import requests
from bs4 import BeautifulSoup
class Spider():
"""爬虫类目录"""
# 1.def __init__=初始化请求网页,可输入请求地址
# 2.def print_html=打印请求的网页HTMl代码
# 3.def webcollector=采集网页代码保存到本地
# 4.def find=寻找特定网页内容并打印输出
def __init__(self, url_input='https://boards.4channel.org/w/'):
"""1.爬虫请求get网页"""
print('--爬虫启动--')
print('....')
print('请求网页=',url_input)
self.url=url_input
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44'}
self.response = requests.get(url=self.url, headers=self.headers)
def print_html(self):
"""2.打印网页代码"""
print(self.response.text)
print('-'*50)
print(self.url,'HTML RESULT')
def webcollector(self):
"""3.采集网页代码保存到本地"""
print('采集网页=', self.url)
fileName = self.url.split('.')[1] + '采集结果' + '.html'
with open(fileName, 'w', encoding='utf-8') as fp:
fp.write(self.response.text)
print('-' * 50)
print('网页采集成功!查看本目录')
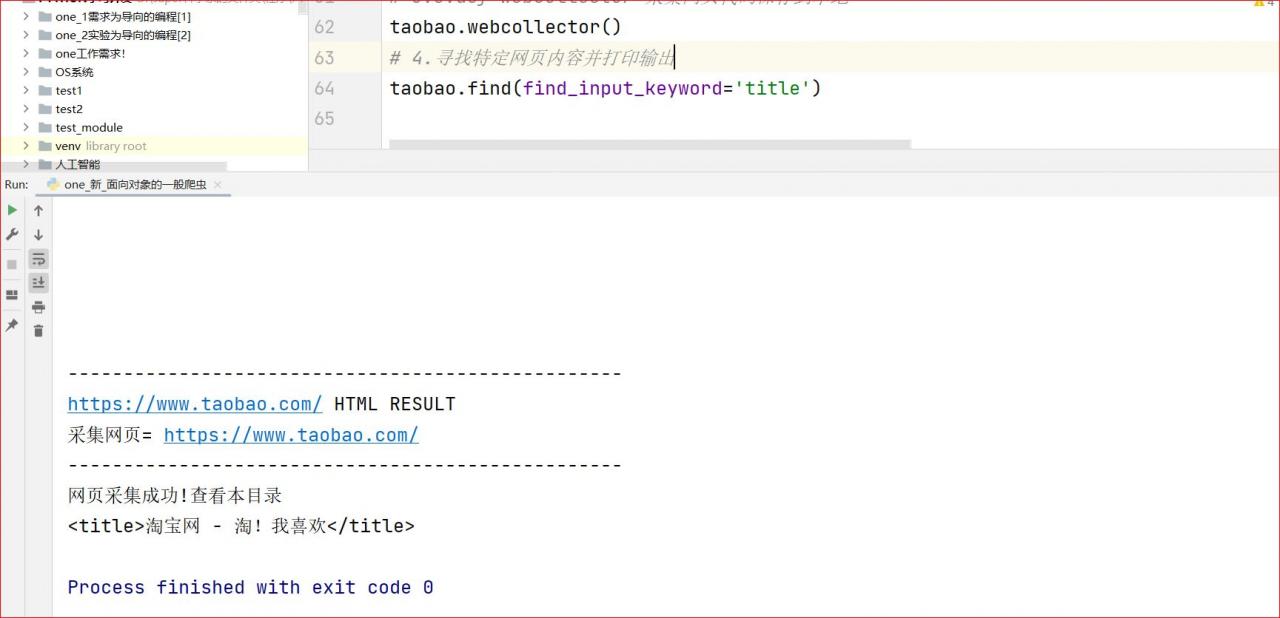
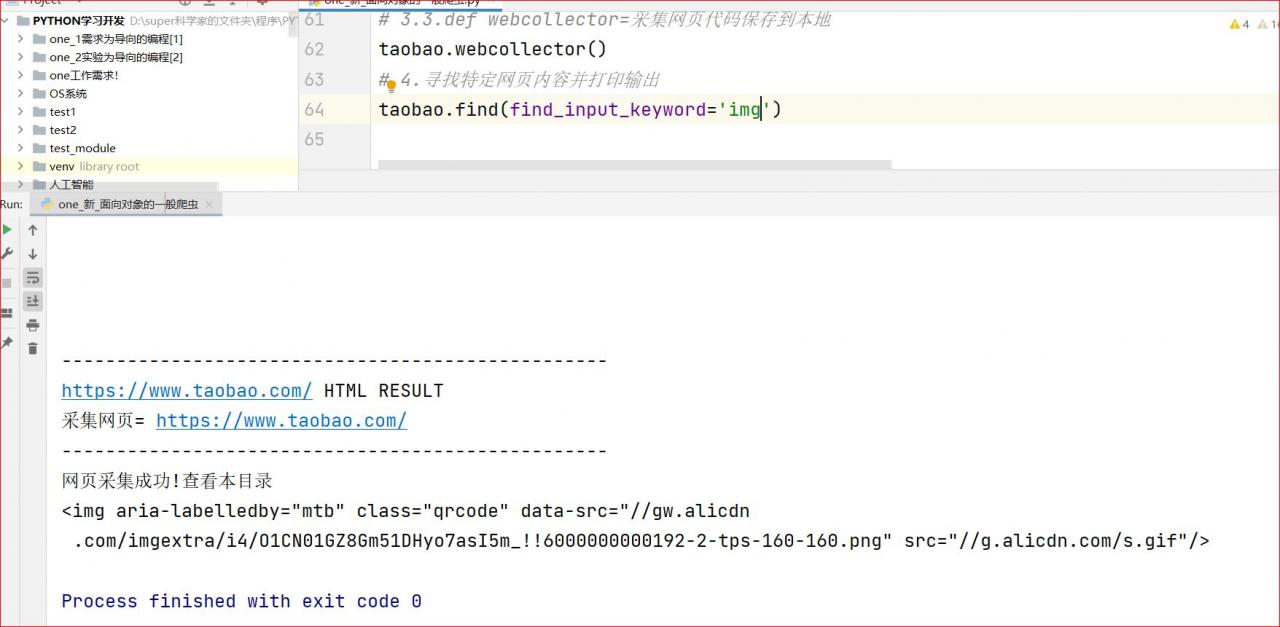
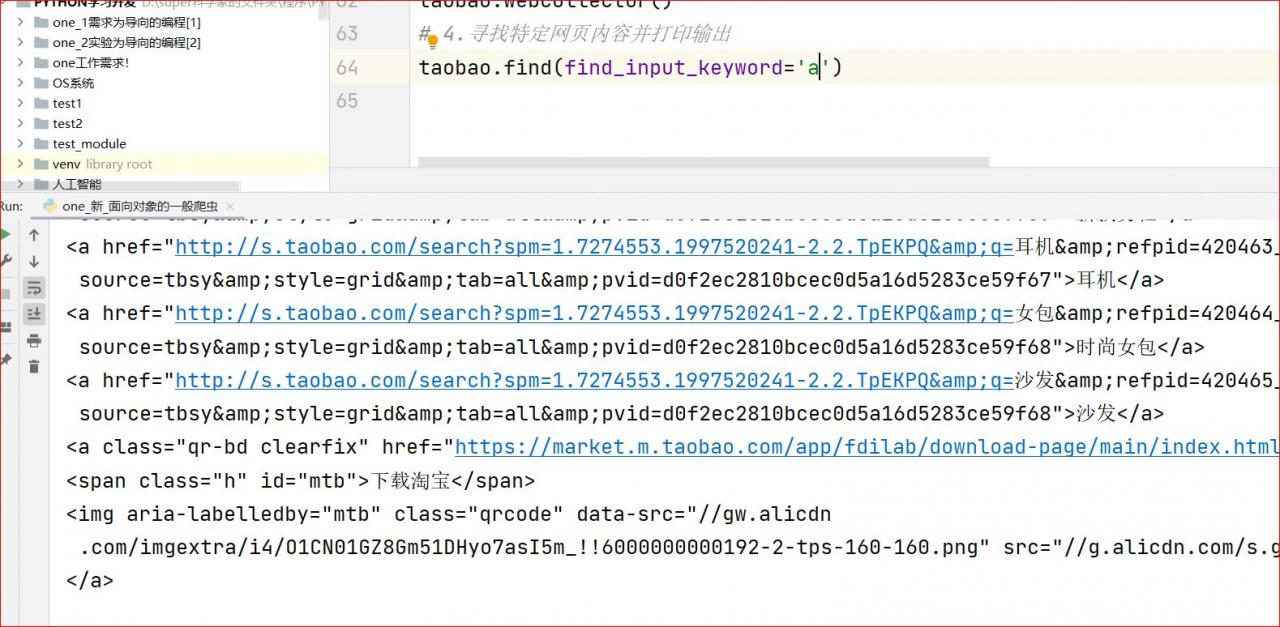
def find(self,find_input_keyword='title'):
"""4.寻找特定网页内容并打印输出"""
# find_input_keyword参数说明=
# 'title=寻找<title></title>的内容'
# 'a'=寻找<a></a>标签中的内容
# 'img'=寻找<img>标签中的内容
# 'p'=寻找<p></p>标签内容
soup = BeautifulSoup(self.response.content,'lxml')
self.find_all = soup.find_all(find_input_keyword)
for elements in self.find_all:
print(elements)
# 1.def __init__=初始化请求网页,可输入请求地址
taobao=Spider(url_input='https://www.taobao.com/')
# 2.def print_html=打印请求的网页HTMl代码
taobao.print_html()
# 3.3.def webcollector=采集网页代码保存到本地
taobao.webcollector()
# 4.寻找特定网页内容并打印输出
taobao.find(find_input_keyword='title')