Python爬虫 这个网址图片怎么弄下来?
首先,我们需要进行页面结构分析,确定图片url是否存在于静态网页当中:
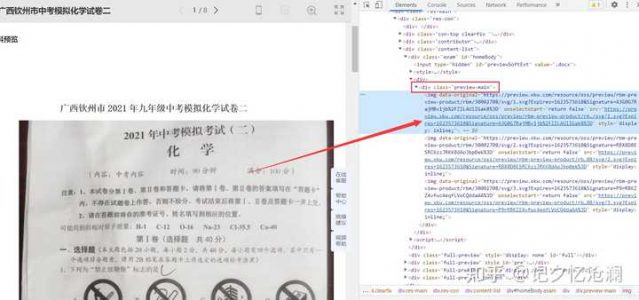
第一步:鼠标选中第一张图片,然后右键选择检查:
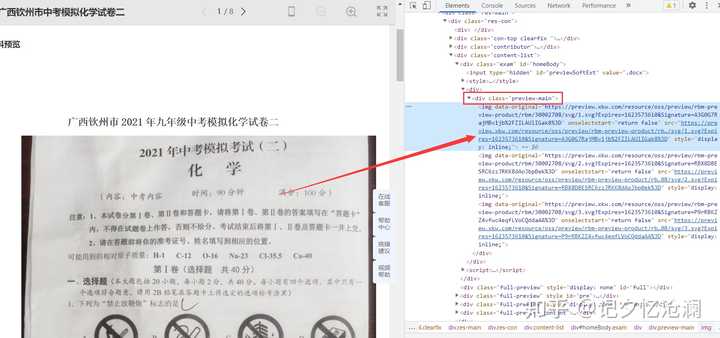
可以明显看到<img>标签的父标签是<div class="preview-main">
第二步:鼠标右键空白处选择查看网页源代码 ,并ctrl + F搜索关键词preview-main:
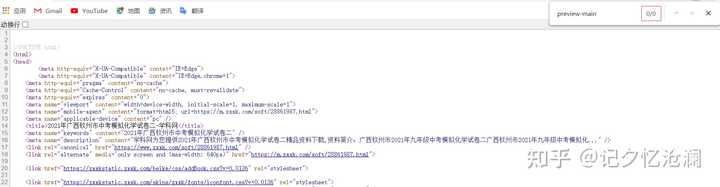
显然没有找到,这也就告诉我们,图片很可能是通过动态方式加载出来的,一个一个去分析接口是很不理智的,这里我们通过开发者工具中search 帮我们快速找到真正的接口:
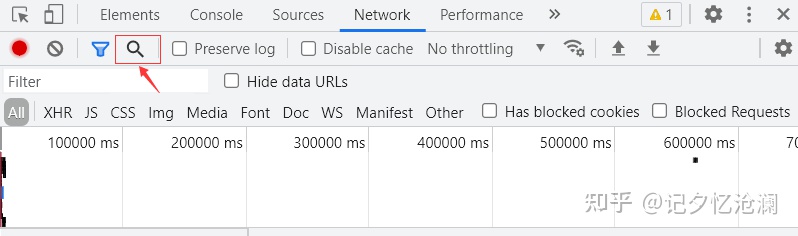
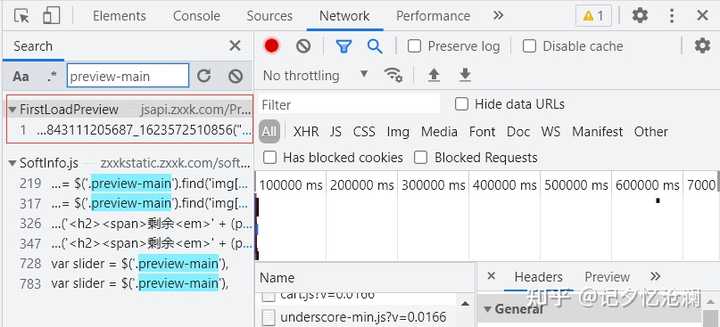
通过这种方式可以很快帮我们缩小查找范围,这里的第一个结果就是我们要的,直接双击它:
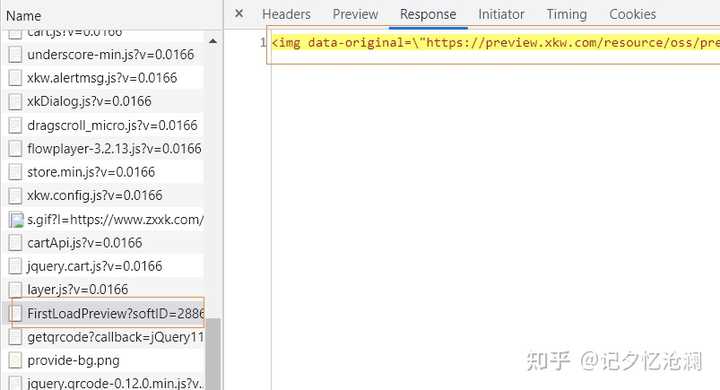
这不就是我们想要的么,OK,我们把这个接口整体copy出来,import导入PostMan来调用接口:
上面框出来的FirstLoadPreview?softID=2886198 直接鼠标右键选择Copy ,然后再次选择Copy as cURL (bash) 将其整体复制出来
打开PostMan工具,选择import 导入方式来创建:
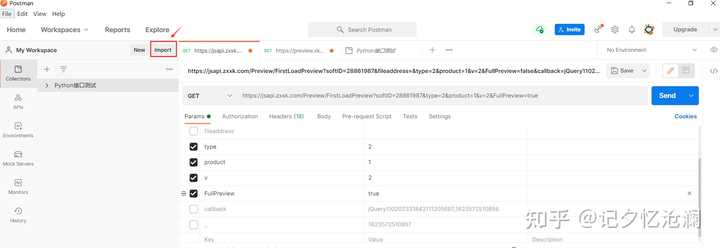
选择Raw text ,把刚才复制过来的整体内容粘贴到空白处即可,最后点击Continue :
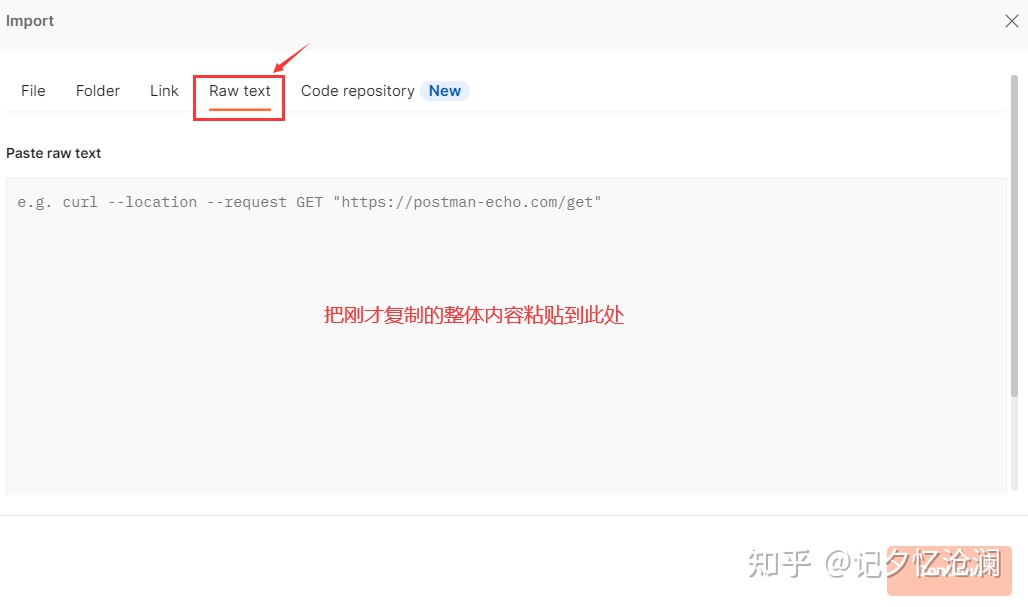
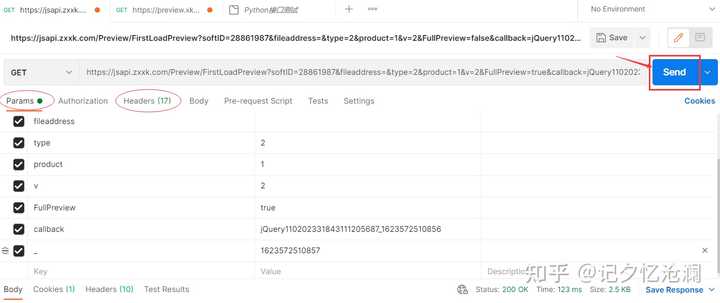
Params和Headers自动填充完毕,什么都不用管,直接点击Send来调用接口发送请求:
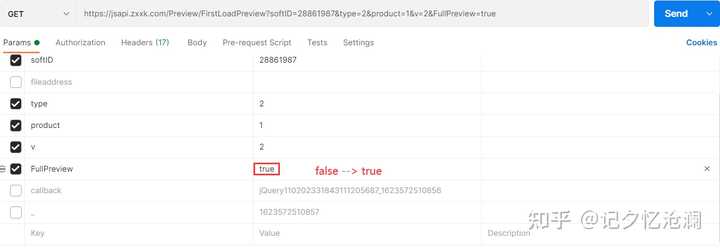
我们知道如果没有付费,那么你只能看3张图片,剩余5张图片是不可见的,有没有办法让我们看到所用的图片呢?
这里需要说一下,我们只需要勾选和去勾选来测试哪些是有用参数,以及参数的效果,就是因为这一点儿的便捷,所以我选择PostMan工具,它一方面可以辅助测试Params,也可以测试Headers下的一些参数,来确定究竟哪些是必须的参数,以及参数的作用效果。
经过一番测试,发现callback、Key和fileaddress是可以删掉的,另外把FullPreview 的值由false置为true 你会看到奇效,8张图片的请求url都可以拿到:
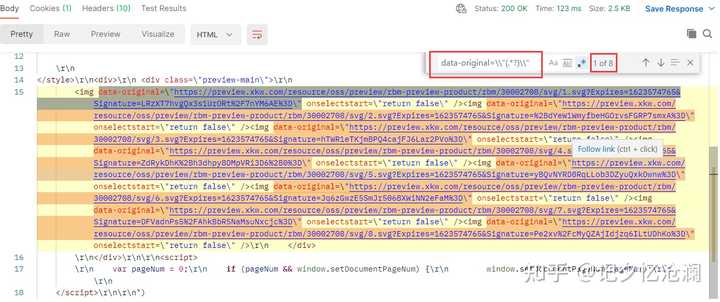
这里通过data-original=\\"(.*?)\\"正则表达式匹配出来8条数据,恰巧就是我们要的。
OK,第一阶段的工作算是做完了,我们直接拿这个url去请求,获取二进制数据,然后写入图片文件这样就哦了?
我们手动复制第一条的data-original的值在浏览器中打开看看效果:

看来没有啥大问题,咱开始编写代码,快速实现一下:
import re
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'
}
url = 'https://jsapi.zxxk.com/Preview/FirstLoadPreview'
params = {
'softID': '28861987',
'type': '2',
'product': '1',
'v': '2',
'FullPreview': True
}
response = requests.get(url, params, headers=headers)
img_urls = re.findall(r'data-original=\\"(.*?)\\"', response.text)
for index, img_url in enumerate(img_urls):
image_data = requests.get(img_url, headers=headers).content
with open(f'{index+1}.png', 'wb') as f:
f.write(image_data)代码运行OK,没有报bug,打开下载的图片瞅瞅:
这么做明显不对,楼主也是在这儿卡主了,不知道该如何破解这个问题?
我们需要分析一下,到底是哪一个环节出了问题,这里采用倒推法,从我们最后一步开始说起:

打开开发者工具,刷新网页,第一个请求1.svg?Expires=1623582287返回的并不是二进制数据,我们知道对于音频、视频或图片,都是二进制数据,但这里返回的是一个文本数据,该怎么办?
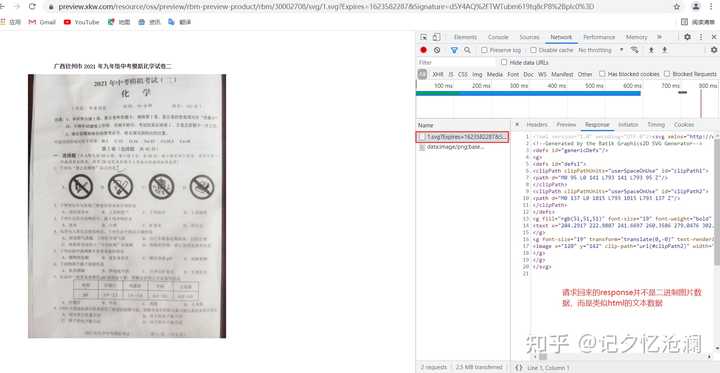
别着急,我们细细看看这个返回的文本数据,能否找到一点儿蛛丝马迹。
哎,你发现了么,这里第一个请求返回的结果中有和第二个请求相似的东西存在:
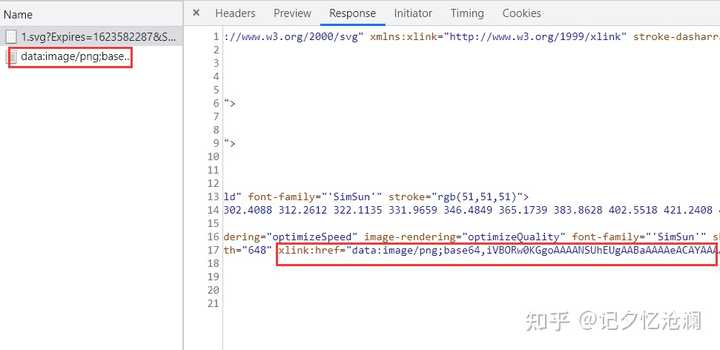
接着我们瞅瞅第二个请求:
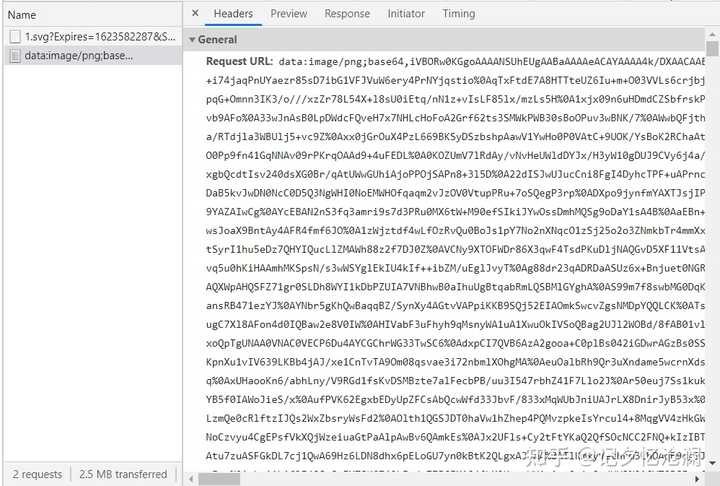
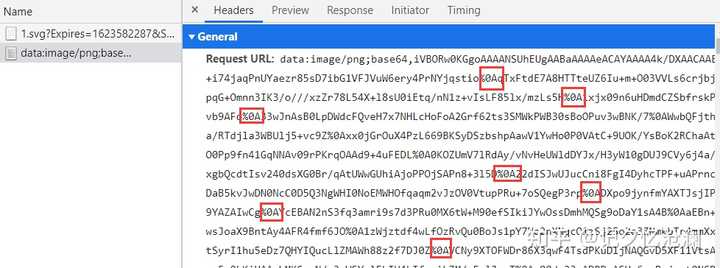
请求头Request URL和第一个请求得到的响应数据中的xlink:href的值相同,另外点击Preview查看这明显就是我们的图片:
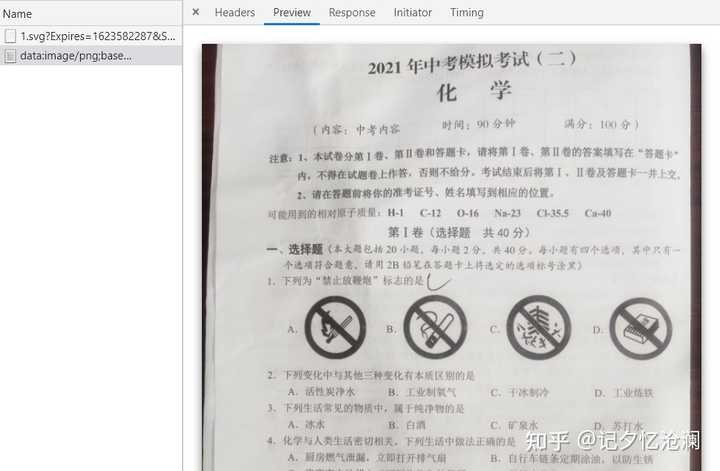
于是解决问题的思路就有了,首先请求刚拿到的data-original,从返回的文本数据中得到xlink:href的值,然后请求xlink:href的值,得到二进制数据,最后写入文件就可以得到想要的图片了。
在编写代码之前呢,有一个东东我得给你说一下: 需要转义成%0A
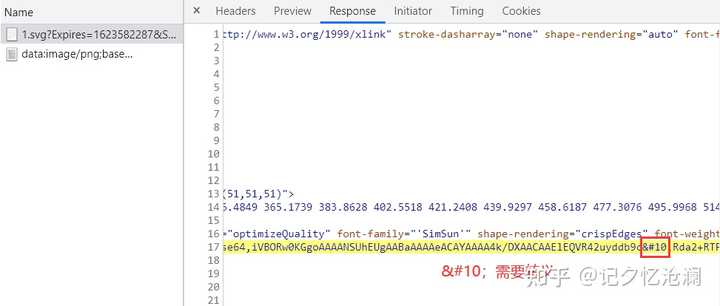
不要问我怎么知道的,实际操作一把,打印输出结果,相信你也会找到这一点儿,在这直接告诉你,可以省去你一些时间。
urlretrieve可以帮我们下载并保存为的图片,只需要一行代码就OK了。
全部代码如下:
import re
import requests
from urllib.request import urlretrieve
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36'
}
url = 'https://jsapi.zxxk.com/Preview/FirstLoadPreview'
params = {
'softID': '28861987',
'type': '2',
'product': '1',
'v': '2',
'FullPreview': True
}
response = requests.get(url, params, headers=headers)
img_urls = re.findall(r'data-original=\\"(.*?)\\"', response.text)
for index, img_url in enumerate(img_urls):
image_data = requests.get(img_url, headers=headers).text
image_base64 = re.search(r'xlink:href="(.*?)"', image_data)
if image_base64 is None:
continue
image_base64_url = image_base64.group(1)
image_base64_url = image_base64_url.replace(' ', '%0A')
urlretrieve(image_base64_url, f'{index + 1}.png')

不过第7张图片有点儿问题,暂时没有想到好的解决办法,如果您有好的idea请在下方评论或私我都可以。
本案例的脚本和文字切勿拿去做商业或其它用途。