如何使用mac book air部署deepseek r1(亲测好用)
作者:王思睿
链接:https://zhuanlan.zhihu.com/p/20803691410
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




链接:https://zhuanlan.zhihu.com/p/20803691410
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、准备硬件设备
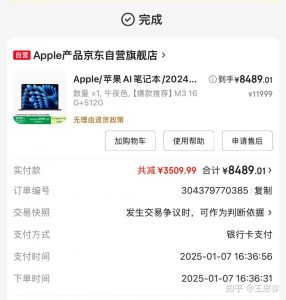
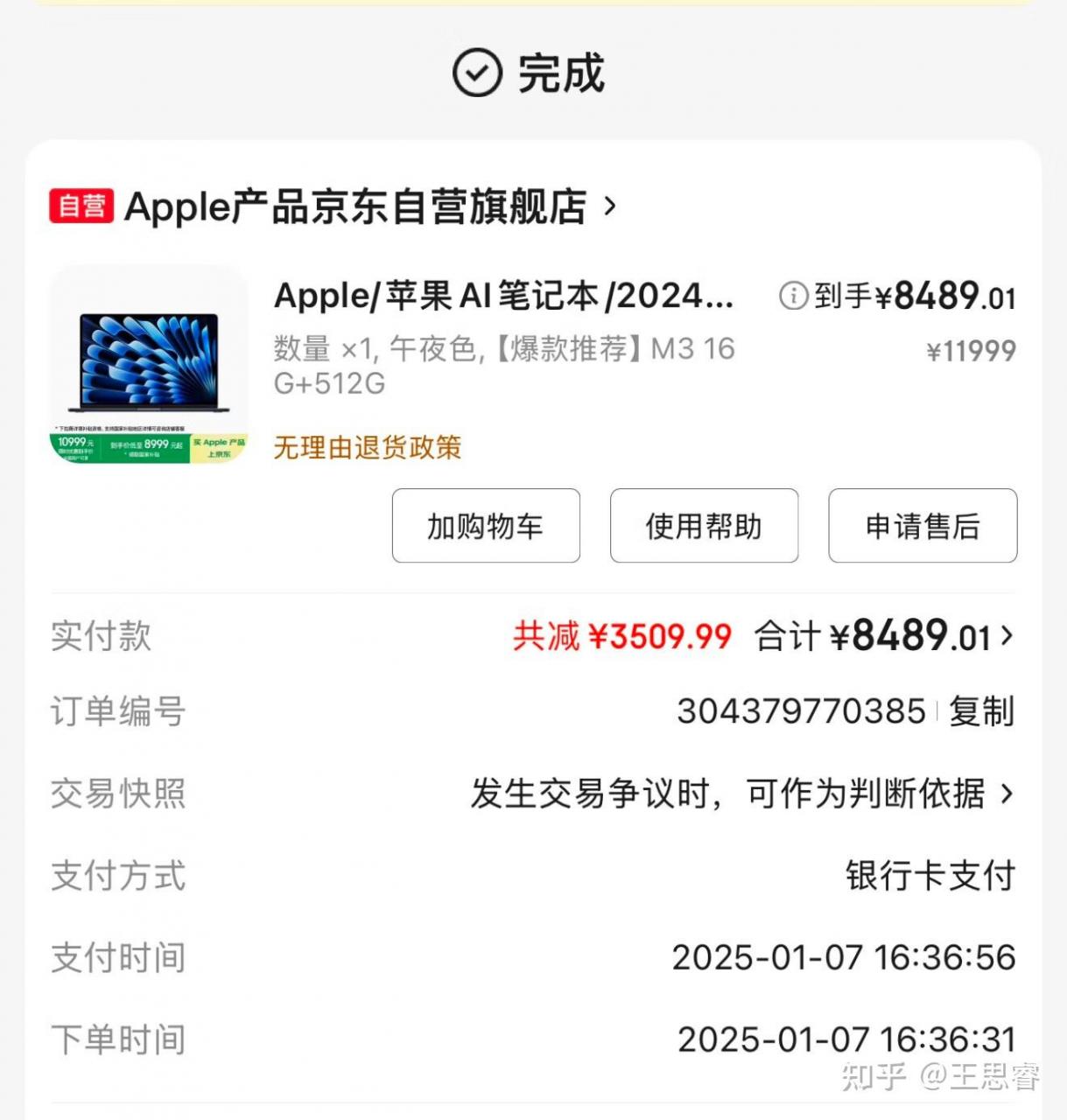
25年初使用了国补,在京东上购买的一台mac book air,内存16G,满10000减2000,感觉很合适。
只是当时还不知道deepseek,目前看只能部署b7模型,早知道就该买mac book pro了。
接下来进入本地部署deepseek大模型环节。
2、安装 Ollama
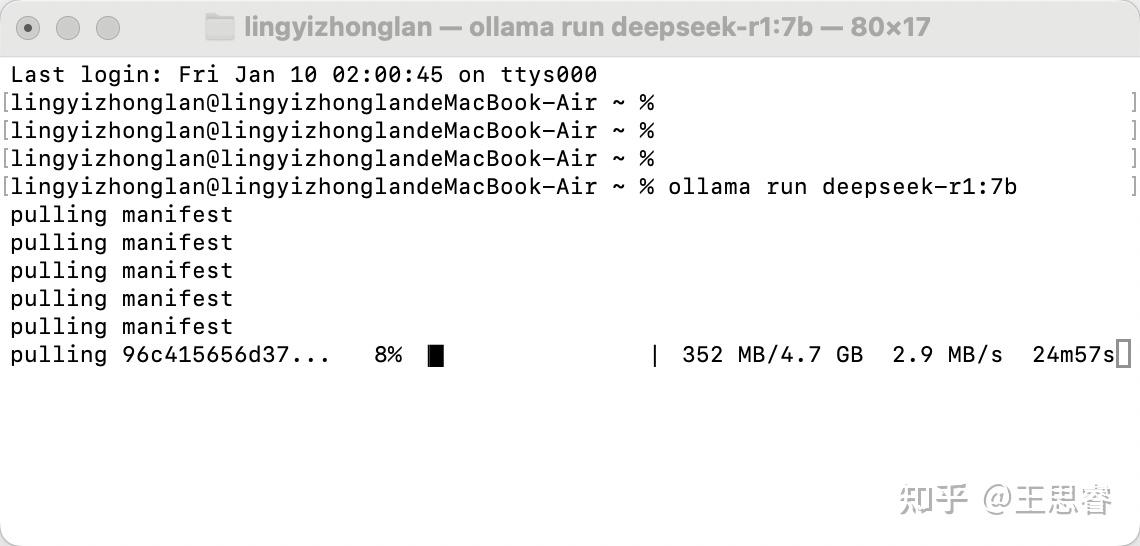
可以选择官网安装“小神兽”,下载之后,正常安装,非常快。

安装成功的效果:
也可以选择命令行安装。
curl -fsSL https://ollama.com/install.sh | sh3、选择合适的模型
M1 MacBook Air:
- 8GB 内存:
- 推荐: Deepseek-Coder-6.7B-Base-Q4_K_M
- 命令:
ollama run deepseek-coder:6.7b-base-q4_K_M - 原因: 内存占用最小,基本功能完整
- 16GB 内存:
- 推荐: Deepseek-7B-Base-Q4_K_M
- 命令:
ollama run deepseek:7b-base-q4_K_M - 原因: 性能与内存占用平衡最佳
M2 MacBook Air:
- 8GB 内存:
- 与 M1 8GB 推荐相同
- 可以适当提高 gpu_layers 参数至 35
- 16GB 内存:
- 推荐: Deepseek-7B-Chat-Q4_K_M
- 命令:
ollama run deepseek:7b-chat-q4_K_M - 原因: 神经引擎性能更好,可以处理更复杂的对话
- 24GB 内存:
- 推荐: Deepseek-8B-Chat-Q3_K_M
- 命令:
ollama run deepseek:8b-chat-q3_K_M - 原因: 可以使用更低量化等级,提升输出质量
M3 MacBook Air:
- 8GB 内存:
- 与 M2 8GB 推荐相同
- 性能会更好一些
- 16GB 内存:
- 推荐: Deepseek-7B-Chat-Q3_K_M
- 命令:
ollama run deepseek:7b-chat-q3_K_M - 原因: 可以使用更低量化等级,获得更好的输出质量
- 24GB 内存:
- 推荐: Deepseek-8B-Chat-Q2_K
- 命令:
ollama run deepseek:8b-chat-q2_K - 原因: 可以使用最低量化等级,获得最佳输出质量
根据自己的需要,选择了7b的基础编程版和对话增强版,适用场景非常丰富,既有编程模式也有聊天模式。
- deepseek-coder:7b-base(基础编程版)
- deepseek:7b-chat(对话增强版)
4、安装并运行模型
安装命令
ollama run deepseek-r1:7b安装完成,直接进入交互模式:
5、优化性能
1、创建或编辑配置文件:
nano ~/.ollama/config2、添加配置信息(~/.ollama/config):
{
"gpu_layers": 35, // GPU层数,根据显卡性能调整
"cpu_threads": 6, // CPU线程数,建议设为CPU核心数
"batch_size": 512, // 批处理大小,影响内存使用
"context_size": 4096 // 上下文窗口大小,影响对话长度
}3、重启ollama服务生效
ollama stop
ollama start
ollama run deepseek-r1:7b4、性能调优建议:
- 如果电脑发烫/卡顿:减小 gpu_layers 和 batch_size
- 如果内存不足:减小 batch_size
- 如果需要更长对话:增加 context_size(会消耗更多内存)
- cpu_threads 建议设置为实际CPU核心数-2
5、性能参考
- 内存占用:~12-14GB
- 首次加载:30-60秒
- 对话延迟:1-3秒
- 上下文窗口:4096 tokens
6、验证优化生效
1、在模型对话界面输入一个较长的问题
请给我详细解释一下量子计算的基本原理,要求回答内容超过500字2、查看CPU和内存使用
top3、检查是否生效的判断标准:
- GPU使用率应该显著(如果有独立显卡)
- CPU线程数应该是配置的6个
- 长文本响应时不会出现内存溢出
- 对话上下文能保持4096个token左右
7、前端部署(docker版WebUI环境)
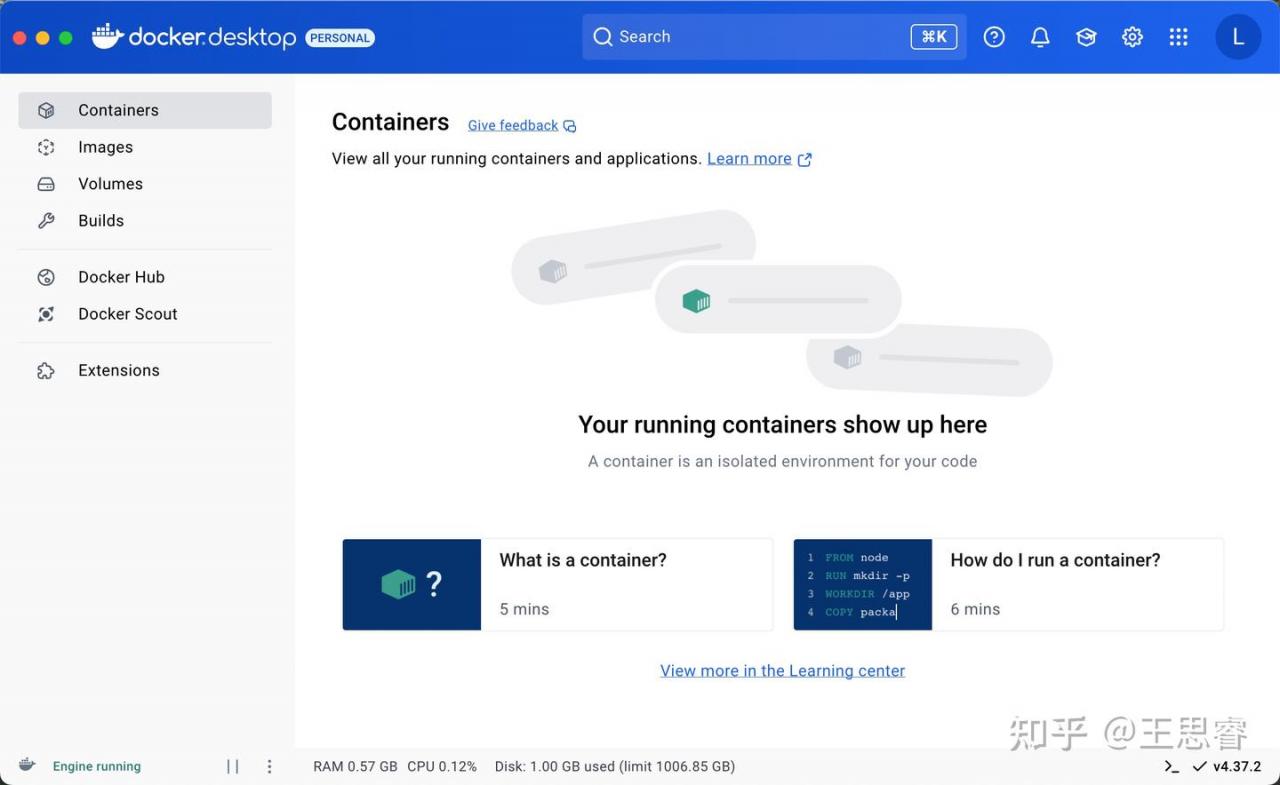
1、下载并安装docker:https://www.docker.com/
2、验证安装成功
3、运行web ui环境
1、docker run
docker run -d --name webui -p 3001:8080 \
-e OPENAI_API_BASE=http://localhost:8000/v1 \
-e OPENAI_API_KEY=none \
ghcr.io/open-webui/open-webui:main2、访问:http://localhost:3001/auth
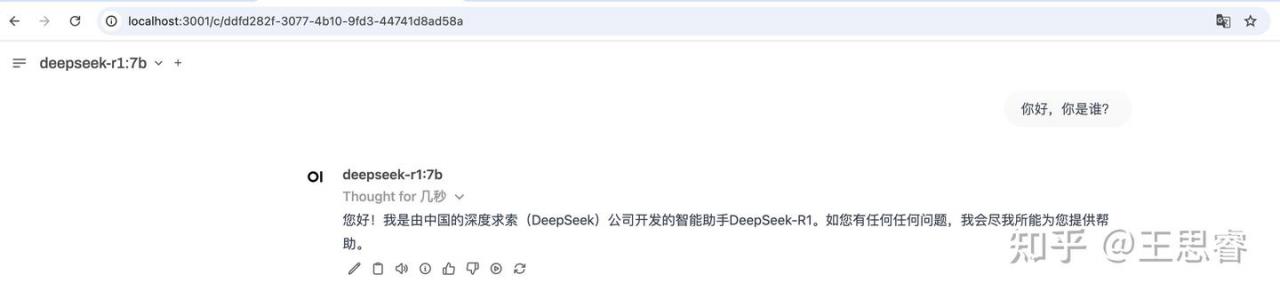
8、效果展示
9、对话速度慢如何调整
--cpu-threads 8 # 增加 CPU 线程数
--context-length 2048 # 减小上下文长度
--gpu-layers 35 # 调整 GPU 层数(如果有 GPU)个人感觉速度还可以。