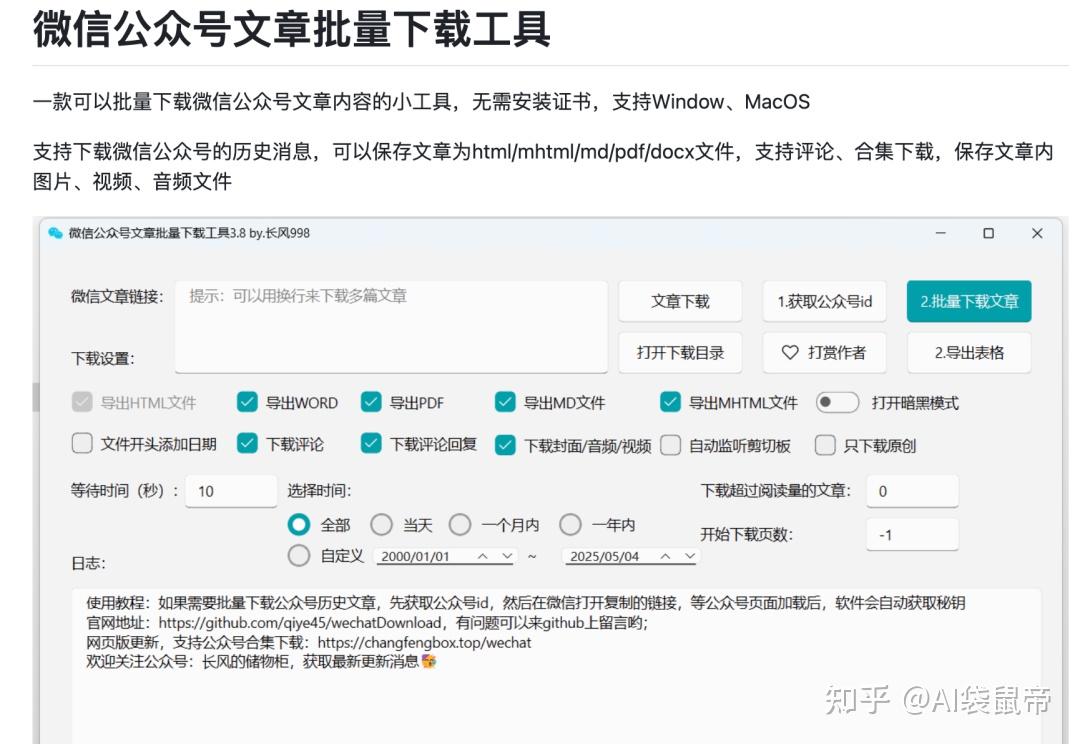
所以我选择wechatDownload,它支持Windows、Mac安装
_ wechatDownload一次只能获取一个公众号的历史文章 _
https://github.com/qiye45/wechatDownload

我选择使用Windows版本,因为Mac的看着版本号比较老,才2.6… 下载之后,解压,双击打开.exe文件 复制一篇我的文章的链接,粘贴到下图的1处,点击 获取公众号id
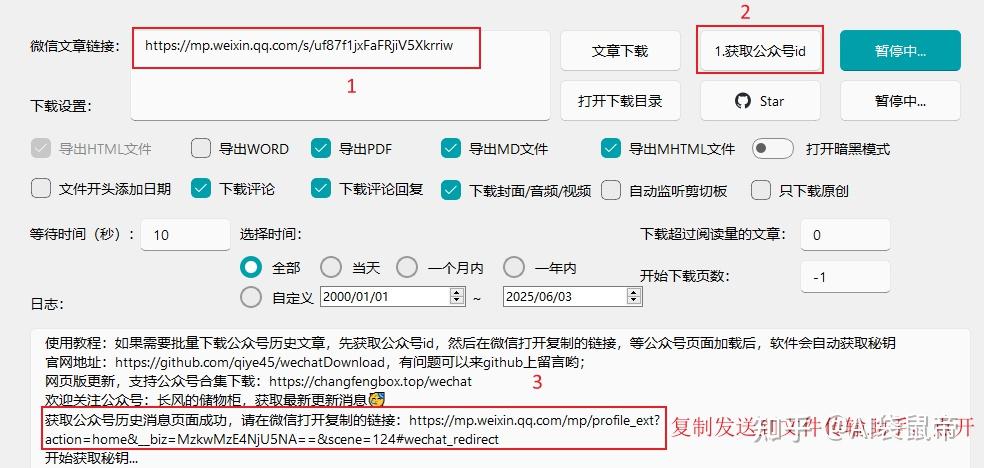
随后复制上图中序号3红框里面的链接,发送到微信文件传输助手,点击打开,其实就是所有历史文章的页面。
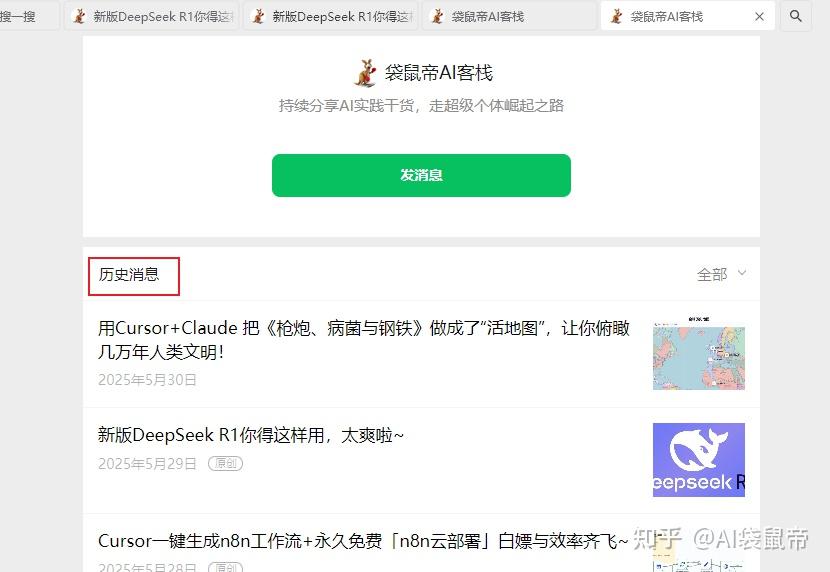
这时就静静等待一会儿,直到日志中显示: 获取密钥成功! 选择好要导出的格式,点击右上角 批量下载文章
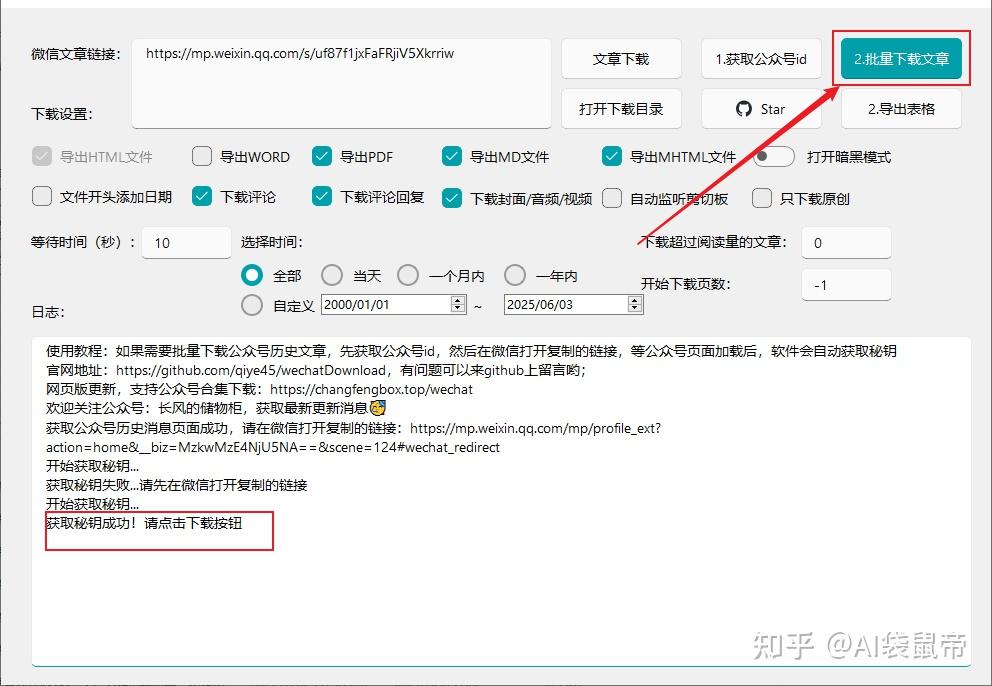
接下来就是等待。为了防止被限制,他会爬一批之后暂停一段时间再继续 但是部分文章的评论会下载失败
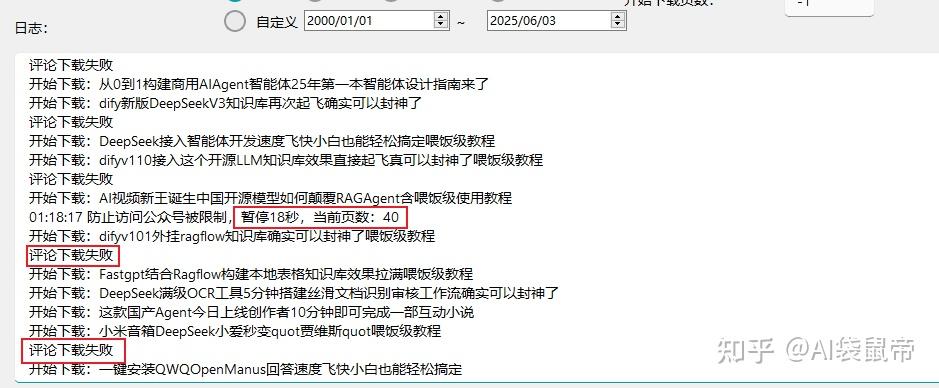
大约过了20分钟,终于导出完毕了
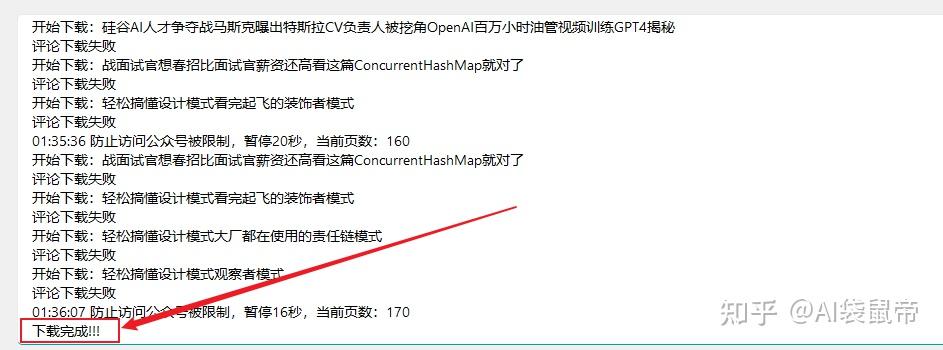
在下载工具所在目录的/下载 文件夹下,可以找到导出的文章
在fastgpt中导入的时候,打开这个文件夹,如果导出了多种格式,可以搜索.md的文件,全选导入即可。
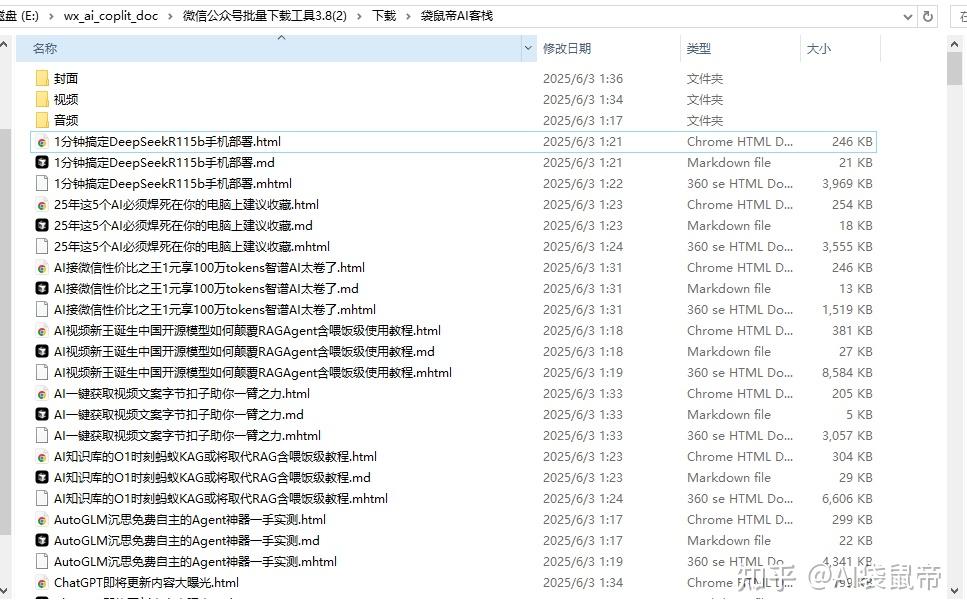
不过这个方案还是有点问题,放到 公众号 文件夹里面的是导出失败的文章
看了一下有35篇失败(可能需要手动处理一下) 其中135篇成功的文章是在袋鼠帝AI客栈文件夹里
还有另外一种更好的方案
咱们先 获取所有历史文章的url链接 ,然后通过链接其实也能获取文章内容
还记得上面讲的付费API平台吗
我们可以用到这个 获取公众号历史发文列表的API
https://apifox.com/apidoc/shared/410674f9-f451-4b4f-957a-5f54f243bc83/api-199746415
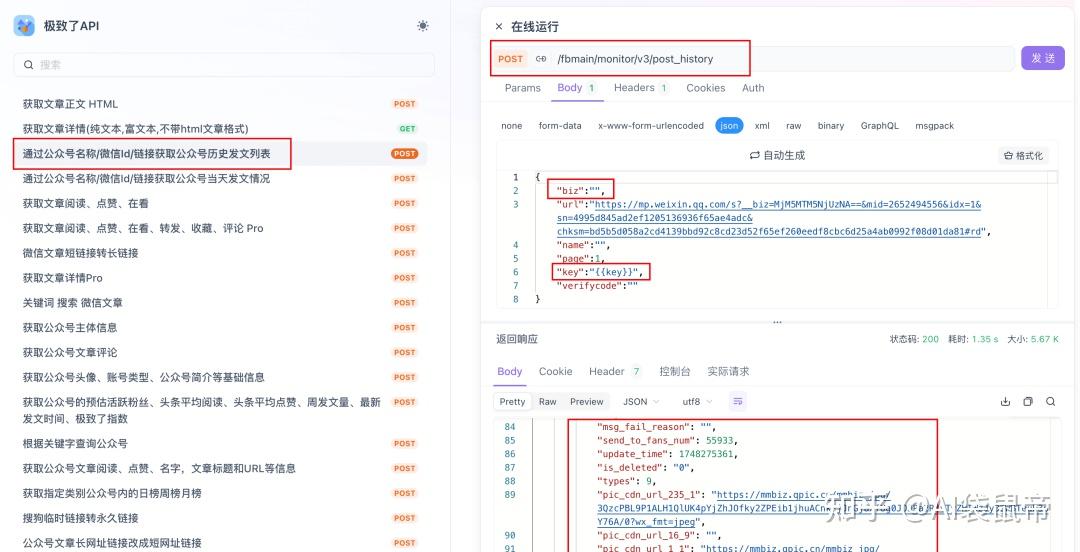
这个获取历史文章的 API价格是0.06元/次 然后这个获取历史发文的API并不是一次性获取所有,而是分页获取, 每页固定只返回5条数据 返回的json数据每条长下面这样,说实话,数据挺丰富的, 有url地址,发文时间,封面图的url,标题,摘要,通知的粉丝数等等
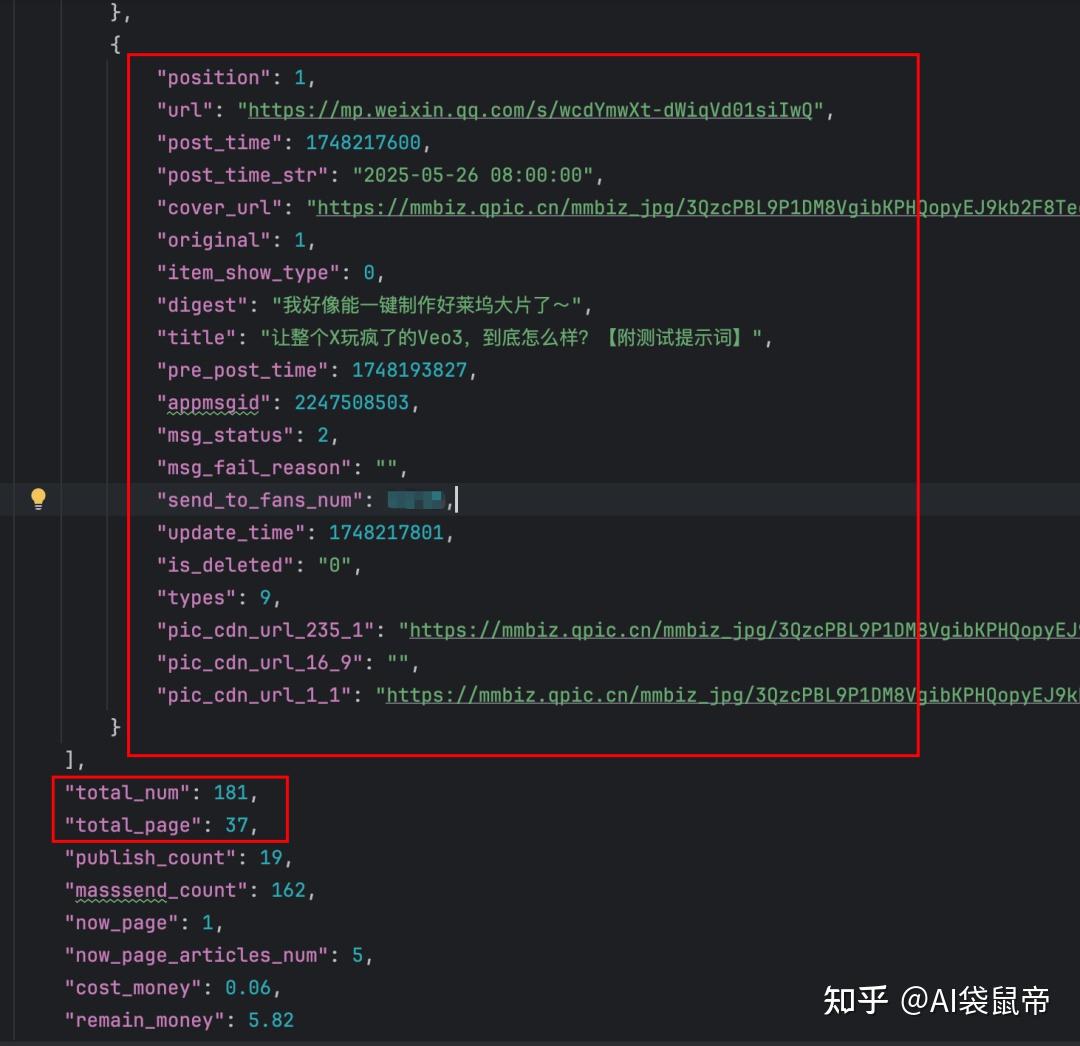
可以看到一共有37页,也就是说,要获取所有的文章链接需要请求37次
37*0.06=2.22元 ,还好,可以接受。
然后我就把请求地址,请求参数,响应数据丢给Gemini,并告知需求 让它帮我写一个Python程序,批量获取我的文章url链接
三连这篇文章后,在 公众号(袋鼠帝AI客栈)后台私信:“历史文章代码”, 即可获取这个Python文件
运行这个代码需要两个参数:
公众号的biz,极致了平台的apikey
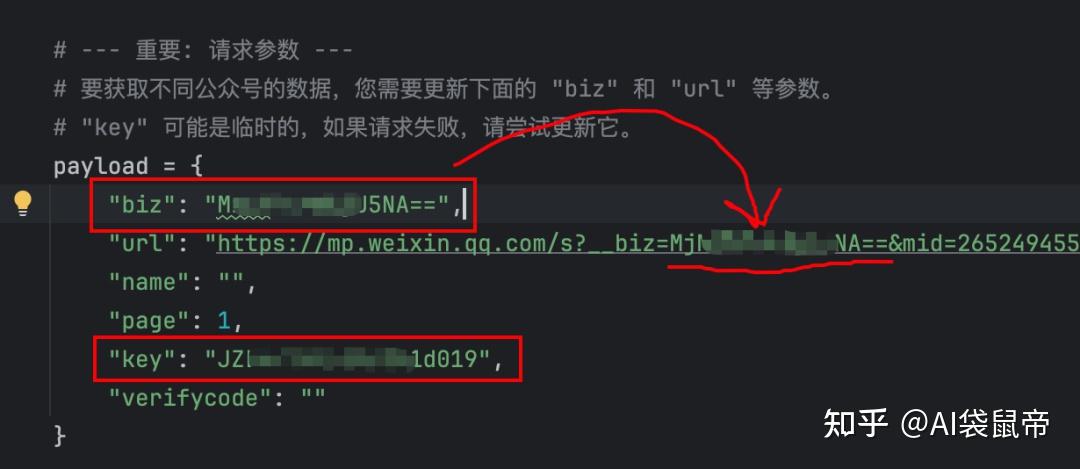
公众号biz的获取方式:
1.先在浏览器打开一个公众号文章,右键->显示网页源代码
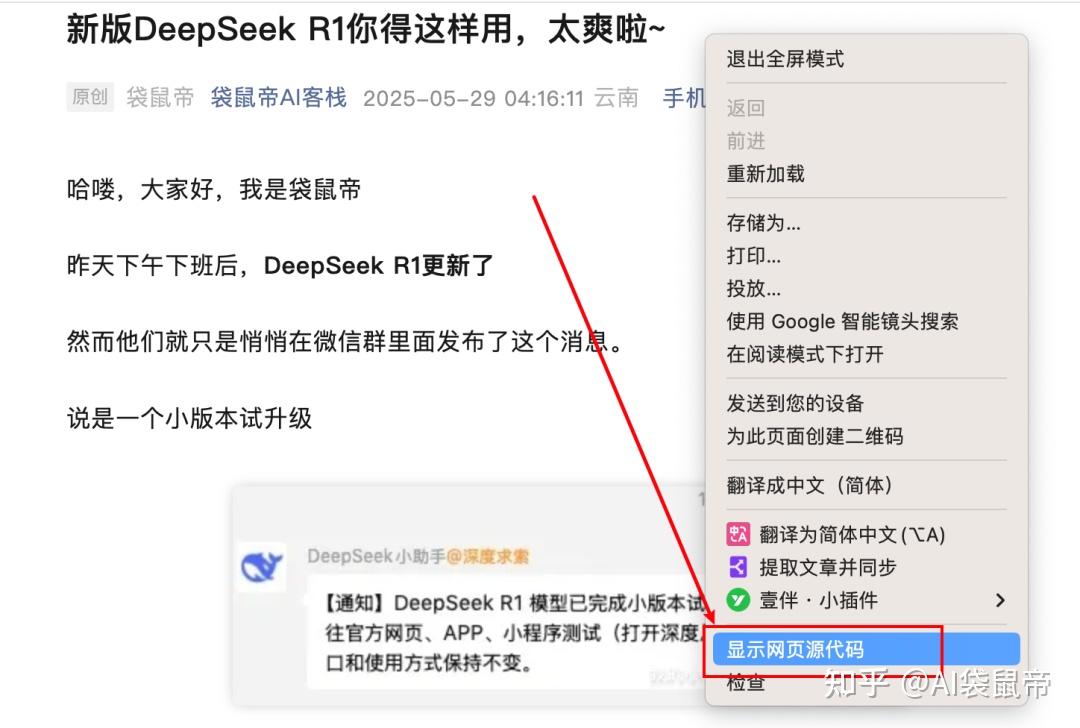
2.ctrl+f,全局搜索__biz= 下图红框里面的就是biz的值,复制备用

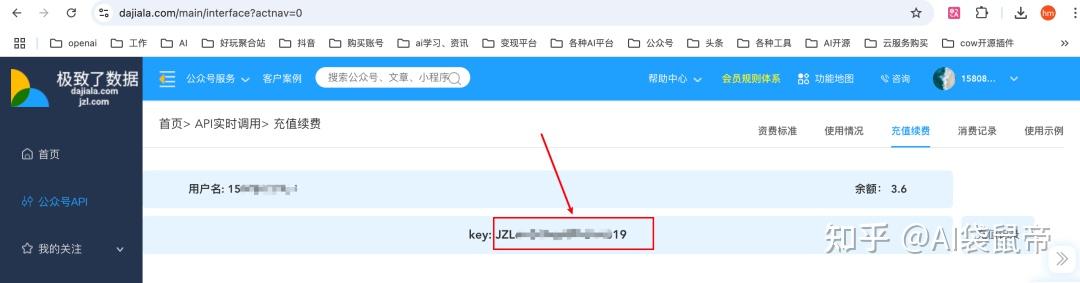
极致了平台apikey获取: https://www.dajiala.com/main/interface?actnav=0 复制下图位置的key
配置好biz和key之后,就可以直接执行了 差不多1分钟左右的时间,就搜集完毕

会在代码的当前目录生成两个文件: urls.txt和all_data.json
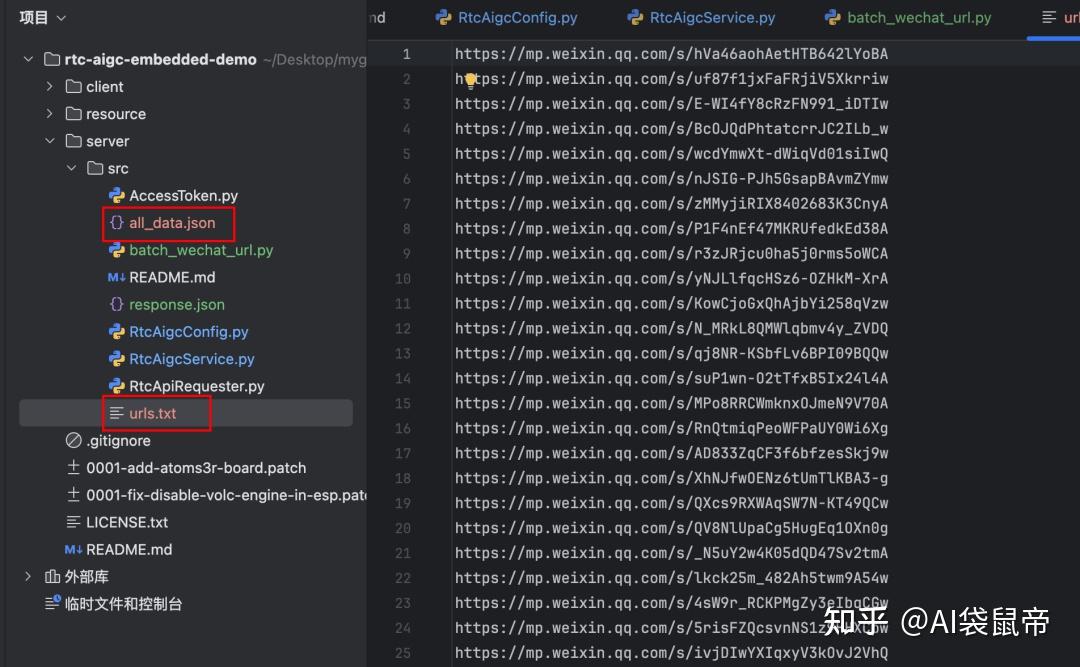
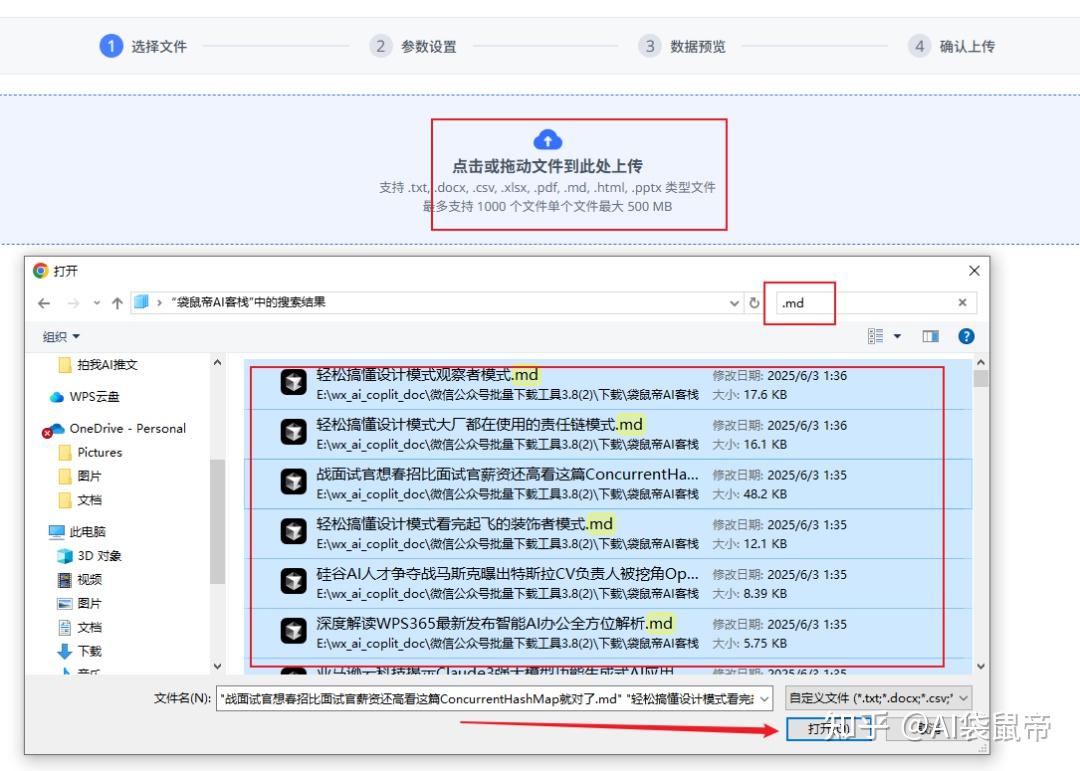
urls.txt里面搜集了所有的文章链接 all_data.json里面搜集了所有的json元数据,组成了一个巨大的json数组。 最后打开刚刚那个开源项目- wechatDownload的网页版 https://changfengbox.top/wechat 开启批量下载,把urls.txt的所有链接复制粘贴上去,这里我只选导出txt格式(可以排除图片链接),点击批量下载
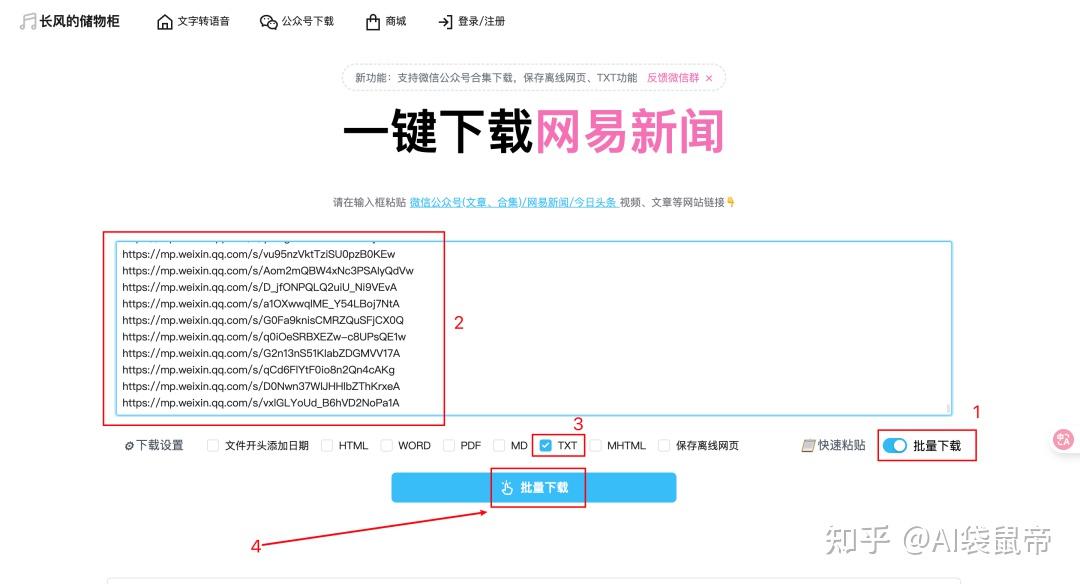
浏览器会不停的一个一个下载,直到结束
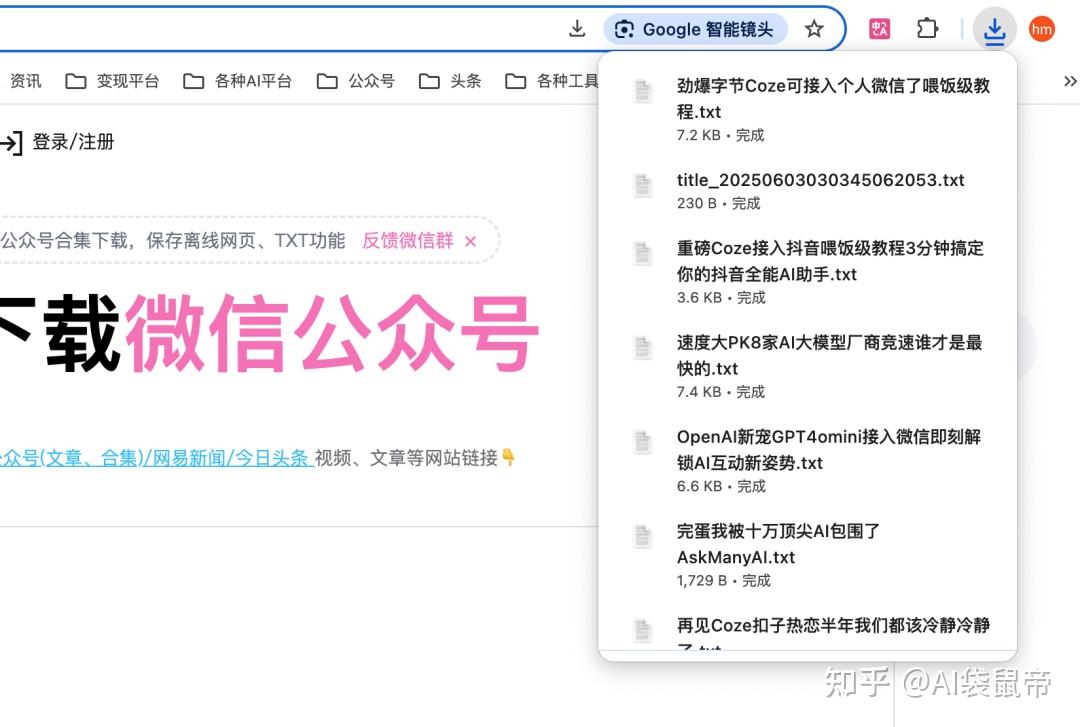
批量下载完毕!收工~
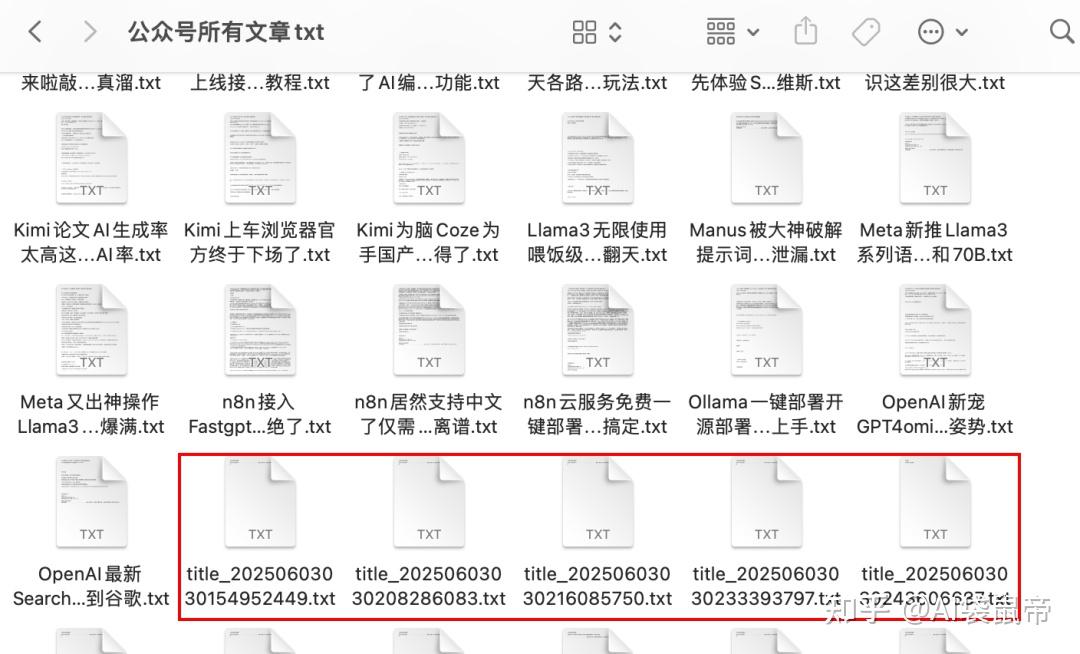
有些没有正确标题的文章是被删除的记录,不用管,到时候去掉就行 好了,这篇就先讲批量下载历史文章 至于导入fastgpt和dify知识库,这个简单操作不用我再讲了吧 下一篇讲如何利用n8n监听后续新增文章,自动导入fastgpt知识库,以及dify知识库。 以及这篇中的批量获取公众号文章url的代码,也会转为n8n的工作流放到下篇。 感兴趣的朋友可以点手关注,如果想第一时间收到通知,可以给我一个星标。
END
为了更方便大家互相交流和学习,我还创建了一些群聊: AI交流群、AI硬件群、n8n交流群、AI开发者群、微调群。
群里面有AI开发者,创业者,AI爱好者,还有各行各业想用AI赋能、提效的朋友,经常讨论最新的AI资讯,AI工具,AI技术,变现方法等等
如果你对这些群感兴趣,可以 在公众号(袋鼠帝AI客栈)后台私信我加入
私信内容: “进群”
** 能看到这里的都是凤毛麟角的存在!
** 如果觉得不错,随手点个赞、在看、转发三连吧~
** 如果想第一时间收到推送,也可以给我个星标 ⭐
