【纯干货】低配机器也能微调大模型?手把手教你实战技巧!
废话不多说,本文就一个目的:让普通的消费级电脑实现微调大模型的全过程。
让所有爱好AI的玩家过把瘾!!!不用流着口水眼看着别人在高配GPU服务器上微调大模型,你也行!
200行代码,让你轻松玩转大模型微调!
让我们直奔主题!
1、现实意义与实现路径
现实意义:我现在教你的是如何在消费级个人PC上实现完整的大模型微调过程,掌握了此方法,你也就掌握了训练其他大模型的标准方法,彻底撕开大模型微调的神秘面纱。
实现路径:使用较小参数量的模型+较小数据集进行完整过程模拟。
2、主题干货:200行微调代码全解析
2.1 基础模型选择与数据集选择:
| 目标选择 | 名称 | 说明及选择原因 |
|---|---|---|
| 模型名称 | distilbert/distilgpt2 | • Hugging Face 模型库中的 distilgpt2 • 约 82M 参数,模型权重文件大约 330MB • 是 GPT-2 的一个精简版本,通过知识蒸馏(distillation)从更大的 GPT-2 模型压缩而来。它保留了 GPT-2 的核心能力,但计算需求和内存占用显著降低,非常适合在个人电脑上微调。 |
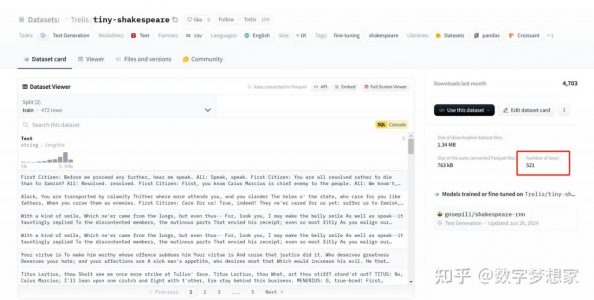
| 数据集名称 | Trelis/tiny-shakespeare | 这个数据集包含莎士比亚作品的一个小型子集,是目前已知的最小且仍然有意义的语言训练数据集之一,数据量很小,只有1.34M, 521条记录。 |
注意:本文所有模型与数据集均来自HuggingFace。
2.2 工具与环境
Anaconda的安装此处没必要说了,此处直接略过,不会的朋友直接知乎即可。
编译环境与核心依赖包:
Python: 3.9.21
torch 2.6.0+cu118
pytorch 2.3.1 (py3.9_cuda11.8_cudnn8_0)
CUDA版本:11.8
huggingface_hub 0.28.0
有独立显卡的朋友,请通过命令行(nvidia-smi)查看自己cuda的版本,并安装相应的依赖包,这一点很重要,以免出现不兼容的情况导致微调代码无法运行:
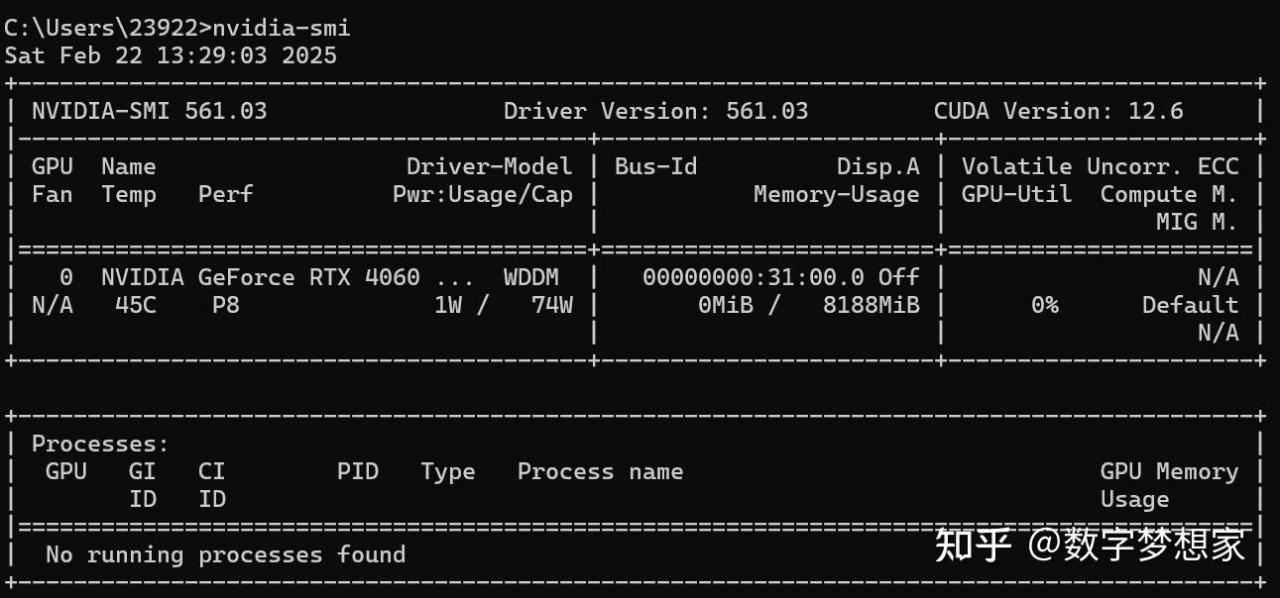
比如我机器上的cuda版本是11.8,那么就需要在conda命令行安装对应的依赖包(以下命令行只需要执行一条,选择对应的cuda版本即可):可参考官方:https://pytorch.org/get-started/previous-versions/
# CUDA 11.8
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
# CPU Only
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 cpuonly -c pytorch2.3 import
import os
import torch
from datasets import load_dataset, DatasetDict
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TrainingArguments,
DataCollatorForLanguageModeling,
TrainerCallback,
BitsAndBytesConfig, Trainer
)
from peft import LoraConfig, get_peft_model
from trl import SFTTrainer
from config.config import TARGET_MODEL, DATASET_NAME
import matplotlib.pyplot as plt2.4 配置8 bit量化与训练策略
8bit量化后,会进一步减少对设备性能的消耗。
# 配置 8 位量化
quantization_config = BitsAndBytesConfig(
load_in_8bit=True,
llm_int8_threshold=6.0,
)
# 自定义 device_map
device_map = {
"": 0 # 将模型的所有层都映射到 GPU 0
}
# 加载 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(TARGET_MODEL)
tokenizer.padding_side = 'right'
tokenizer.pad_token = tokenizer.eos_token # 添加这一行,设置 pad_token
model = AutoModelForCausalLM.from_pretrained(
TARGET_MODEL,
quantization_config=quantization_config,
device_map=device_map
)要点:
1)如果机器没有GPU,那么需要加上判断:
# 检查是否有可用的 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载模型时,指定设备
model = AutoModel.from_pretrained("bert-base-uncased")
model.to(device)2)TARGET_MODEL表示config文件中定义的数据集文件路径,后续会给出config文件代码
2.5 配置Lora
这一步很关键, 这段代码使用了 peft 库中的 LoraConfig 来配置 LoRA(Low-Rank Adaptation)技术,用于在微调大型语言模型时高效调整模型参数,它非常高效、资源占用低,是微调玩家的首选。
# 配置 LoRA
config = LoraConfig(
r=8, # LoRA 秩
lora_alpha=16,
# 只适合Llama模型
# target_modules=["q_proj", "v_proj"],
# gpt类模型的注意力权重层;q/k/v 的联合投影
target_modules=["c_attn"],
lora_dropout=0.1,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config)
2.6 加载数据集
接下去我们就直接加载数据集:DATASET_NAME也将定义在单独的config.py文件中,用来指定数据集的名称。
# 加载数据集
dataset = load_dataset(DATASET_NAME, trust_remote_code=True)
要点:trust_remote_code=True这个参数有时候非常必要,它允许 load_dataset 执行数据集仓库中提供的自定义 Python 脚本,适用于需要动态生成或复杂处理的数据集。有些数据集必须要加这个参数,否则无法加载。此处作为一个知识点,对于本例来说,其实可以直接删掉这个参数。
2.7 预处理数据集:测试集与验证集
加载数据集之后,需要将数据集进行拆分,90%作为训练集,10%作为测试或验证集,对于 distilgpt2 和 tiny_shakespeare,无需复杂的指令格式,直接使用原始文本进行训练即可。所以train_prompt_style 直接设置为空即可:
# 检查是否有验证集,若没有则手动划分
if 'validation' not in dataset:
# 这是 datasets 库中的一个方法,用于将数据集划分为训练集和测试集。
# test_size=0.1:表示将数据集的 10% 分配给测试集(test),剩下的 90% 作为训练集(train)
# shuffle = True: 表示在划分之前对数据进行随机打乱,以确保数据分布的随机性。
# 设置随机种子,确保每次运行代码时划分结果的一致性。
split_dataset = dataset["train"].train_test_split(test_size=0.1, shuffle=True, seed=42)
dataset["train"] = split_dataset ["train"]
# 将重新划分后的测试集 dataset["test"] 重命名为验证集 dataset["validation"],以便在后续代码中明确区分训练集和验证集的用途。
dataset["validation"] = split_dataset ["test"]
train_prompt_style = None # 或空字符串 "",不再使用复杂的指令模板
# 轻量级数据集只有一个text字段
class DataPreprocessor:
def __init__(self, tokenizer, prompt_template):
self.tokenizer = tokenizer
self.prompt_template = prompt_template # 保留,但 tiny_shakespeare 未直接使用
def __call__(self, examples):
texts = examples["Text"] # 直接使用 tiny_shakespeare 的 text 字段
tokenized = self.tokenizer(
texts,
padding="longest",
truncation=True,
max_length=512,
return_tensors="pt",
)
tokenized["labels"] = tokenized["input_ids"].clone()
return tokenized
# 批量预处理
preprocessor = DataPreprocessor(tokenizer, train_prompt_style)继续设置训练集和验证集的批处理参数:
# 预处理数据集
tokenized_dataset = DatasetDict()
# 对训练集进行预处理
tokenized_dataset["train"] = dataset["train"].map(
preprocessor,
batched=True,
batch_size=100,
remove_columns=dataset["train"].column_names
)
# 对验证集进行预处理
tokenized_dataset["validation"] = dataset["validation"].map(
preprocessor,
batched=True,
batch_size=10,
remove_columns=dataset["validation"].column_names
)
print(tokenized_dataset["train"][:5])
# 数据收集器 创建一个数据整理器,用于在训练 model 时处理 tokenized_dataset 中的批量数据,生成适合因果语言建模的输入和标签。
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
2.8 训练参数设置
核心配置,各参数解释见代码后附表:
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
overwrite_output_dir=True,
num_train_epochs=8,
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
per_device_eval_batch_size=8,
save_steps=400,
save_total_limit=2,
prediction_loss_only=True,
fp16=True,
bf16=False,
logging_steps=50, # 日志记录步数, 大数据集
eval_steps=200, # 评估步数
evaluation_strategy="steps",
warmup_ratio=0.1,
lr_scheduler_type="linear",
learning_rate=5e-5, # 设置学习率
load_best_model_at_end=True,
metric_for_best_model="eval_loss"
)训练参数详解:
| 参数 | 值 | 作用 | 与任务的相关性 |
|---|---|---|---|
| output_dir | “./results” | 指定保存模型和日志的目录 | 保存微调后的 distilgpt2 和检查点 |
| overwrite_output_dir | True | 覆盖已有输出目录 | 方便重复实验 |
| num_train_epochs | 8 | 训练总轮数 | 可能导致 tiny_shakespeare 过拟合,建议减少到 3–5 |
| per_device_train_batch_size | 8 | 每个设备的训练批量大小 | 适合小数据集,但需检查显存,建议减小到 4 或 2 |
| gradient_accumulation_steps | 4 | 梯度累积步数,增大等效批量大小 | 有效批量 32,可能过大,建议减少到 1 或 2 |
| per_device_eval_batch_size | 8 | 每个设备的评估批量大小 | 适合验证集,需检查显存 |
| save_steps | 400 | 每隔 400 步保存检查点 | 合理,但可调为 1,000 或按总步数比例 |
| save_total_limit | 2 | 限制保存的检查点数量,最多保留 2 个 | 节省存储空间 |
| prediction_loss_only | True | 仅计算预测损失,减少计算开销 | 适合因果语言建模,加快训练 |
| fp16 | True | 启用 FP16 混合精度训练 | 适合 GPU 训练,需硬件支持,如果没有GPU,则改为False。 |
| bf16 | False | 禁用 BF16 混合精度训练 | 适合非 BF16 硬件 |
| logging_steps | 50 | 每隔 50 步记录日志 | 较密,对于大数据集,d建议增至 100 或 500 |
| eval_steps | 200 | 每隔 200 步在验证集上评估 | 较疏,对于大数据集,建议减至 50 或 100 |
| evaluation_strategy | “steps” | 按步数触发评估 | 适合小数据集 |
| warmup_ratio | 0.1 | 学习率预热 10% 步数 | 合理,但可试 0.05 或移除 |
| lr_scheduler_type | “linear” | 学习率线性衰减 | 适合小模型,简单有效 |
| learning_rate | 5e-5 | 初始学习率 | 大数据集建议调整为 2e-5,防止过拟合 |
| load_best_model_at_end | True | 训练结束加载验证性能最佳模型 | 防止过拟合,适合小数据集 |
| metric_for_best_model | “eval_loss” | 选择最佳模型的指标为验证损失 | 适合因果语言建模 |
2.9 训练器设置
# 更新 PlotLossCallback
plot_callback = PlotLossCallback()
trainer = SFTTrainer(
model=model,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["validation"],
peft_config=config,
tokenizer=tokenizer,
args=training_args,
data_collator=data_collator,
callbacks=[plot_callback]
)
# 开始训练
trainer.train()
# 保存 LoRA 权重
model.save_pretrained("./fine_tuned_model")| 参数名称 | 类型 | 描述 |
|---|---|---|
| model | PreTrainedModel | 要训练的基础模型,通常是一个预训练的大型语言模型。 |
| train_dataset | Dataset | 训练数据集,通常是一个分词后的数据集,包含输入和输出对。 |
| eval_dataset | Dataset | 验证数据集,用于评估模型在训练过程中的性能。 |
| peft_config | PEFTConfig | 高效微调(Parameter Efficient Fine-Tuning)配置,用于指导微调策略。 |
| tokenizer | PreTrainedTokenizer | 用于分词的工具,将文本转换为模型可以理解的输入格式。 |
| args | TrainingArguments | 训练参数,包括批量大小、学习率、训练周期等。 |
| data_collator | DataCollator | 数据合并器,用于将多个样本合并成一个批次。 |
| callbacks list of | TrainerCallback | 训练过程中的回调函数,用于监控训练进度、记录指标等。 |
3.0 图形化指标展示
在2.9的代码片段中,定义了一个回调类(PlotLossCallback),用于记录训练过程指标,训练结束后,将以图形化方式展示:
class PlotLossCallback(TrainerCallback):
def __init__(self):
self.train_losses = []
self.eval_losses = []
self.step_count = 0
def on_log(self, args, state, control, logs=None, **kwargs):
self.step_count += 1
if logs is not None:
if 'loss' in logs:
self.train_losses.append(logs['loss'])
print(f"Step {self.step_count}, Training Loss: {logs['loss']}, Train Losses: {self.train_losses}")
if 'eval_loss' in logs:
self.eval_losses.append(logs['eval_loss'])
print(f"Step {self.step_count}, Validation Loss: {logs['eval_loss']}, Eval Losses: {self.eval_losses}")
def on_train_end(self, args, state, control, **kwargs):
print(f"Final Train Losses: {self.train_losses}")
print(f"Final Eval Losses: {self.eval_losses}")
if not self.train_losses:
print("Warning: No training losses recorded!")
if not self.eval_losses:
print("Warning: No validation losses recorded!")
plt.figure(figsize=(12, 6))
if self.train_losses:
plt.plot(self.train_losses, label='Training Loss')
if self.eval_losses:
plt.plot(self.eval_losses, label='Validation Loss')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.grid(True)
plt.ylim(0, 5)
plt.savefig('training_loss.png')
plt.show()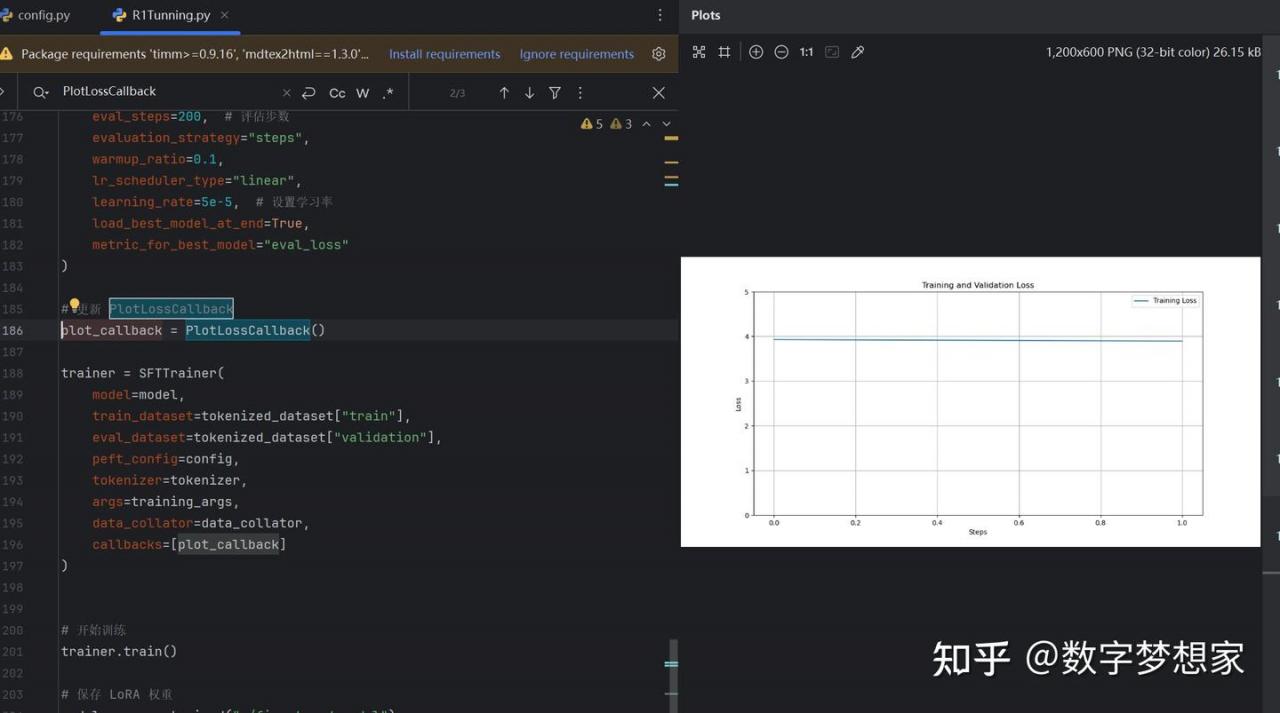
3.1 执行训练
到此为止,训练代码已经解析完毕,接下去你要做的,只需要点击运行代码,然后优雅地欣赏控制台输出的训练过程。
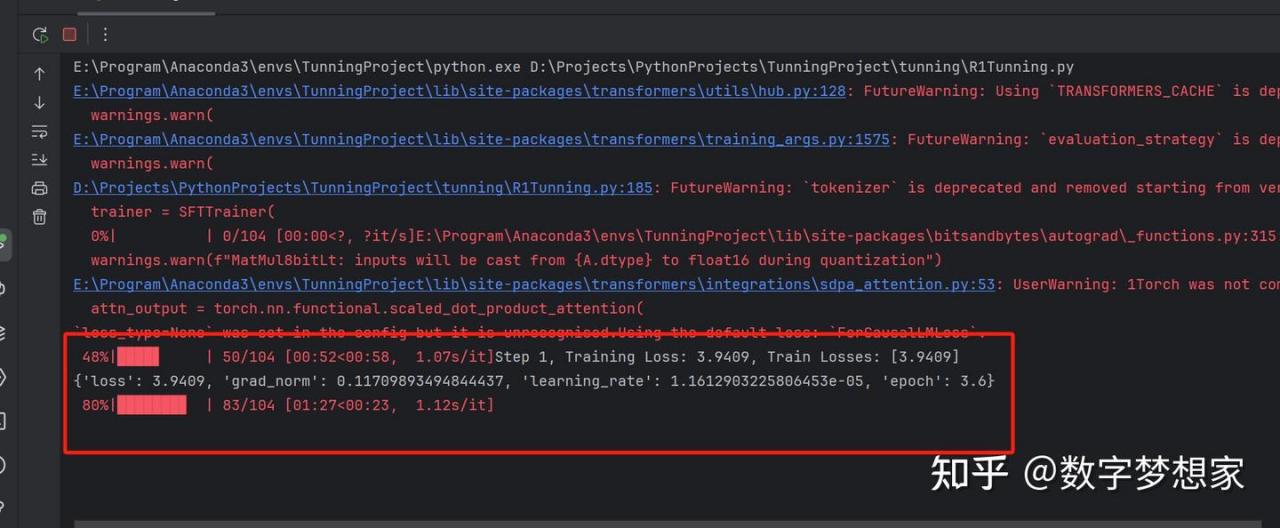
笔者机器配置是:8G显存,32G物理内存,最终2分钟就完成了训练; 我估计16G内存的机器训练时间也不会超过5分钟。
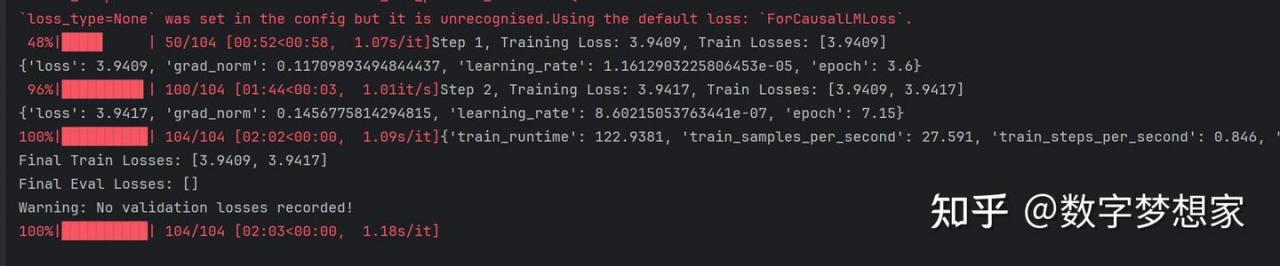
最后,你将看到类似的plot图形:
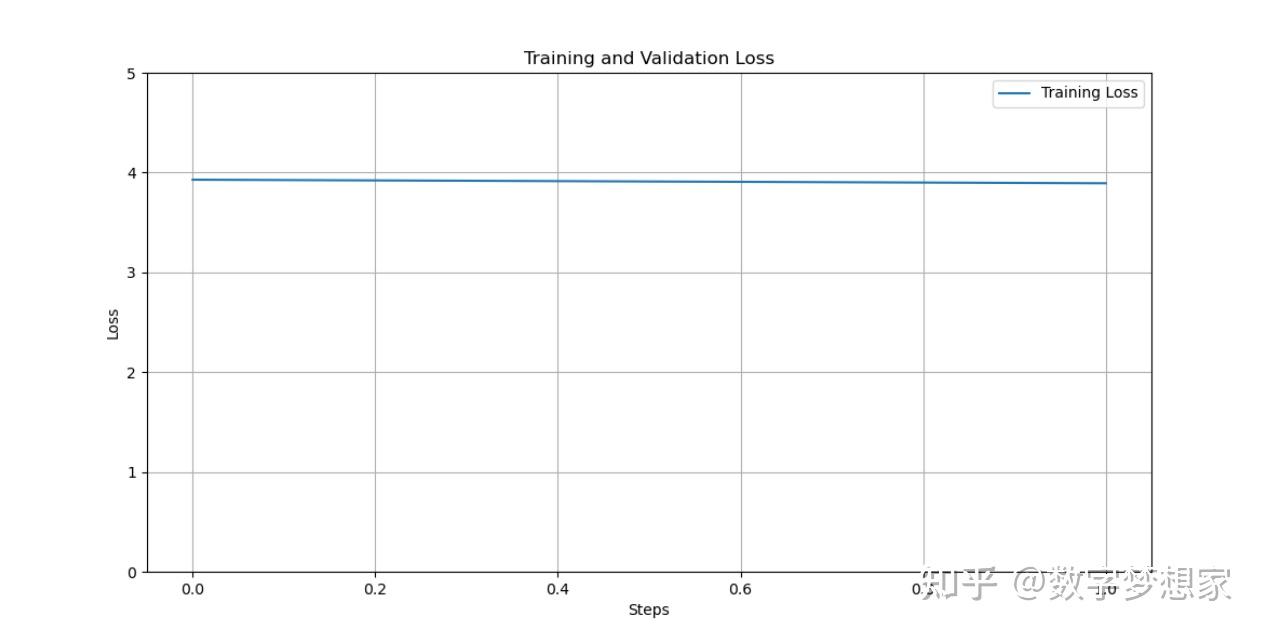
由于数据集过小且分布不均匀,训练步数也很少,导致training loss无法收敛。不过这已经不重要了,重要的是我们已经实现了大模型的全程微调。
好了,现在你已经借用一根树枝学会了六脉神剑的招式,那么换一把倚天剑,你还会忘记招式吗?
有任何问题,请评论区留言或点击咨询。
需要完整源码的请关注并在评论区留下邮箱地址。