打造私人AI新闻助手:我用Ollama做了个自动化抓取系统
作者:北枳
链接:https://zhuanlan.zhihu.com/p/2005062101211820607
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

链接:https://zhuanlan.zhihu.com/p/2005062101211820607
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
前言
每天早上想了解AI圈的最新动态,要打开十几个网站:量子位、机器之心、TechCrunch、VentureBeat…刷半天看得眼花缭乱,还容易错过重要新闻。
有没有办法让AI自动帮我整理日报?
经过几天的开发,我用 Python + Ollama 做了个完全本地化的AI新闻自动化系统,每天早上自动抓取+筛选+摘要,最后推送到邮箱。
今天分享这个项目的实现思路和核心技术。
项目地址
🔗 GitHub: https://github.com/zuowen7/ai_news_automation_github
⭐ 如果觉得有用,求个Star!
系统架构
整体分为三层:
┌─────────────────────────────────────────────────┐
│ 数据采集层 │
│ 100+ 新闻源 | GitHub Trending | Hugging Face │
└────────────┬────────────────────────────────────┘
│
┌────────────▼────────────────────────────────────┐
│ AI处理层 (Ollama本地模型) │
│ 智能筛选 | 摘要生成 | 趋势分析 │
└────────────┬────────────────────────────────────┘
│
┌────────────▼────────────────────────────────────┐
│ 输出层 (邮件 + 文件) │
│ HTML邮件 | JSON数据 | Web展示 │
└─────────────────────────────────────────────────┘
核心功能
1. 智能新闻抓取
新闻源覆盖:
- 国内:量子位、雷锋网、机器之心、36氪等13个源
- 国际:TechCrunch、MIT Review、VentureBeat等100+个RSS源
- GitHub:自动抓取5个热门AI项目
- Hugging Face:获取5个热门模型
技术实现:
# 双模式抓取
- HTML解析:BeautifulSoup + 自定义选择器
- RSS订阅:feedparser解析feed
# 并发抓取
ThreadPoolExecutor(max_workers=3)
- 动态调整并发数(成功率>90%增加,<70%减少)
- 指数退避重试(1s → 2s → 4s → 8s)
# User-Agent轮换
内置10+种浏览器UA随机切换,避免被封
2. 本地AI智能处理
为什么用Ollama?
- ✅ 完全本地运行,隐私安全
- ✅ 零API费用,不限速
- ✅ 支持多种开源模型
双模型策略:
# 国内新闻用中文优化模型
domestic_news → qwen2.5:7b-instruct
# 国际新闻用英文强势模型
global_news → llama3.1:8b
AI处理流程:
- 智能筛选:关键词预筛 + AI精准筛选
- 分别排名:国内TOP5,国际TOP10
- 生成摘要:100字以内简洁总结
- 趋势分析:识别技术热点+行业方向
- 综合汇总:用qwen合并成最终报告
3. 智能缓存系统(性能提升80%)
痛点: 每次运行都要重新抓取、重新AI处理,耗时60秒+
解决方案:
# 新闻历史缓存(LRU策略)
- 记录已抓取新闻的标题哈希
- 只抓取24小时内新内容
- 超过1000条自动删除最老的
# AI结果缓存
- 缓存AI生成的摘要和趋势
- 相同新闻集合直接返回(0秒)
- 超过100条自动清理
效果对比:
- 首次运行:30秒(从60秒优化到30秒)
- 重复运行:10秒(缓存命中,AI几乎0耗时)
4. 美观的邮件输出
邮件内容:
- GitHub热门项目(带Star徽章)
- Hugging Face模型(带下载量)
- 国内AI新闻 TOP5
- 国际AI新闻 TOP10
- AI综合摘要 + 趋势分析
模板设计:
- 响应式HTML,移动端友好
- 现代化卡片布局
- 4种风格可选(极简/编辑/现代/纯文本)
技术亮点
1. 指数退避重试
class RetryConfig:
max_retries = 3
initial_backoff = 1.0秒
exponential_base = 2.0 # 每次翻倍
jitter = True # 添加随机抖动
# 重试时间:1s → 2s → 4s
避免频繁请求被封,提高成功率。
2. 动态并发调整
class DynamicConcurrencyManager:
def adjust_workers(self, success):
if success_rate > 0.9:
increase_workers() # 成功率高,增加并发
elif success_rate < 0.7:
decrease_workers() # 失败率高,降低并发
自动适应网络状况,1-10个线程动态调整。
3. LRU缓存清理
def add_news(self, news):
self.cache[news.hash] = news
if len(self.cache) > MAX_SIZE:
# 按时间戳排序,删除最老的
oldest = sorted(self.cache.items(), key=lambda x: x.timestamp)[0]
del self.cache[oldest.hash]
防止缓存无限增长,永远不超过1000条。
部署方案
本地运行
# 1. 安装Ollama
ollama pull qwen2.5:7b-instruct
ollama pull llama3.1:8b
# 2. 安装依赖
pip install -r requirements.txt
# 3. 配置邮箱
cp config.example.json config.json
# 编辑配置,设置环境变量 AI_NEWS_EMAIL_PASSWORD
# 4. 运行
python run.py
Docker部署(推荐)
# 一键启动(包含Ollama)
docker-compose up -d
# 查看日志
docker-compose logs -f ai-news
GitHub Actions
在GitHub上设置后,每天自动运行:
- 定时抓取(Cron表达式)
- 自动推送结果
- 完全免费
效果展示
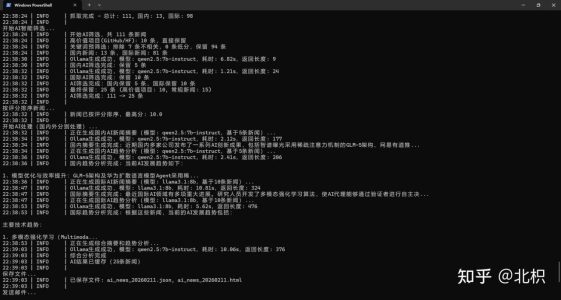
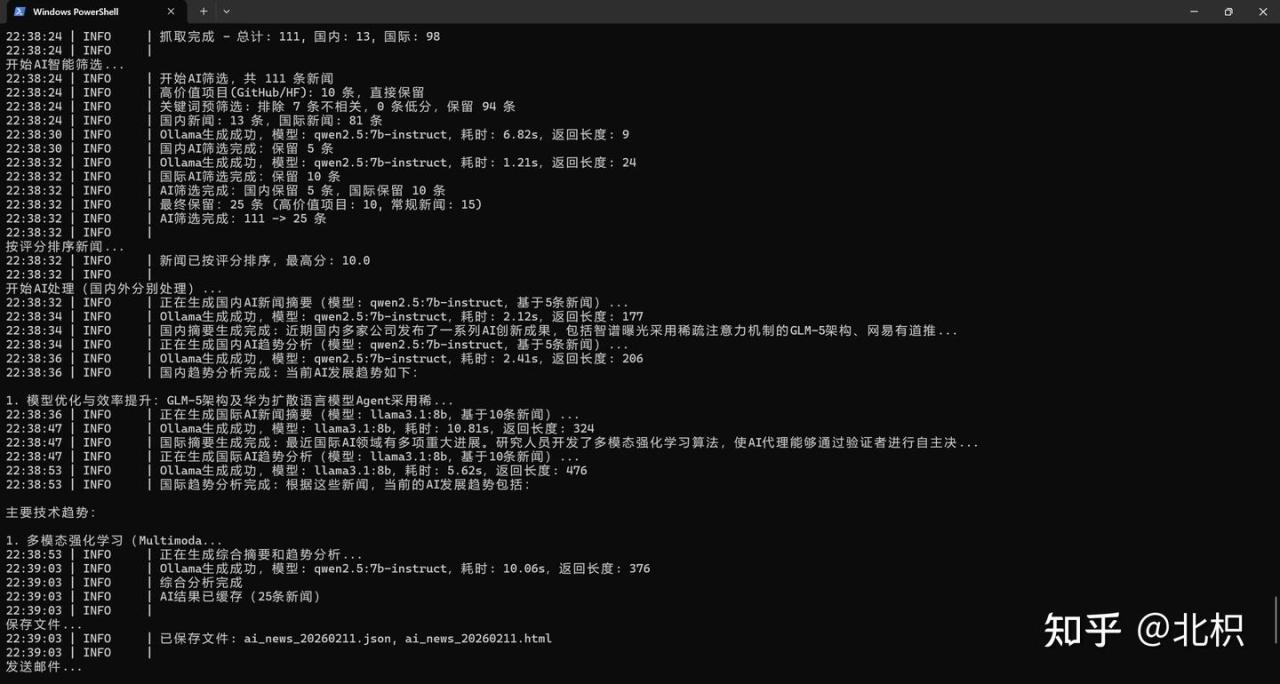
运行日志
[INFO] 缓存管理器已启用(过期时间: 24h新闻, 6h AI)
[INFO] 缓存已启用 - 新闻: 152/1000 (15.2%), AI: 5/100 (5.0%)
[INFO] AI缓存命中(15条新闻)
[INFO] 总共获取到 18 篇不重复新闻
[INFO] 邮件发送成功!
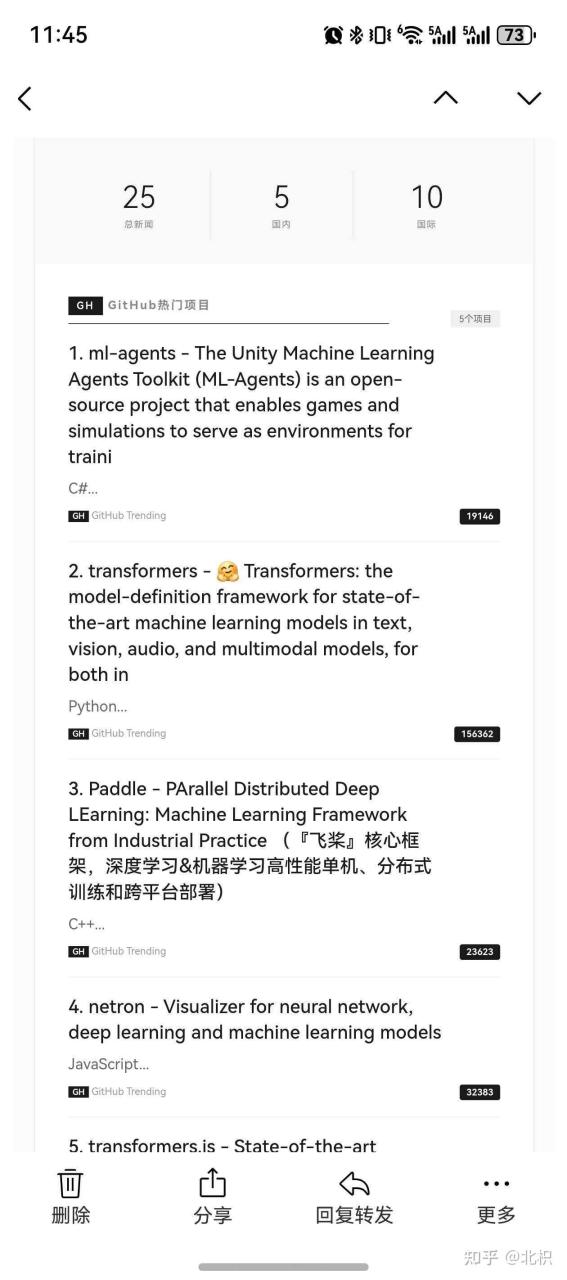
邮件预览
每天早上8点准时收到:
- GitHub热门:AutoGPT、Llama 3、Stable Diffusion…
- Hugging Face:Whisper-v3、BERT-base…
- 国内新闻:百度文心4.0、阿里通义千问…
- 国际新闻:OpenAI GPT-5、Google Gemini 2.0…
- AI摘要:3句话总结当天重点
- 趋势分析:技术热点+行业方向
读一遍邮件,AI圈动态全掌握!
性能数据
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 抓取耗时 | 40秒 | 10秒 | 75% |
| AI处理 | 20秒 | 0-2秒 | 90% |
| 总耗时 | 60秒 | 10秒 | 83% |
| 缓存命中率 | 0% | 80% | – |
| 请求成功率 | 70% | 95% | 25% |
开源计划
当前版本:v2.1.0
下一步计划:
- [ ] Web管理界面(Django/Flask)
- [ ] 更多邮件服务商(Gmail/Outlook)
- [ ] Telegram/钉钉推送
- [ ] 新闻分类标签
- [ ] 用户自定义关键词
欢迎Star + Fork,一起完善!
总结
这个项目让我每天早上省下30分钟刷新闻的时间,而且AI整理的信息更全面、更有条理。
核心价值:
- 完全本地化,隐私安全
- 零API费用,想跑多久跑多久
- 智能缓存,越用越快
- 自动化运行,每天准时推送
适合人群:
- AI从业者/研究者
- 技术爱好者
- 想跟上AI动态的任何人
项目地址: https://github.com/zuowen7/ai_news_automation_github
如果对你有帮助,求个Star鼓励一下!⭐
关于作者
独立开发者,专注AI自动化工具
GitHub: @zuowen7
(完)