如何使用python搭建个人量化平台(数据库建立更新,因子筛选检测)

写在前面
市面上的量化平台已经足够多,也足够强大。你可以在聚宽、RiceQuant、优矿上复制策略,可以拖动模块,就像孩子玩拼图一样组出一份看似精致的回测报告。
但你知道,那不属于你。
你看不见数据从哪里来,又往哪儿去;你无法理解黑盒里的逻辑,只能把自己的判断交付给他人设定好的流程,就像用别人的骨骼撑起自己的身体。
我们总归要有一套属于自己的“操作系统”。
它未必复杂,甚至可以简陋。但每一行代码都要你亲手敲下,每一次信号触发都要你心中有数。因为你不是为了炫技,也不是为了复制别人的成功——你是在用代码建立一座属于自己的市场认知结构,在这个疯狂世界里构建一块可以站稳的土地。
当行情剧烈波动,当回测结果不如人意,你至少能知道问题出在哪里。这说明,你写下的那段逻辑,需要再理解这个世界一次。
“真正的自由交易者,必须对自己的每一笔信号,负全部的责任。”
建立一个属于自己的量化平台,不是工程问题,而是认知问题、信念问题。
它是你和市场之间最私密的一种沟通方式,是你对抗噪音、误导与盲从的工具箱。更是一种提醒:在这个信息茧房越来越厚重的年代,唯有那些动手构建系统的人,才真正拥有理解世界的可能性。
1 准备工作
1.1 Python环境推荐:Anaconda,代码运行环境推荐:Jupyter Notebook
Anaconda集成了几乎所有常用的数据分析与科学计算库(如numpy、pandas、matplotlib、scikit-learn等),相信你一定有过配置本地环境疯狂报错让人崩溃的时候,而在Anaconda,这些环境已被集成为全家桶你不需要一个一个装,也不用担心依赖冲突。对初学者尤其友好,对未来扩展(如连接数据库、爬虫、机器学习)也足够强大。而Jupyter Notebook是我们运行代码的阵地,当然你可以选择其他你喜欢的IDE。
Anaconda官网:https://www.anaconda.com/
下载完成后,直接打开Jupyter Notebook书写代码

1.2 数据存储系统:MySQL(数据库管理)+MySQL Workbench(可视化工具)
Excel 或 CSV 文件当然可以用,甚至你一开始可能会觉得操作更方便。但随着数据体量扩大(比如你想储存 10 年全市场日线数据 + 财务报表 + 多因子数据),你会发现这些轻量格式根本撑不起你的研究系统。
官网:https://dev.mysql.com/downloads/

windows系统选择左侧下方最后一个,mac系统选择MySQL Community Server,进入后选择匹配芯片的版本下载,下载MySQL后下载左侧下方倒数第二个的MySQL Workbench作为可视化操作页面。
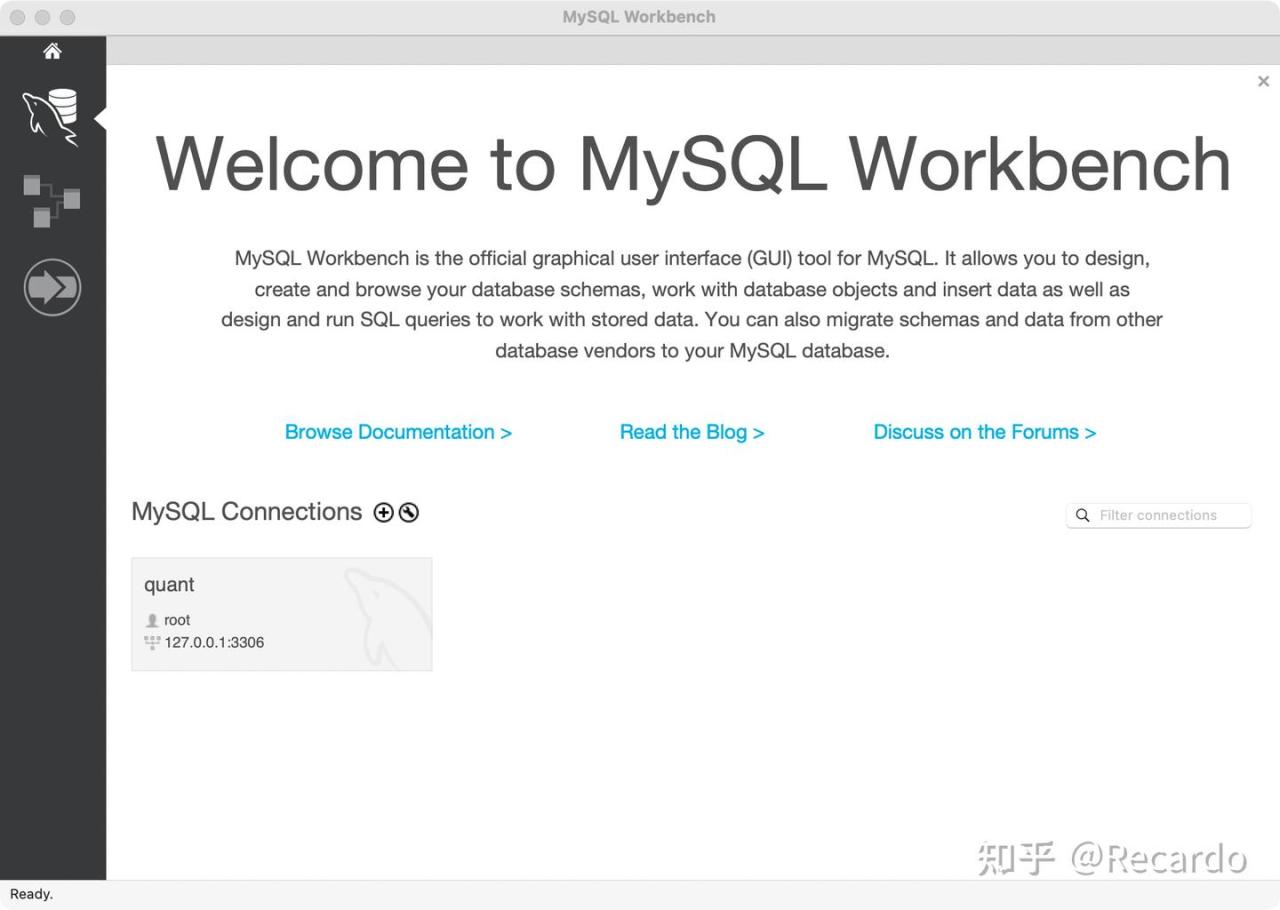
打开Workbench后新建一个Connections,点击加号键,输入名称后进入下一步,设置密码(一定要记住),进入之后新建一个Schema,随意命名,我在这里把Schema命名为wokers(其实是我拼错了,但是我不想改了)。
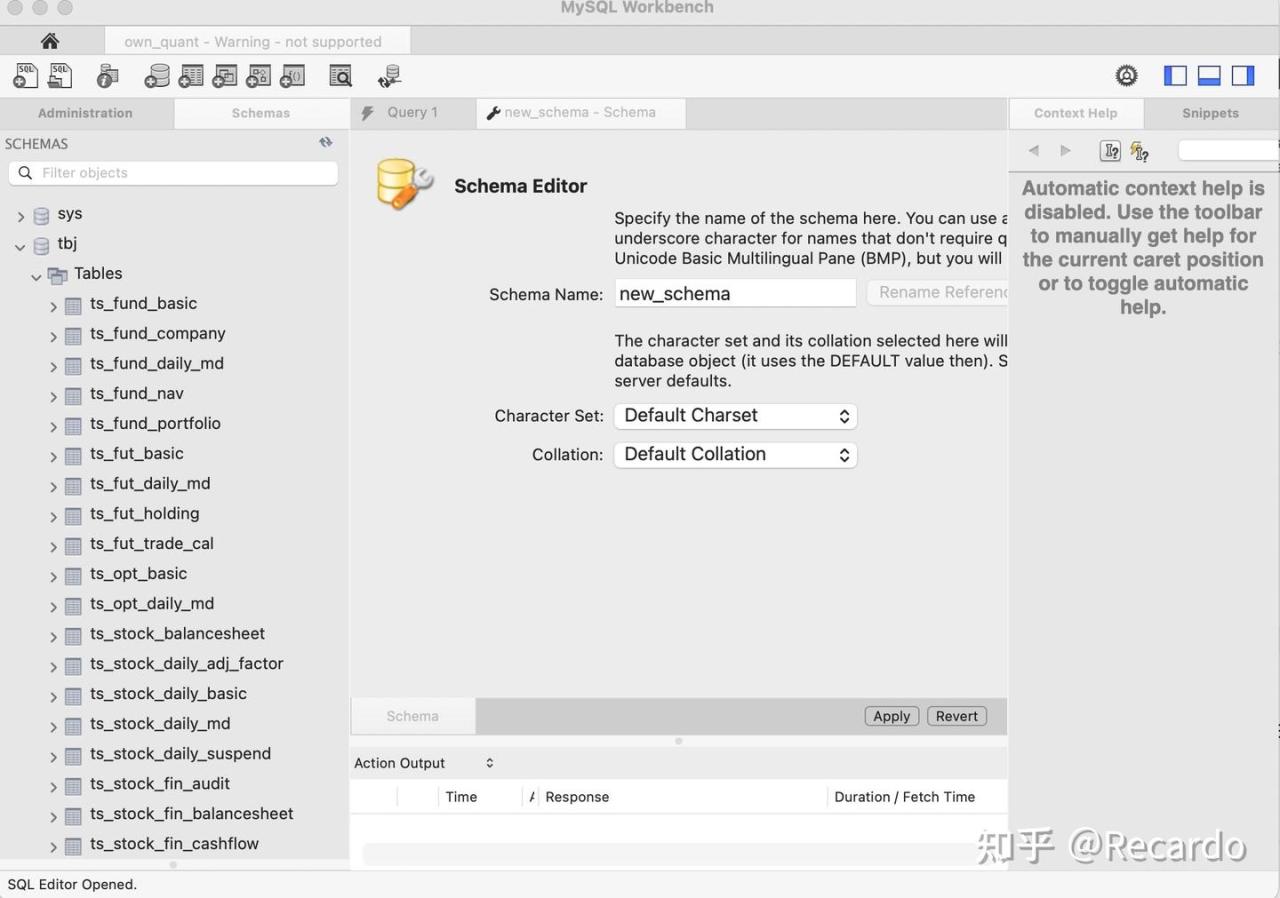
创建成功后出现新的库wokers,Tables就是我们用来存储历史价格数据表的地方
读到这里,你已经完成了所有基础设置,下一步我们将开始书写python代码构建数据库
2 数据库
2.1数据爬取
我们先使用以下代码爬取比特币的所有我们需要的数据进行研究,包括“日期”,“价格”,“成交量”,并形成EXCEL保存在本地。我们采用币安的API来进行数据获取。
import os
import time
import requests
import pandas as pd
from datetime import datetime, timedelta
# 1. 准备参数:每日 K 线、符号 BTCUSDT
symbol = "BTCUSDT"
interval = "1d"
# 10 年前起始日期
end_dt = datetime.utcnow()
start_dt = end_dt - timedelta(days=3650)
# 转换为毫秒级 Unix 时间戳
start_ts = int(start_dt.timestamp() * 1000)
end_ts = int(end_dt.timestamp() * 1000)
# 2. 分页循环获取所有数据
all_klines = []
url = "https://api.binance.com/api/v3/klines"
# 每根 K 线周期(1 天)的毫秒数
one_day_ms = 24 * 60 * 60 * 1000
while start_ts < end_ts:
params = {
"symbol": symbol,
"interval": interval,
"startTime": start_ts,
"endTime": end_ts,
"limit": 1000
}
resp = requests.get(url, params=params)
resp.raise_for_status() # 若非 2xx 则抛出 HTTPError [oai_citation:5‡GeeksforGeeks](https://www.geeksforgeeks.org/python/response-raise_for_status-python-requests/?utm_source=chatgpt.com)
data = resp.json()
if not data:
break
all_klines.extend(data)
# 更新下一批请求的起始时间:最后一根 K 线的开盘时间 + 1 天
last_open = data[-1][0]
start_ts = last_open + one_day_ms
time.sleep(0.2) # 避免过于频繁请求
# 3. 构建 DataFrame:提取日期、收盘价、成交量
df = pd.DataFrame(all_klines, columns=[
"open_time", "open", "high", "low", "close", "volume",
"close_time", "quote_asset_volume", "num_trades",
"taker_buy_base","taker_buy_quote","ignore"
])
df["date"] = pd.to_datetime(df["open_time"], unit="ms").dt.date
df = df[["date", "close", "volume"]]
df.columns = ["date", "price", "volume"]
# 4. 确保输出目录存在,并写入 Excel
output_dir = "/Users/wenkaiqi/Desktop/practice"
os.makedirs(output_dir, exist_ok=True)
output_path = os.path.join(output_dir, "bitcoin_10yr.xlsx")
df.to_excel(output_path, index=False) # 默认使用 openpyxl 引擎 [oai_citation:6‡GitHub](https://github.com/ranaroussi/yfinance/issues/2289?utm_source=chatgpt.com)
print(f"已保存 {len(df)} 条记录至:{output_path}")提示:如果你没有编程基础,运行代码时可能会遇到一些报错。
最常见的原因,是你还没有安装我们代码中用到的库。比如 pandas 这样的依赖项。这里我就不展开讲怎么安装了——
如果你遇到问题,只需要把报错信息复制下来,丢给 DeepSeek、ChatGPT 或者百度,搜索“怎么安装这个库”,大多数问题都能轻松解决。
运行代码后,你会看到这样一个效果图:
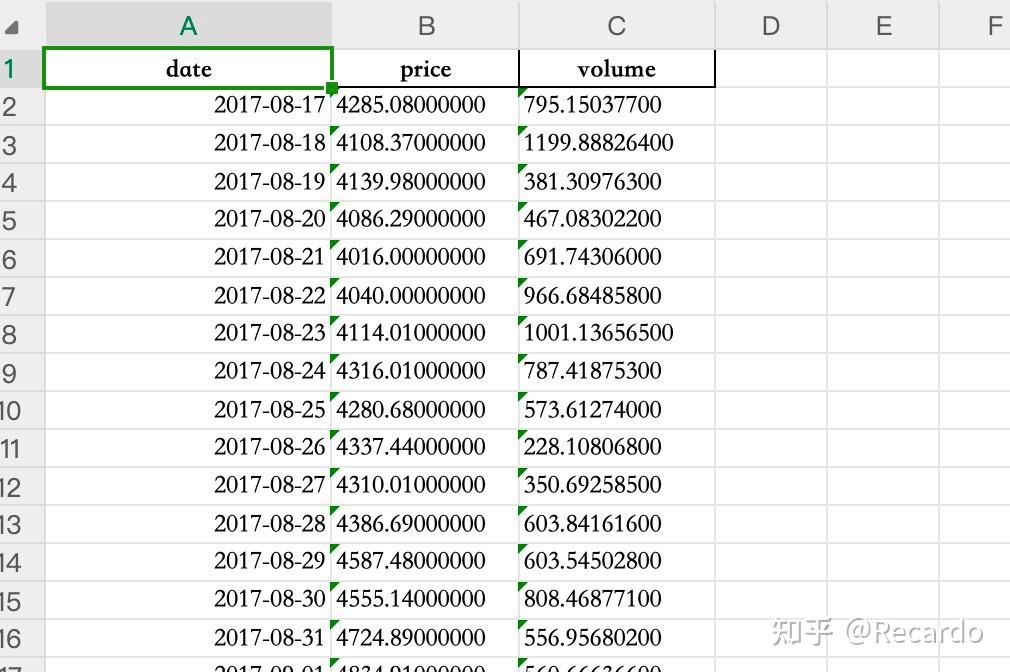
由于币安从 2017 年才开始提供比特币的历史数据,所以我们这张表的起始数据也从 2017 年开始,一直到今天。
从实务角度讲,无论是做因子挖掘还是进行回测研究,我们一般都希望有 10 年左右的历史数据,以保证模型有足够的样本去检验稳定性。但在这份教学中,我们选取的是近 8 年的数据,已足够支持教学用途和基础建模。
等你自己动手跑起来,你就会意识到:哪怕只是处理8年数据,背后也藏着数据清洗、结构设计、异常识别等一整套交易研究的入门功课。而这,也是你走向独立研究者的重要一步。
2.2与数据库建立通讯
与数据库建立通讯是我们对数据库进行读写操作的重要一步,我们通过以下代码完成。
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine(
"mysql+mysqlconnector://root:你的数据库密码@localhost:3306/你的数据库名称"
echo=False
)从engine开始的一行是核心:创建一个数据库引擎对象 engine,让你和 MySQL 连上线。我们来拆开解释:
- “mysql+mysqlconnector://”:告诉 SQLAlchemy库,我们使用 MySQL 数据库,并用 mysql-connector 这个驱动库来连接。
- root:是数据库的用户名,默认是 root(超级管理员)
- 你的数据库密码:你在安装 MySQL 时设置的密码
- localhost:3306:数据库地址是本地机器(localhost),端口号是 3306(MySQL 默认端口)
- /你的数据库名称:你要连接的数据库名,比如我们之前创建的wokers
- echo=False:这个参数表示是否输出 SQL 执行日志,设置为 False 代表你不需要看每次的 SQL 语句。如果你在调试时想看到 SQL 被怎么执行的,可以改为 echo=True
整体来看,这段代码的作用是:创建了一个可以和你 MySQL 数据库进行交互的“引擎对象”,未来你可以用这个 engine 去做查询、写入、建表等操作,完全不用写原生 SQL。
2.3数据库的写入操作
我们使用以下代码在数据库中创建一张新表并存入价格数据,之后查看是否保存成功
df=pd.read_excel("/Users/wenkaiqi/Desktop/practice/bitcoin_price.xlsx",engine="openpyxl")
#这行代码使用 pandas 读取本地的 Excel 文件,并将其加载为一个 DataFrame。
指定 engine="openpyxl" 是因为 pandas 读取 .xlsx 文件需要依赖 openpyxl 引擎。
table_name="BTC_data"
df[["date","price","volume"]].to_sql(name=table_name,con=engine,if_exists="replace",index=False)
“”“
这一行是核心操作:
只选取了 date、price 和 volume 三列;
通过 to_sql 方法将其写入数据库;
if_exists="replace" 表示如果表已经存在,就先删除再创建;
index=False 表示不将 DataFrame 的索引一并写入数据库。
”“”
成功运行后结果如下:
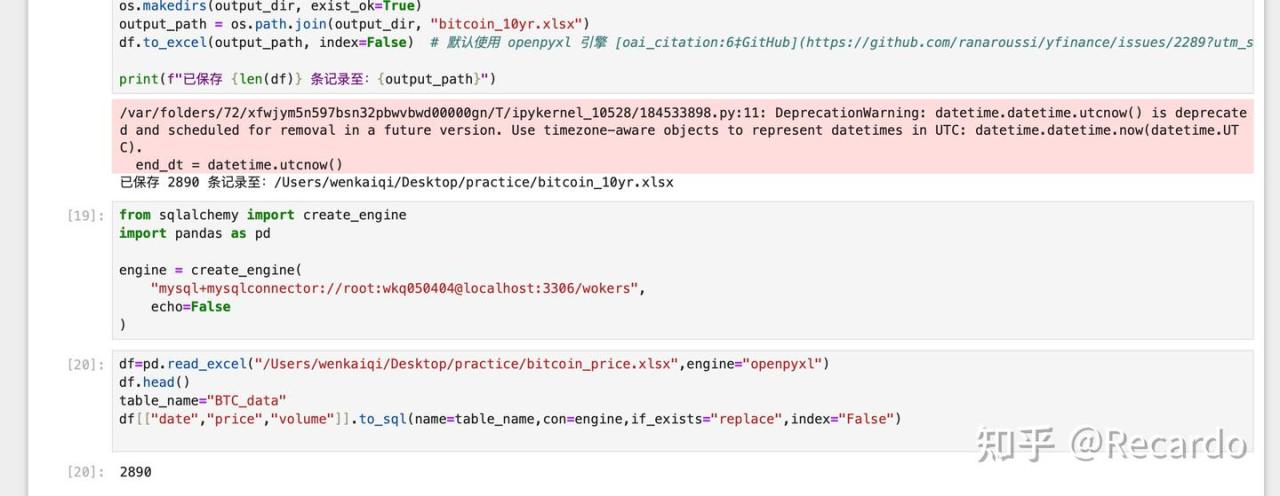
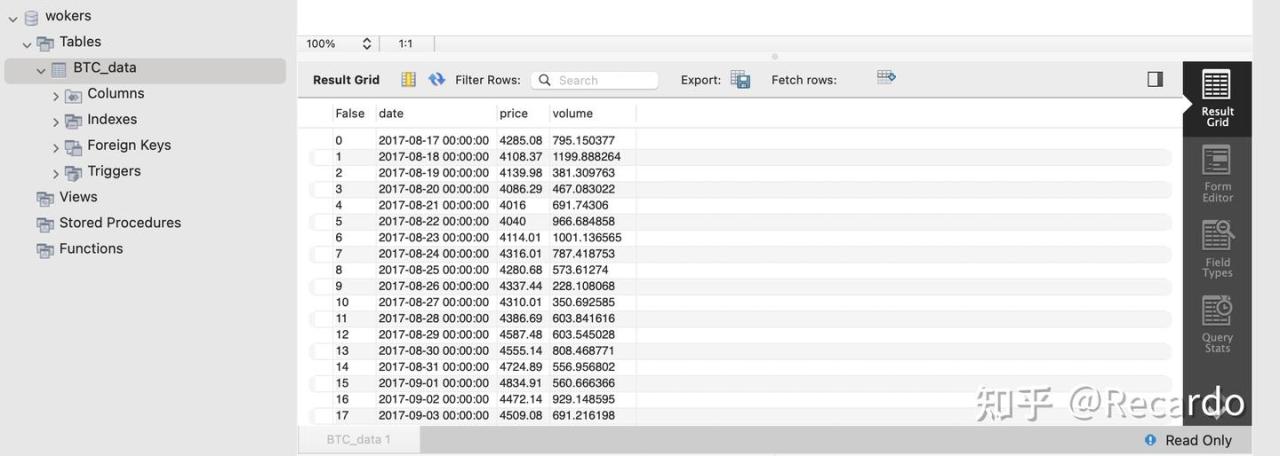
可以看到,我们成功写入了 2890 行数据,数据库中也新增了名为 BTC_data 的数据表。
2.4数据库的读取操作
完成数据写入后,我们可以通过 pandas 提供的 read_sql() 方法,从数据库中读取数据表,并将其加载为 DataFrame 进行分析或可视化。
data_df=pd.read_sql(table_name,con=engine)
data_df.head()- table_name:是我们之前写入数据库的表名(如 “BTC_data”),在这里我们传入的table_name是一个变量,因为我们之前已经把BTC_data传入了table_name;
- engine:是数据库的连接对象;
- 这样写的效果等同于执行 “SELECT * FROM BTC_data”,但更简单、更易读;
- 最后一行 data_df.head() 可以用来预览我们刚刚从数据库读取出来的数据。
相比使用 SQL 语句,我们也可以将整张表读取为一个 DataFrame,然后借助 pandas 的强大功能完成筛选、排序、条件查询等所有操作。这种方式不仅更灵活,也更加适合初学者。但本教程不涉及到更多复杂功能
代码运行结果如下:
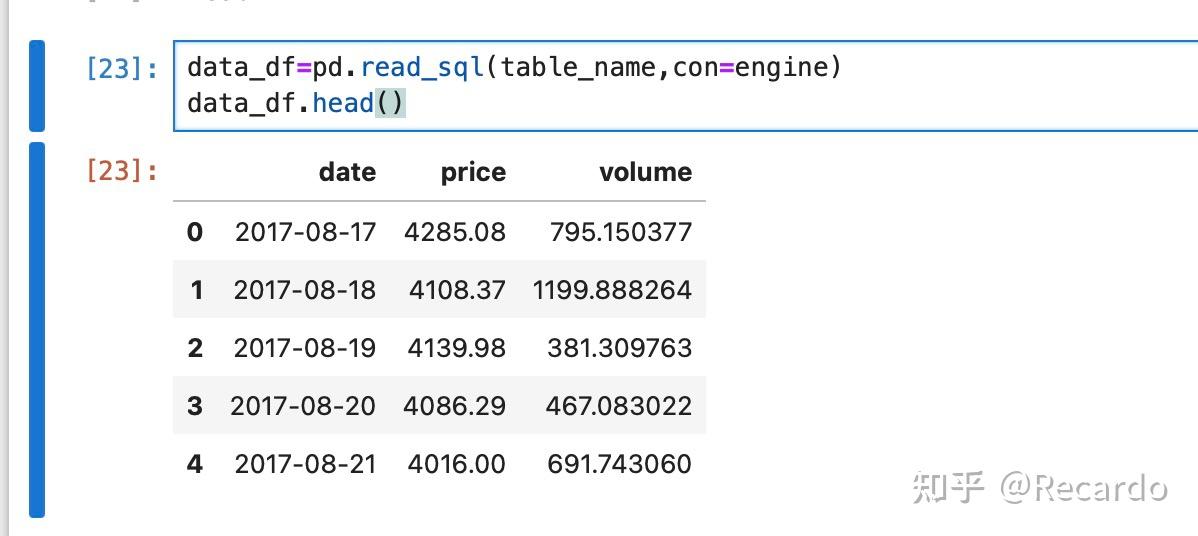
可以看到我们成功完成了读取操作,这说明我们成功地实现了从数据库存储数据到读取数据的完整闭环。
3 因子筛选与检测
3.1因子构建
趋势的声音,往往藏在成交量的脚步里。我们用 pandas 实现了两个经典因子:OBV 与 PVT,通过标准化融合成一个“量价因子”。它就像一个风向标,在价格的起伏中捕捉隐藏的动能,提醒我们趋势的强弱与潜在的转折点。操作体现了我们对于市场的研究从K线图转变到了因子,而这正是成为量化投资者的重要一步。
我们先对这两个经典因子做出简单介绍:
OBV 是最早被提出的量价指标之一。它的核心思想是:
- 当价格上涨:把当天的成交量加入累积总量;
- 当价格下跌:把当天的成交量从累积中减去;
- 最终形成一条随着趋势“跳动”的累积线。
作用:
- OBV 上升,说明资金正在持续流入;
- OBV 下降,说明资金可能在悄悄撤退;
- 若价格在涨,但 OBV 不动,可能是“假突破”。
相对于OBV只考虑涨或跌,PVT则更加细腻,它在每一天都考虑了涨跌的幅度:
公式大致是:
PVTn=PVTn−1+Volumen×Pricen−Pricen−1Pricen−1
也就是说,PVT 会用涨跌的比例 × 成交量,来衡量“今天这根K线到底有多有力”。
作用:
- PVT 既反映方向(上涨或下跌),又反映力度(涨跌幅 × 成交量);
- 更适合捕捉趋势强弱和行情背离。
PVT 是“更聪明版的 OBV”,会考虑“涨得多还是涨得少”。
接下来我们书写代码在python中表达OBV与PVT,代码如下
df = data_df.copy()
# 构建 OBV(On-Balance Volume)
df["price_diff"] = df["price"].diff()
df["direction"] = df["price_diff"].apply(lambda x: 1 if x > 0 else (-1 if x < 0 else 0))
df["obv_delta"] = df["volume"] * df["direction"]
df["OBV"] = df["obv_delta"].cumsum()
# 构建 PVT(Price-Volume Trend)
df["return"] = df["price"].pct_change()
df["pvt_delta"] = df["volume"] * df["return"]
df["PVT"] = df["pvt_delta"].cumsum()
# 保留最终结果
factor_df = df[["date", "price", "volume", "OBV", "PVT"]]
factor_df.head()运行后你会得到如下的DataFrame:
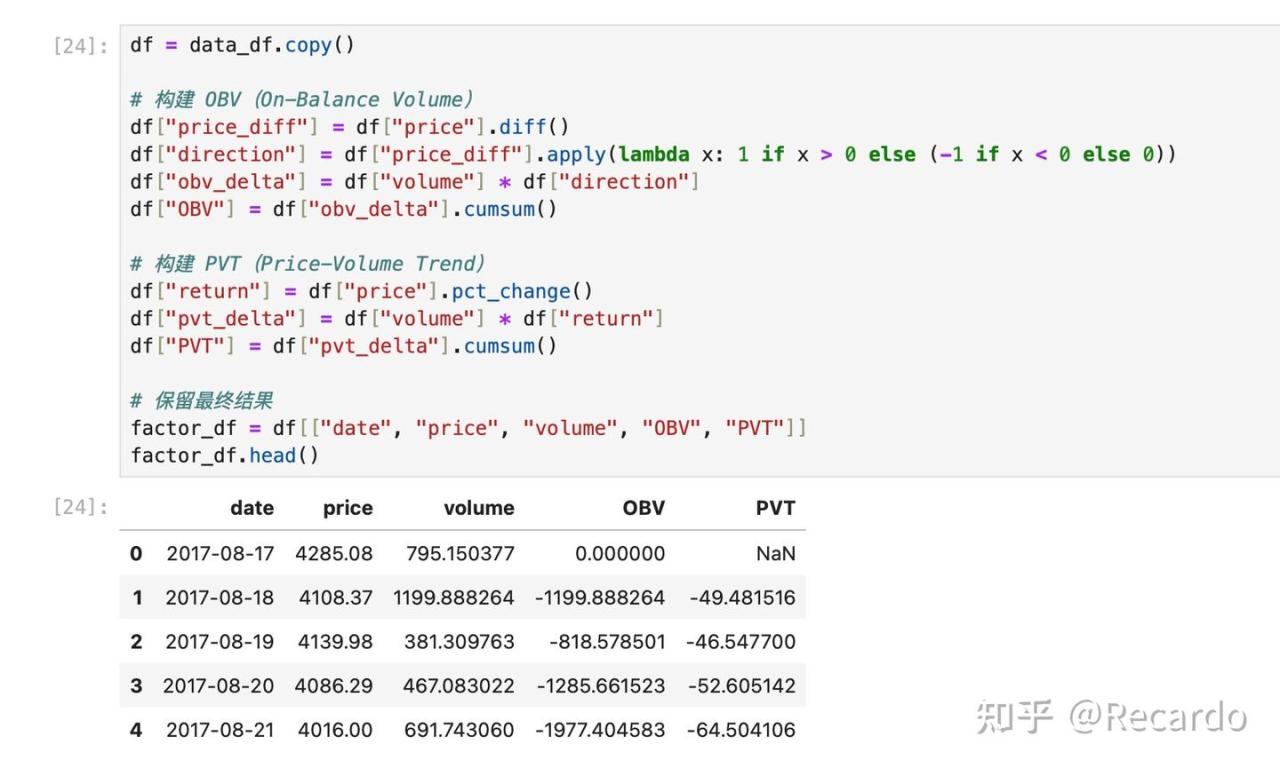
然后我们分别进行标准化并融合构建新的量价因子,代码如下:
from scipy.stats import zscore
# 标准化 OBV 与 PVT
factor_df["OBV_z"] = zscore(factor_df["OBV"].fillna(0))
factor_df["PVT_z"] = zscore(factor_df["PVT"].fillna(0))
# 构建融合后的综合量价因子
factor_df["Volume_Price_Factor"] = factor_df["OBV_z"] + factor_df["PVT_z"]
# 展示结果
factor_df[["date", "OBV_z", "PVT_z", "Volume_Price_Factor"]].tail()运行结果如下:
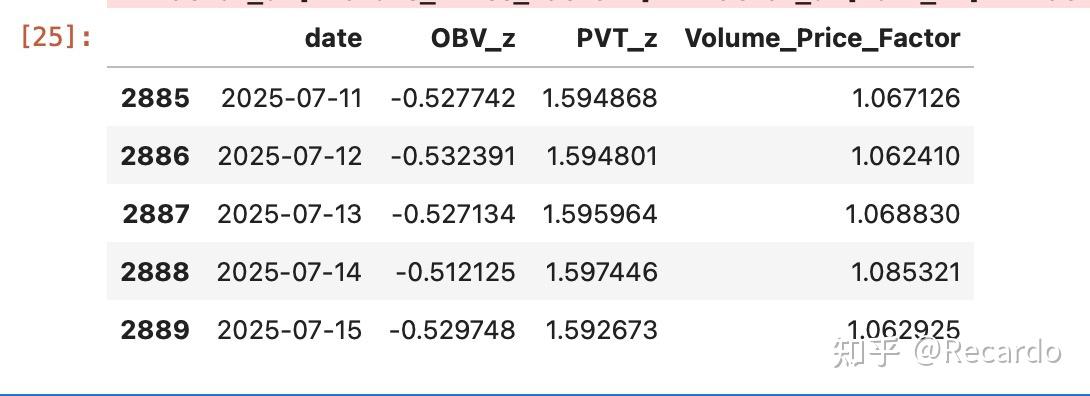
在构建综合因子前,我们需要先对 OBV 和 PVT 进行标准化处理,让它们具备相同的尺度,否则直接相加会出现偏倚,比如哪一项波动特别大,就会主导因子结果。我们使用了最常见的 Z-score 标准化方法。
OBV 和 PVT 虽然都是“量价指标”,但它们的数值范围完全不同,一个可能在几百万,一个可能是小数点后几位。如果你不标准化,直接相加,就像把“身高+体重”当作一个人的综合健康分数——没意义。
通过 zscore 处理后,每个指标会变成:
- 平均值为 0;
- 标准差为 1;
- 保留波动信息,但去掉量纲。
这样我们就能公平地合并它们,构成一个新的复合因子 Volume_Price_Factor,用于后续趋势判断、选股、打分或图像分析。
3.2因子检测
在这里我们向大家郑重介绍Alphalens这个库。
Alphalens 是一款 Python 的工具包,是 Quantopian 公司旗下三大开源包之一,另外两个分别是 Zipline 和 Pyfolio。Alphalens 因其简单易用而又稳定科学的优势被广泛的量化分析师所青睐。本文主要介绍 Alphalens 的回测框架。
在进行 Alphalens 的使用之前,需要先对先对数据进行清洗。事前需要准备好因子数据、价格数据和行业分组数据。其中因子数据需要处理成 Dataframe 格式,且其索引必须是二维日期和股票;价格数据是列为时间,行为股票的 Dataframe;行业数据可有可无,若有则可以设成 Dict 格式或者 Series 格式。然后通过 Alphalens 的get_clean_factor_and_forward_returns 函数对原始数据进行清洗,清洗之后返回股票、未来收益率和行业分类的因子数据 factor_data,然调用 create_full_tear_sheet 进行回测。但是需要注意的是,这是针对多资产进行检测的库,我们只有单一资产,我们通过虚构8个资产的方式来向大家展示Alhalens的强大之处,再往后我们会向大家说明如何进行单一资产的因子检测。
先来介绍最主要的两个函数
1.get_clean_factor_and_forward_returns()
功能
将你的因子值和价格数据整合并清洗为 Alphalens 可用的标准格式,包含:
- 对齐因素与价格;
- 计算未来收益(如未来 1、5、10 天);
- 根据 quantiles 或 bins 分组;
- 自动剔除缺失值或分组失败的数据。
常用参数
- factor: 带 (date, asset) 双索引的 Series
- prices: 日期为索引、资产为列的价格 DataFrame
- quantiles 或 bins: 决定如何分组
- periods: 指定未来 n 天收益,如 (1,5,10)
- max_loss: 容忍最大数据丢弃比例,默认为 0.35
2. 绘图与回测函数
create_full_tear_sheet(factor_data, …)
综合型回测图表一次性出炉:
- 分组表现图;
- 信息系数(IC)统计;
- 换手率;
- 因子分布等。
常用参数
- long_short: 是否做多空组合
- group_neutral: 是否按行业/组中性化处理
- by_group: 是否分组显示
示例代码如下:
import pandas as pd
import alphalens as al
import numpy as np
# 预处理:创建虚拟多资产数据以满足Alphalens横截面分析需求
def create_demo_multi_asset_data(factor_df, price_df, window=20, n_assets=8):
demo_factor_data = []
for i in range(window, len(factor_df)):
current_date = factor_df.iloc[i]['date']
for asset_id in range(n_assets):
lag_factor = factor_df.iloc[i - asset_id]['Volume_Price_Factor']
demo_factor_data.append({
'date': current_date,
'asset': f'BTC_Virtual_{asset_id}',
'factor': lag_factor
})
return pd.DataFrame(demo_factor_data)
# 创建虚拟多资产数据
demo_factor_df = create_demo_multi_asset_data(factor_df, df, window=30, n_assets=8)
# 1. 创建 factor:使用虚拟多资产数据
factor = demo_factor_df.set_index(["date", "asset"])["factor"]
# 2. 创建 prices:为每个虚拟资产复制BTC价格
price_data = df[df['date'].isin(demo_factor_df['date'].unique())][["date", "price"]].copy()
price_data.set_index("date", inplace=True)
prices = pd.DataFrame(index=price_data.index)
for asset_id in range(8):
noise = np.random.normal(1, 0.001, len(price_data))
prices[f'BTC_Virtual_{asset_id}'] = price_data['price'] * noise
# 3. 使用 Alphalens 做因子检测
factor_data = al.utils.get_clean_factor_and_forward_returns(
factor=factor,
prices=prices,
quantiles=None,
bins=4,
periods=(1,5,10),
max_loss=0.35
)
# 4. 绘制 Tear Sheet
al.tears.create_full_tear_sheet(factor_data)运行结果你会得到几张图表,我们就收益图与IC分析展开说明:
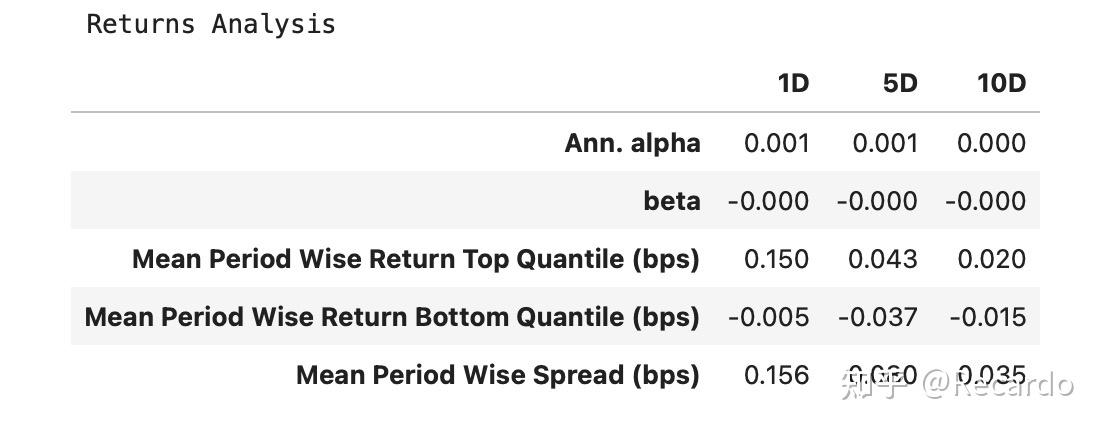
这是 分组收益分析,按 1日(1D)/5日(5D)/10日(10D) 的持有期分别展示了因子排序的表现。单位是 bps(基点),即 0.01%。
- 横轴(列)表示不同的持有期(如 1D、5D、10D),对应的是把信号持有 1 天、5 天或 10 天的收益情况。
- 纵轴(行)展示了不同的指标类型,用于衡量因子的收益能力和风险特征:
- Ann. alpha:表示年化的超额收益率,是因子多空组合长期表现的估计值。
- beta:衡量因子组合相对于市场波动的敏感度,用于评估风险暴露情况。
- Mean Period Wise Return Top Quantile:每期中因子值最高的一组资产的平均收益。
- Mean Period Wise Return Bottom Quantile:每期中因子值最低的一组资产的平均收益。
- Mean Period Wise Spread:高低分组之间的收益差,代表该因子排序的收益分层能力。
使用方法:
- 通过比较“Top Quantile”和“Bottom Quantile”的差异,可以判断该因子是否有效区分了表现好的和表现差的资产。
- 若“Spread”在多个周期上为正且稳定,说明该因子具有较强的预测能力。
- “Ann. alpha”和“beta”可以帮助判断因子是否适合用于构建市场中性策略
该表适用于快速判断一个因子在不同持有期下的收益特征,是因子有效性分析中的核心输出。
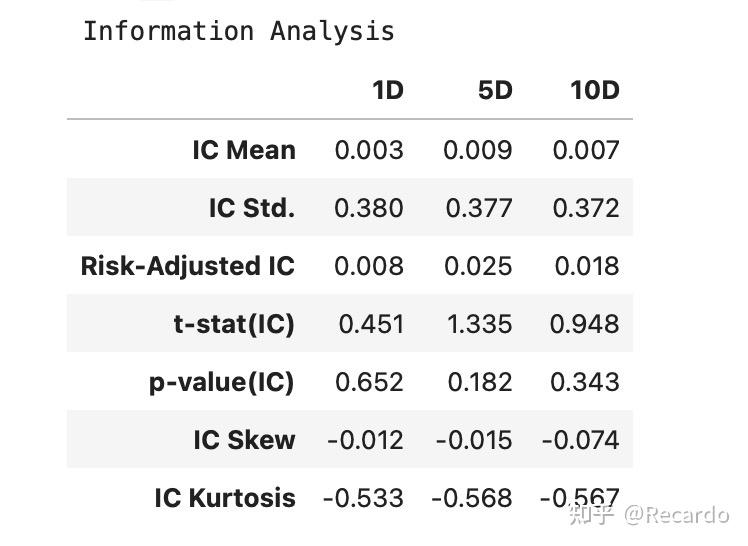
如何阅读 Alphalens 的 Information Analysis 表格
这张表格展示的是因子与未来收益之间的秩相关性(Rank IC)分析结果,是衡量因子预测能力的关键部分。
表格的横轴依然是不同的持有期(1D、5D、10D),纵轴则包含了多个信息系数相关指标,具体含义如下:
- IC Mean:信息系数(Information Coefficient)的均值,衡量因子排序与未来收益排序的一致程度。经验判断标准:当 IC Mean 稳定高于 0.03 时,通常视为该因子具备一定预测力。
- IC Std.:IC 的标准差,反映预测能力的波动性。
- Risk-Adjusted IC:IC Mean 除以 IC Std.,也就是“IC 的信息比率”,表示单位波动下的预测能力。
- t-stat(IC):用于统计检验 IC 是否显著为正(或者为负),t 值越大,因子越显著。p-value(IC):p 值越小,
- 表示 IC 显著不为 0(即预测能力显著存在)。一般认为当 p 值 < 0.05 时,可以认为该因子的预测能力具有统计显著性。
- IC Skew:IC 分布的偏度,反映预测表现的不对称性。
- IC Kurtosis:IC 分布的峰度,衡量极端值的影响程度。
如何使用:
- 主要关注前三行:IC Mean、IC Std. 和 Risk-Adjusted IC。它们告诉你因子是否具有稳定的预测能力。
- 再看 t-stat 和 p-value,判断预测是否显著。
- Skew 和 Kurtosis 更多是用于了解因子在极端情况下的表现,适用于策略风险管理阶段。
这张图可以帮助你快速判断因子是否有“排序能力”,适合用于动量、反转等策略的前期筛选和评估。