目前有什么可以本地部署的大模型推荐?
链接:https://www.zhihu.com/question/648879790/answer/90557867040
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1. Ollama介绍
Ollama是一个开源的本地大语言模型运行框架,旨在简化大型语言模型(LLM)的本地部署和运行,官网https://ollama.com/。Ollama的安装非常简单,官网下载即可。Ollama 提供了一系列常用的命令和操作,方便用户进行模型管理和推理,以下是常用的模型管理命令和模型运行命令:
(1)模型管理命令
查看已安装的模型:ollama list
拉取模型:ollama pull model_name
删除模型:ollama rm model_name
复制模型:ollama cp original_model new_model
查看模型信息:ollama show model_name
(2)模型运行命令
启动 Ollama:ollama serve
运行模型:ollama run model_name
停止模型:ollama stop model_name
查看当前运行的模型:ollama ps
2. 小试牛刀:Llama大模型
Llama 3.2 是由 Meta(原 Facebook)推出的一款开源生成式 AI 模型,是 Llama 系列的最新版本之一。该模型系列包括多种参数规模的模型,从适用于边缘设备的轻量级纯文本模型到能够执行复杂推理任务的中型视觉语言模型(Visual LLM)。
目前,Llama 3.2 包括 1B、3B、11B 和 90B 参数规模的模型。相应的,1B 和 3B 模型适用于边缘和移动设备,而 11B 和 90B 模型则适用于更复杂的视觉和语言任务。
在ollama部署Llama 3.2非常简单,只需运行命令ollama run llama3.2。第一次运行的话,由于模型还未被拉取到本地,因此会先执行拉取命令。可以看到,当下载完毕后,显示success,即模型已经部署完毕。
需要注意的是,ollama 模型下载到后期速度变慢,这时候只需点击选中终端窗口,然后点击 ctr+c 暂停下载,然后再次执行命令
ollama run llama3.2即可。
在部署完毕后,我们现在开始玩一玩这模型。不过在开始之前,我们得知道Llama 3.2的能力边界。Llama 3.2支持文本生成、多模态处理(比如图像理解),还有一定的推理能力。首先执行ollama show llama3.2,看看Llama 3.2的参数:
C:\\Users\\Jiajian>ollama show llama3.2
Model
architecture llama
parameters 3.2B
context length 131072
embedding length 3072
quantization Q4_K_M
Parameters
stop "<|start_header_id|>"
stop "<|end_header_id|>"
stop "<|eot_id|>"
License
LLAMA 3.2 COMMUNITY LICENSE AGREEMENT
Llama 3.2 Version Release Date: September 25, 2024在对Llama 3.2有了初步了解后,就让我们用简单聊天来开启这次与人工智能的交互之旅。再次运行ollama run llama3.2。
与Llama 3.2的交互记录。
可以看到,当我每次用大模型进行推理的时候,电脑GPU占用率会显著提高。
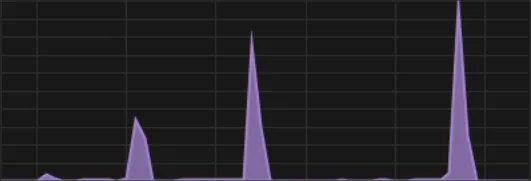
3. DeepSeek本地化部署
DeepSeek-R1 系列和 DeepSeek-V3 系列是 DeepSeek 推出的两款大模型。
- DeepSeek-V3:定位为通用型大语言模型,专注于自然语言处理(NLP)、知识问答和内容生成等任务。其优势在于高效的多模态处理能力(文本、图像、音频、视频)和较低的训练成本。采用传统的预训练-监督微调范式,结合混合专家架构(6710 亿参数,每次激活 370 亿),通过算法优化降低算力需求。其创新点包括负载均衡和多令牌预测技术,训练成本仅为同类闭源模型的 1/20。
- DeepSeek-R1:专为复杂推理任务设计,强化在数学、代码生成和逻辑推理领域的性能。通过大规模强化学习(RL)和冷启动技术,R1 在无需大量监督微调(SFT)的情况下,实现了与 OpenAI o1 系列相当的推理能力。完全摒弃了监督微调(SFT),直接通过强化学习(RL)从基础模型中激发推理能力。其核心技术包括 GRPO 算法、两阶段 RL 与冷启动、自我进化能力等。不仅开源模型权重(MIT 协议),还提供了基于 Qwen 和 Llama 的蒸馏版本**(1.5B 至 70B)**,显著提升小模型性能。例如,蒸馏后的 32B 模型在 MATH-500 中得分 94.3%,超越原版 Qwen2.5-32B(72.6%)。
3.1 DeepSeek-R1 系列
- 满血版:DeepSeek-R1 满血版参数量为 671B,理论上需要 350G 以上显存/内存才能部署 FP4 的量化版本。对绝大多数家用电脑来说,部署难度较大,需要专业服务器支持。
- 蒸馏版:DeepSeek-R1 蒸馏版模型大小从 1.5B 到 70B 不等,适合在普通家用电脑上部署。常见的蒸馏版模型包括 1.5B、7B、8B、14B、32B 和 70B 等。
- 1.5B:适合显存较低的设备,如集显或显存较小的显卡。
- 7B/8B:适合显存适中的设备,如 8G 显存的显卡。
- 14B/32B/70B:适合显存较大的设备,如 24G 或更高显存的显卡。
这里笔者选择32B的版本,并成功部署,最后执行命令ollama run deepseek-r1:32b

3.2 DeepSeek-V3 系列
- 本地部署版本:DeepSeek-V3 支持在本地运行,使用 DeepSeek-Infer Demo 部署,支持 FP8 和 BF16 推理。部署时需要 NVIDIA GPU(推荐 A100 或 H100)或 AMD GPU,以及充足的系统内存(推荐 32GB 以上)。
- 云端集成版本:通过 SGLang 和 LMDeploy 支持在云平台上部署,提供企业级部署方案,支持离线管道处理和在线服务部署。
- 硬件支持版本:兼容 NVIDIA、AMD GPU 和华为昇腾 NPU,支持多种部署框架,包括 SGLang、LMDeploy、TensorRT-LLM、vLLM 等。
4. 量化模型
在大模型领域,量化模型(Quantized Model) 是指通过降低模型中参数的数值精度(例如从32位浮点数转换为8位整数),从而减少模型的计算量、存储空间和能耗,同时尽量保持模型性能(如准确率)的技术方案。量化是模型压缩和优化的重要手段,尤其适用于在资源受限的设备(如手机、边缘设备)上部署大模型。