爬虫如何爬取多页?
如何实现翻页爬虫
借着作者的提问,当作一个爬虫小案例去练习掌握requests + bs4 + csv ,并在此基础上学会利用pandas模块里的read_html方法快速抓取网页中常见的表格型数据。
目标需求
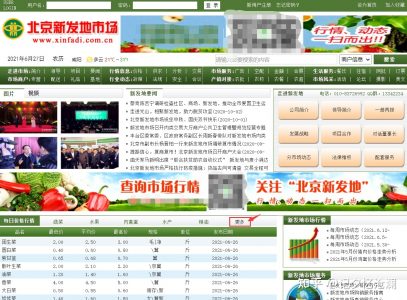
打开 北京新发地市场, 获取每一页的价格详情:
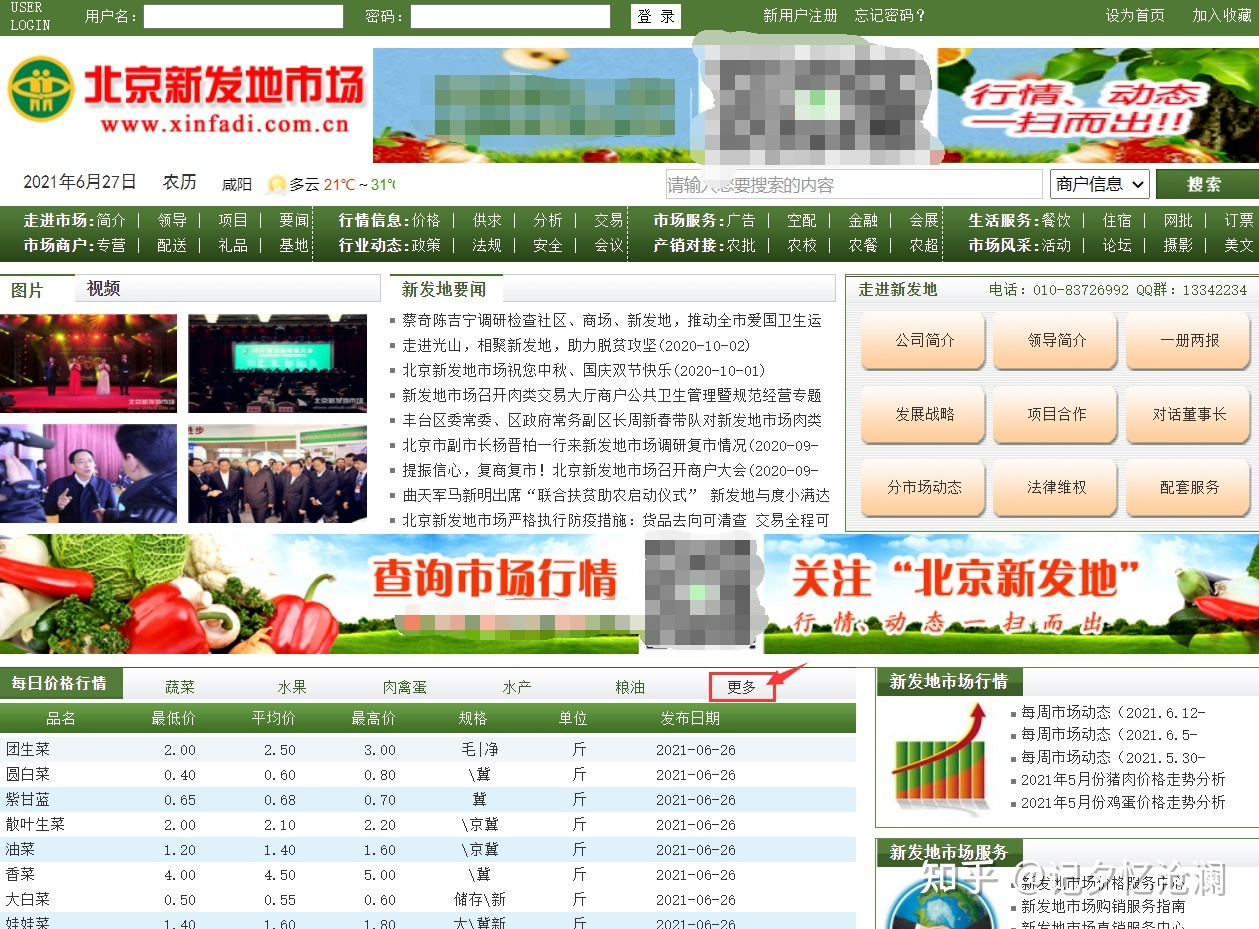
在首页每日价格行情一栏的最后,点击更多,跳转到所需的静态页面:
目标分析
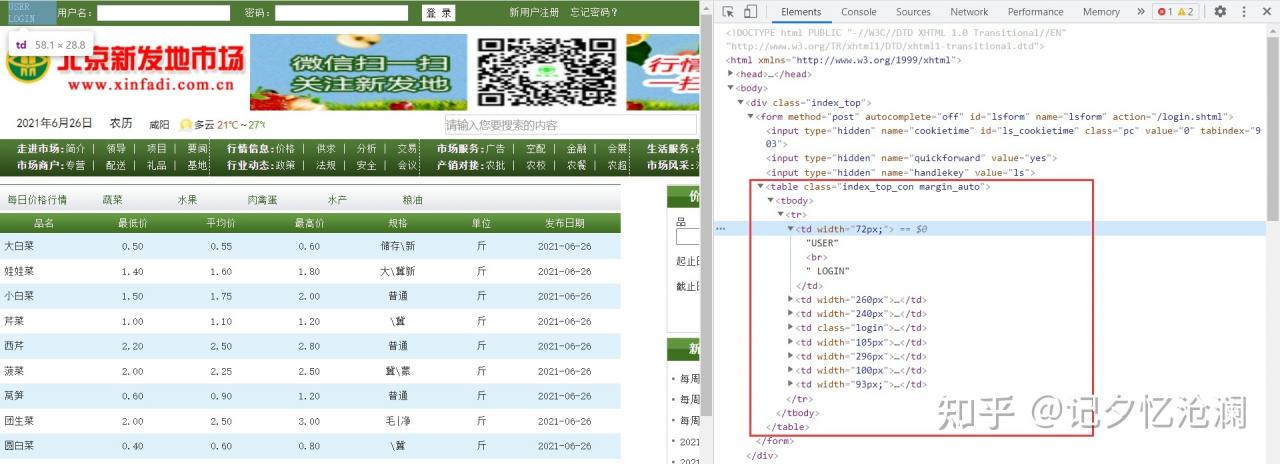
在网页空白处鼠标右键选择检查,打开开发者工具并选中Network,刷新网页,然后找到第0个请求1.shtml,Preview预览:
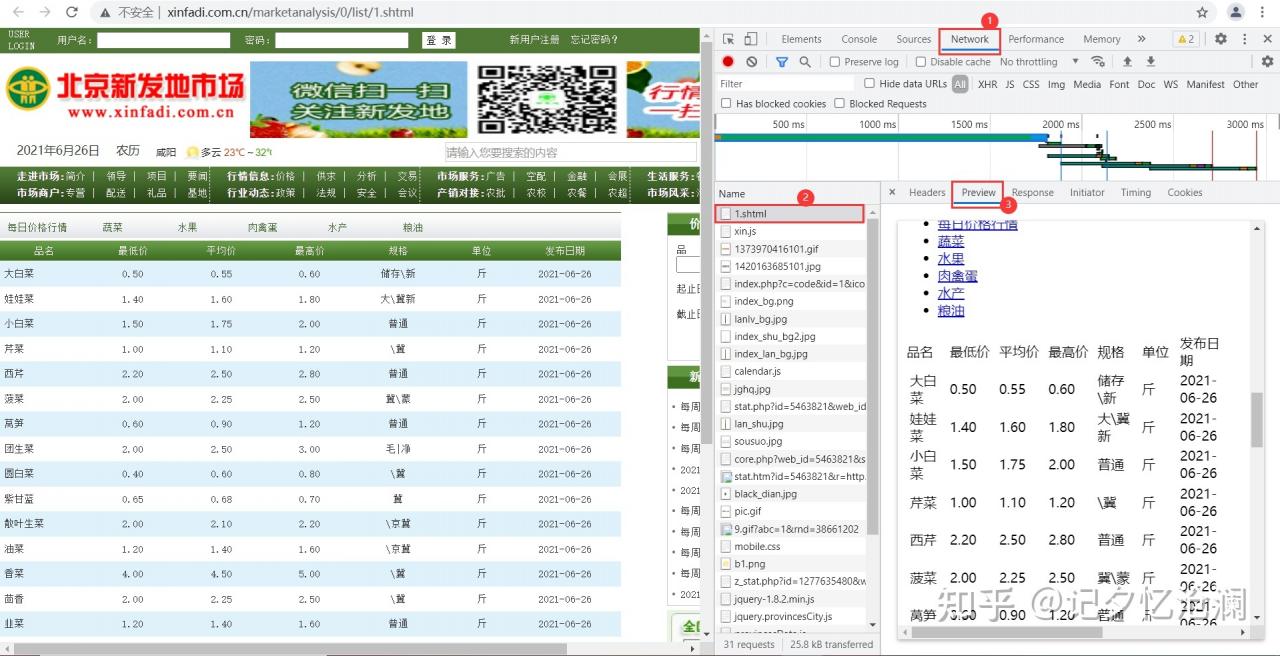
我们明显发现,待抓取的数据就在网页源代码,属于典型的静态页面爬虫。
接下来可以去分析页面结构了,看看待抓取的数据都在哪儿?
找到页面上的品名 ,然后鼠标右键选择检查,快速定位到如下标签:
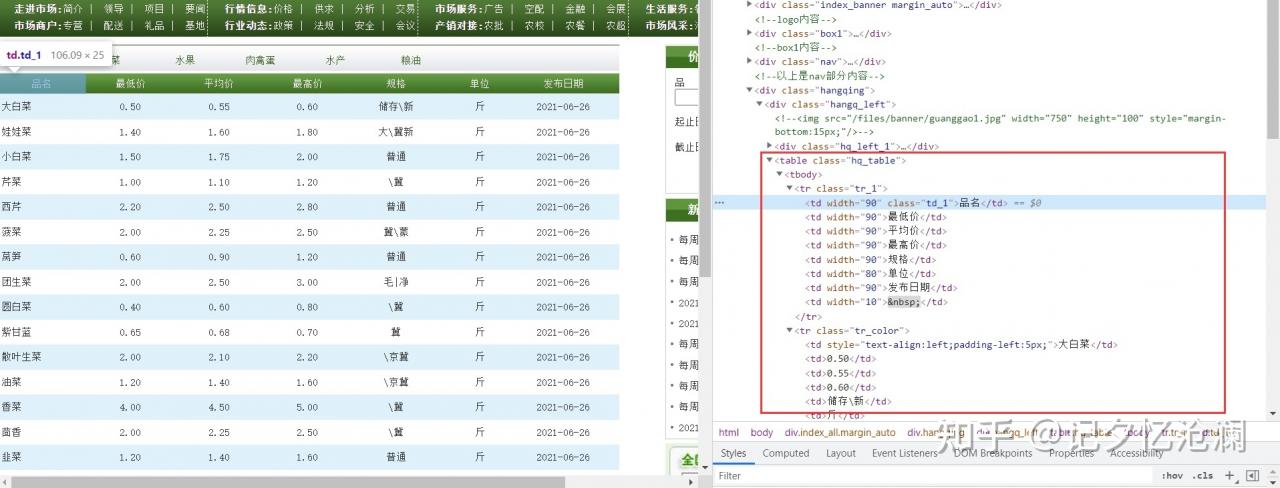
待抓取的数据就在<table class="hq_table">下的tbody下的每一个tr标签。
这种结构层次非常清晰,方便我们提取数据。但是你别忘了这不过是第一页,我们接下来就看看其它页的url。
鼠标往下滑动,找到下一页,然后鼠标右键选择检查:
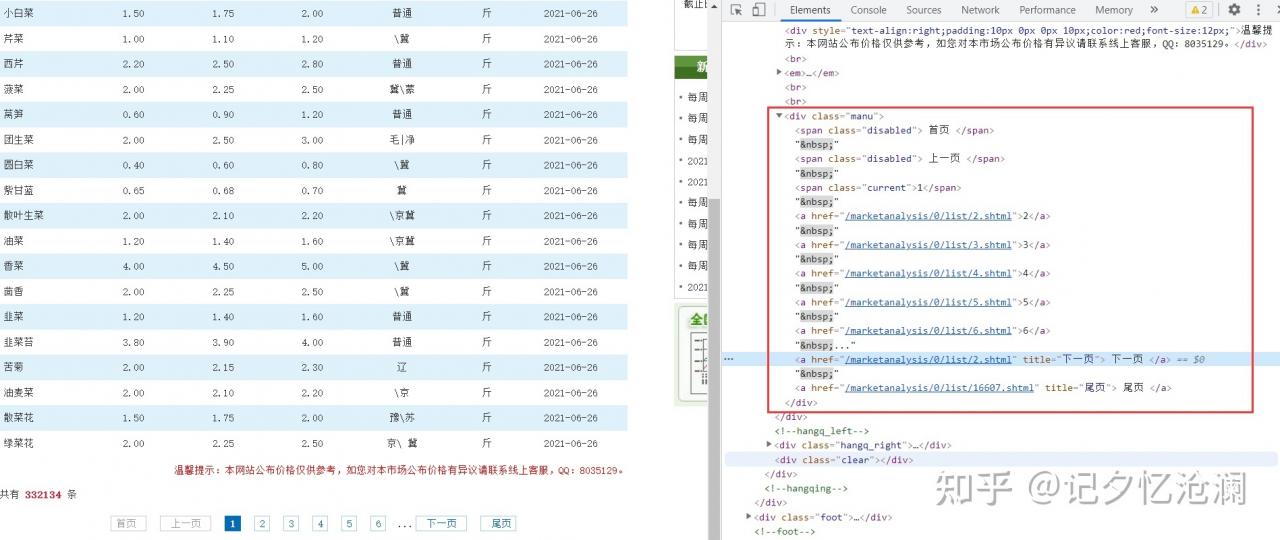
每一页的url都在此列出来了,规律也很好找,所以怎么翻页不用我说了吧,另外获悉总共有16607页需要抓取。
分析到这儿基本上就差不多了,下面就开始撸代码了。
代码实现
import csv
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
def get_html(url):
"""
获取网页源代码
:param url: URL
:return: str
"""
headers = {'User-Agent': UserAgent().random}
response = requests.get(url, headers=headers)
return response.text
def parse_html(html):
"""
解析网页源码并提取数据
:param html: Page_Source
:return: generator
"""
soup = BeautifulSoup(html, 'html.parser')
trs = soup.find(class_='hq_table').find_all('tr')
for tr in trs[1:]:
tds = tr.find_all('td')
info = []
for td in tds[:-1]:
info.append(td.text)
yield info
def write2csv(filename, rows):
"""
保存数据到csv文件
:param filename:
:param rows:
:return:
"""
with open(filename, 'a+', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerows(rows)
def main():
"""
入口函数
:return:
"""
filename = './每日价格行情.csv'
headers = ['品名', '最低价', '平均价', '最高价', '规格', '单位', '发布日期']
with open(filename, 'w', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(headers)
url = 'http://www.xinfadi.com.cn/marketanalysis/0/list/{}.shtml'
for pageNo in range(1, 16607):
info_list = []
page_source = get_html(url.format(pageNo))
for info in parse_html(page_source):
info_list.append(info)
write2csv(filename, info_list)
if __name__ == '__main__':
main()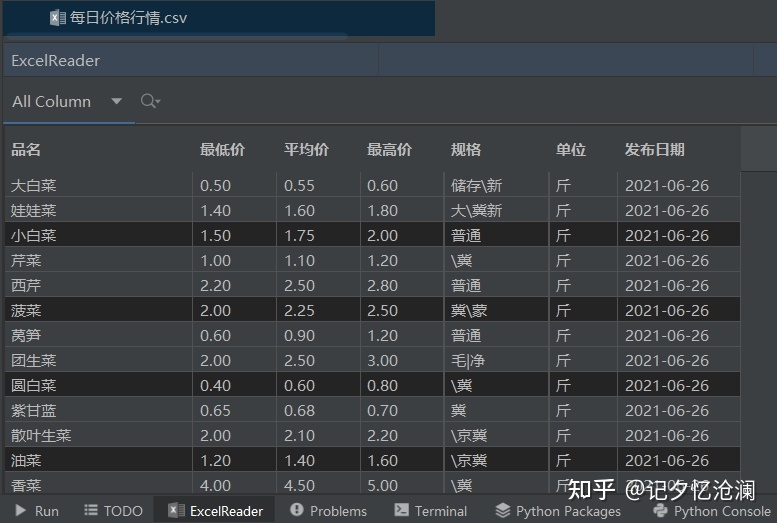
如果使用PyCharmIDE,那么我推荐你安装ExcelReader插件以便阅览csv或excel数据:
只是这样就满足了吗?
接下来扩展一点儿知识:利用pandas模块里的read_html方法快速抓取网页中的表格数据。
从上面的例子可以看到table类型的表格网页结构大致如下:
<table class="..." id="...">
<tbody>
<tr>
<td>...</td>
...
<td>...</td>
</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
...
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
</tbody>
</table>简单解释一下这几种标签的含义:
<table> : 定义表格
<tbody> : 定义表格的主体
<tr> : 定义表格的行
<td> : 定义表格单元这样的表格数据,就可以利用pandas模块里的read_html方法方便快捷地抓取下来。下面我们就来操作一下。
快速抓取
以本案例网页中的表格为例,感受一下pd.read_html()的强大之处吧。
import pandas as pd
for i in range(1, 16607): # 爬取全部16607页数据
url = f'http://www.xinfadi.com.cn/marketanalysis/0/list/{i}.shtml'
df = pd.read_html(url, encoding='utf-8', header=0)[1] # 发现所需表格是网页中的第2个
df.drop(columns='Unnamed: 7', inplace=True) # 每一行末尾都是空数据,删除最后一列
df.to_csv('每日价格行情.csv', mode='a', encoding='utf-8', index=False)
print(f'第{i}页抓取完成')需要注意的是,本案例网页中的表格有2个,但第1个不是我们要的,这一点儿很关键。
只需不到十行代码就可以将全部16607页的每日价格详情信息干净整齐地抓取下来。比采用正则表达式、bs4、xpath这类常规方法要省心省力地多。如果采取人工一页页地复制粘贴到Excel中,就得操作到猴年马月去了。
以上满满的芝士巧克力,原创不易,喜欢的最后帮忙点个赞,谢谢!