初学者如何对大模型进行微调?
大模型无疑是AI领域这两年最靓的仔,无论是陪人聊天吹牛,还是被科学家用于各种AI4Science研究;无论是生成一些手指数目不对的涩图,还是被用于生成公司logo、电影海报,总之,每一次“事关”大模型的新闻,总会引起大家的广泛关注和讨论。这其中,在已有大模型的基础上,针对某一领域或用途进行微调,使其在特定任务上具有更为出色的表现,无疑是当前大模型商业化应用的重要方向。
虽然大家对于“微调”这个词本身可能并不陌生,也已经有海量的研究论文、无数的复杂公式和令人眼花缭乱的技术术语来描述“微调”这件事,但是对于很多初学者或者从未接触过大模型微调的人来说,想要进入这个领域可能并不容易。
完全本地化的大模型微调,通常需要强大的计算资源和专业的开发环境,对于普通人来说是一个不小的障碍,毕竟现在算力可是价值不菲的好东西。
我觉得从Hugging Face的Transformers库入手学习大模型微调,或许是一个不错的选择。
Github上有Hugging Face’s Transformers的仓库,里面有代码和详细的说明。
把代码拖到本地后,我们可以开始尝试“体验”大模型微调。
比如我想选择基本的Bert模型进行微调,先导入必要的库:

需要导入用于处理和训练模型的基本库,包括PyTorch、transformers库中的BERT分词器和预训练模型,以及用于加载和处理数据集的datasets库。之所以顺便导入了datasets库,是因为我手头并没有合适的经过清洗、可以用于微调的数据集,所以决定偷个懒,直接使用由Hugging Face提供的“datasets”库。
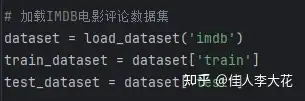
这个数据集中包括文本分类、问答、翻译等各种各样的数据,我选择了其中的“IMDB电影评论数据集”用于模型微调。
这个分类数据集主要用来区分观众对于电影的评价是“正面的”还是“负面的”,定义我们微调中会用到的训练和测试数据:
接下来就是加载分词器和模型,这里选择使用未经大小写转换的版本“bert-base-uncased”,分别使用transformers库中的BertTokenizer和BertForSequenceClassification函数,加载预训练的BERT分词器以及BERT模型:

在加载完分词器和模型后,我们需要对数据集进行预处理,将文本转换为模型可以接受的输入格式。
这里我们定义了一个名为tokenize_function的函数,用于对数据集中的文本进行分词和编码:

这个函数使用了之前加载的BERT分词器对文本进行分词,同时进行了一些必要的处理,如填充(padding)、截断(truncation)和设置最大长度(max_length)等。其中需要注意的是,IMDB数据集中的文本字段名为’text’。
接下来,我们使用datasets库提供的map函数,将tokenize_function应用于整个数据集,并通过设置batched=True以批量方式来处理数据,加速处理过程:

为了加快训练和测试的速度,我们可以从数据集中选取一部分样本作为训练集和测试集用于微调。
使用shuffle函数对数据集进行随机打乱,通过select函数选择训练数据集中的前1000个样本进行微调训练,测试数据集中的前400个样本进行微调测试。
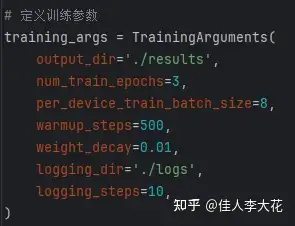
在正式开始微调之前,需要定义一些训练参数。
在我设计的这个案例里,使用了transformers库提供的TrainingArguments类,分别设置了输出目录、训练轮数(epoch)、批次大小(batch size)、学习率预热步数(warmup_steps)、权重衰减系数(weight_decay)以及日志输出的相关参数:
好了,现在万事俱备,只欠“训练”。
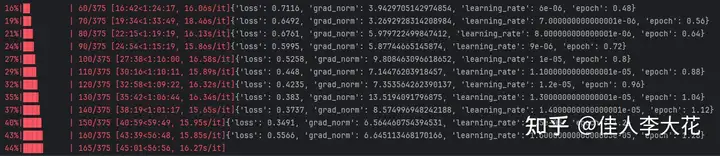
初始化Trainer,将之前准备好的模型、训练参数、训练集、测试集以及分词器全部塞进Trainer里,然后调用train方法开始微调模型、评估模型,并保存微调后的模型:

接下来就是漫长的等待时间,根据微调使用的设备(GPU或CPU)不同,数据集大小不同,选择的预训练模型不同,超参数设置不同,训练耗时也是天差地别。不过因为我选择的数据集相对简单,所以即使是用CPU进行微调,速度也还算可以接受。
等到模型训练完毕,那个“trained_model”就是我们想要的目标微调模型。
相信看到这里,大家也就明白了,微调模型的性能其实完全取决于那个pre-trained的通用模型,也就是我们耳熟能详的“大模型”。
不同大模型的面向对象、训练目标、预训练效果各有不同,只有事先了解各种大模型,“知己知彼”,才能实现精准选择。我建议可以学习「知乎知学堂旗下的AGI课堂」推出的【程序员的AI大模型进阶之旅】公开课,邀请了很多圈内的大佬,用2天的免费课程,帮助我们快速了解各种大模型的基本架构、训练目标、擅长领域等等,无论是直接用于推理,还是后续进行微调,都可以帮助我们节省很多选择时间,迅速锁定最符合需求的pre-trained大模型。现在直播免费领,很快就没有了,先来占个位置不吃亏~
对各种大模型做到“心中有数”后,就可以上手进行微调,试用自己的微调模型进行推理时,还是挺美滋滋的。
比如我的“IMDB电影评论模型”微调完成后,就可以使用训练好的模型对新的文本进行预测了。
加载之前微调好的模型,使用BertTokenizer和BertForSequenceClassification的from_pretrained方法,分别加载预训练的分词器和我们自己微调好的模型:

这里与微调过程不同的是,我们不再使用通用的pre-trained模型,而是从’./trained_model’路径加载我们刚才微调好的模型。
接下来,定义一个名为predict的函数,用于对新的文本进行预测:
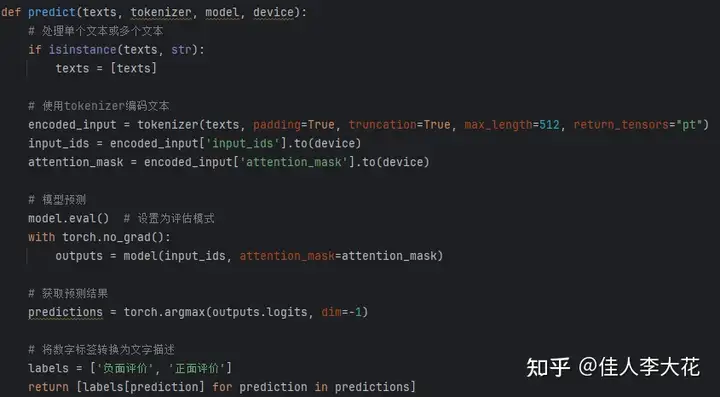
这个函数共需四个参数:texts(需要预测的文本)、tokenizer(分词器)、model(微调好的模型)以及device(GPU或CPU)。
函数内部首先判断读入的texts是单个文本还是文本列表。如果是单个文本,则将其转换为列表。
然后,使用分词器对文本进行编码,将其转换为模型可接受的输入格式。这里使用了padding、truncation和max_length等参数,用于确保输入的一致性。
接着将模型设置为评估模式(eval),并使用torch.no_grad()上下文管理器来禁用梯度计算,减少内存占用的同时加速推理过程。
最后,将编码后的输入传递给模型,获取预测结果。为了看起来更直观,我把预测结果从数字标签转换为对应的文字描述(“负面评价”或“正面评价”),并返回结果列表。
我简单设计了几个“测试样本”,也就是随便写的几个关于电影的评价,让微调模型给出这些评价的情感倾向:
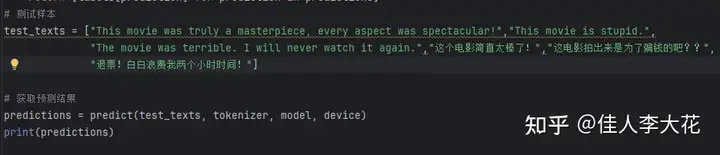
调用predict函数,传入测试文本、分词器、模型以及设备,打印出预测结果:

根据我自己随便写的测试可以发现,由于微调使用的数据集,其中绝大多数数据是英文,所以微调模型对于英文评价的分类非常准确,但是对于中文评价的判断并不准确,这也正说明数据集的质量对于微调模型的性能有着非常显著的影响。
通过这个简单的例子,我们可以看到,借助Hugging Face的Transformers库,即使是没有机器学习背景的初学者,也能够在较短的时间内学会如何对大模型进行微调,并将微调后的模型应用于实际的自然语言处理任务中。
只是模型微调的效果很大程度上取决于预训练模型的质量和与任务的相关性,以及微调所使用数据集的质量和规模。
想要真正把微调模型应用于自己的工作时,要根据具体的任务需求,选择最合适的预训练大模型,并尽量收集高质量的预训练数据集,进行耐心的数据清洗,并不断尝试各种参数组合,反复优化,才能获取高性能的微调模型。
不过,初学者想要入门其实并不困难,按照我的步骤自己试一试呗,有个CPU就能出结果。微调这玩意,多学、多试、多思考,一定可以收获一个好玩又有用的,而且属于自己的模型~听我的,现在就动手,玩儿起来吧!